 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Space Exploration of Embedded SoC Architectures for Real-Time Optimal Control
Oct 16, 2024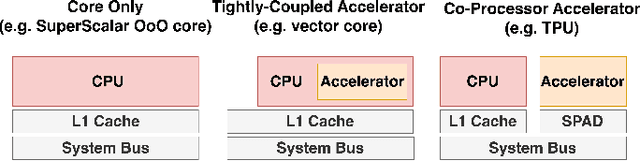
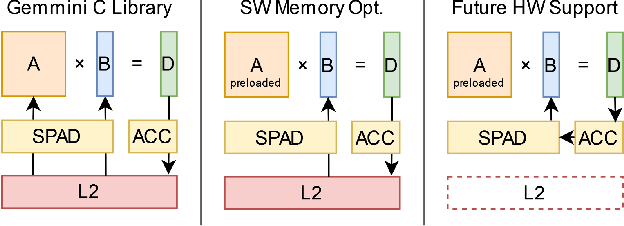
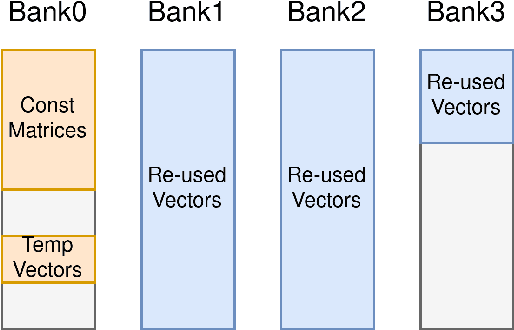
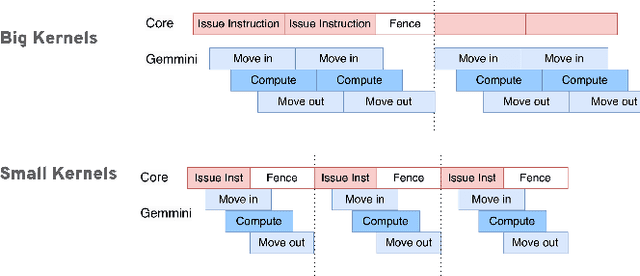
Empowering resource-limited robots to execute computationally intensive tasks like model/learning-based algorithms is challenging. Due to the complexity of the workload characteristic, the bottlenecks in different systems can depend on application requirements, preventing a single hardware architecture from being adequate across all robotics applications. This project provides a comprehensive design space exploration to determine optimal hardware computation platforms and architectures suitable for robotic algorithms. We profile and optimize representative architectural designs across general-purpose cores and specialized accelerators. Specifically, we compare CPUs, vector machines, and domain-specialized accelerators with kernel-level benchmarks and end-to-end representative robotic workloads. Our exploration provides a quantitative performance, area, and utilization comparison and analyzes the trade-offs between these representative distinct architectural designs. We demonstrate that the variation of hardware architecture choices depends on workload characteristics and application requirements. Finally, we explore how architectural modifications and software ecosystem optimization can alleviate bottlenecks and enhance utilization.
SparseTrain:Leveraging Dynamic Sparsity in Training DNNs on General-Purpose SIMD Processors
Nov 22, 2019
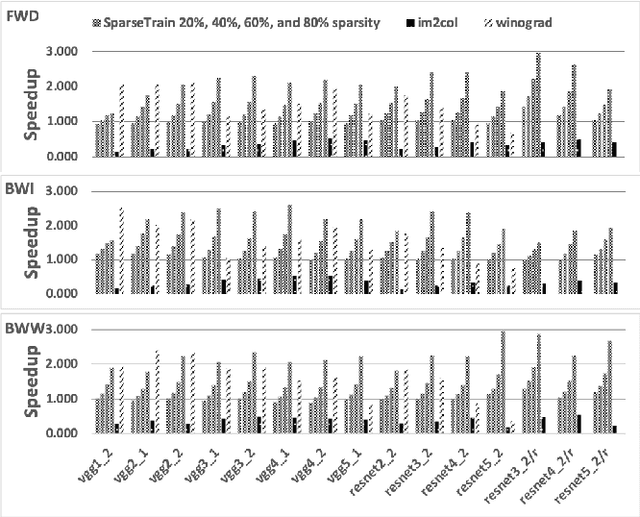
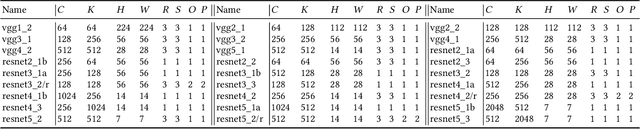
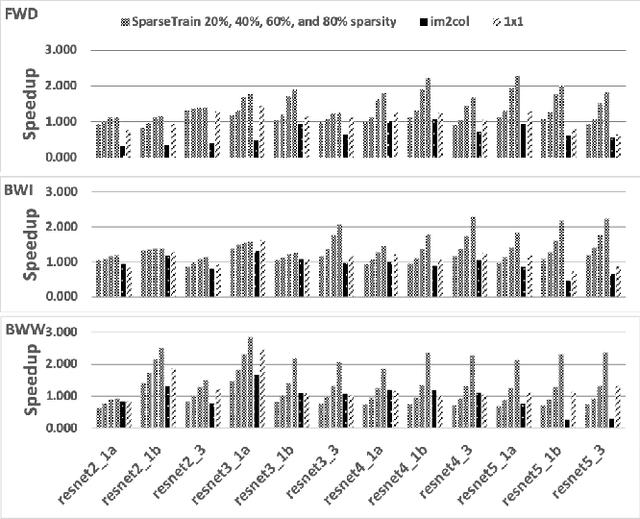
Our community has greatly improved the efficiency of deep learning applications, including by exploiting sparsity in inputs. Most of that work, though, is for inference, where weight sparsity is known statically, and/or for specialized hardware. We propose a scheme to leverage dynamic sparsity during training. In particular, we exploit zeros introduced by the ReLU activation function to both feature maps and their gradients. This is challenging because the sparsity degree is moderate and the locations of zeros change over time. We also rely purely on software. We identify zeros in a dense data representation without transforming the data and performs conventional vectorized computation. Variations of the scheme are applicable to all major components of training: forward propagation, backward propagation by inputs, and backward propagation by weights. Our method significantly outperforms a highly-optimized dense direct convolution on several popular deep neural networks. At realistic sparsity, we speed up the training of the non-initial convolutional layers in VGG16, ResNet-34, ResNet-50, and Fixup ResNet-50 by 2.19x, 1.37x, 1.31x, and 1.51x respectively on an Intel Skylake-X CPU.
Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures
Aug 14, 2018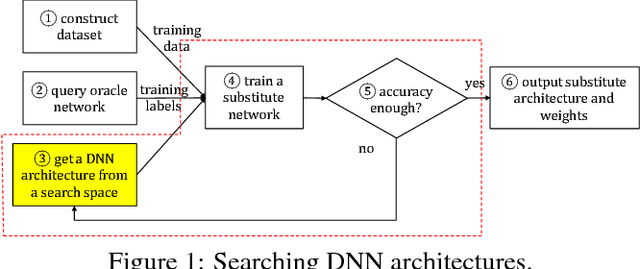


Deep Neural Networks (DNNs) are fast becoming ubiquitous for their ability to attain good accuracy in various machine learning tasks. A DNN's architecture (i.e., its hyper-parameters) broadly determines the DNN's accuracy and performance, and is often confidential. Attacking a DNN in the cloud to obtain its architecture can potentially provide major commercial value. Further, attaining a DNN's architecture facilitates other, existing DNN attacks. This paper presents Cache Telepathy: a fast and accurate mechanism to steal a DNN's architecture using the cache side channel. Our attack is based on the insight that DNN inference relies heavily on tiled GEMM (Generalized Matrix Multiply), and that DNN architecture parameters determine the number of GEMM calls and the dimensions of the matrices used in the GEMM functions. Such information can be leaked through the cache side channel. This paper uses Prime+Probe and Flush+Reload to attack VGG and ResNet DNNs running OpenBLAS and Intel MKL libraries. Our attack is effective in helping obtain the architectures by very substantially reducing the search space of target DNN architectures. For example, for VGG using OpenBLAS, it reduces the search space from more than $10^{35}$ architectures to just 16.