 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPAS: Thermal- and Power-Aware Scheduling for LLM Inference in Cloud Platforms
Jan 05, 2025



The rising demand for generative large language models (LLMs) poses challenges for thermal and power management in cloud datacenters. Traditional techniques often are inadequate for LLM inference due to the fine-grained, millisecond-scale execution phases, each with distinct performance, thermal, and power profiles. Additionally, LLM inference workloads are sensitive to various configuration parameters (e.g., model parallelism, size, and quantization) that involve trade-offs between performance, temperature, power, and output quality. Moreover, clouds often co-locate SaaS and IaaS workloads, each with different levels of visibility and flexibility. We propose TAPAS, a thermal- and power-aware framework designed for LLM inference clusters in the cloud. TAPAS enhances cooling and power oversubscription capabilities, reducing the total cost of ownership (TCO) while effectively handling emergencies (e.g., cooling and power failures). The system leverages historical temperature and power data, along with the adaptability of SaaS workloads, to: (1) efficiently place new GPU workload VMs within cooling and power constraints, (2) route LLM inference requests across SaaS VMs, and (3) reconfigure SaaS VMs to manage load spikes and emergency situations. Our evaluation on a large GPU cluster demonstrates significant reductions in thermal and power throttling events, boosting system efficiency.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency
Aug 01, 2024



The rapid evolution and widespread adoption of generative large language models (LLMs) have made them a pivotal workload in various applications. Today, LLM inference clusters receive a large number of queries with strict Service Level Objectives (SLOs). To achieve the desired performance, these models execute on power-hungry GPUs causing the inference clusters to consume large amount of energy and, consequently, result in excessive carbon emissions. Fortunately, we find that there is a great opportunity to exploit the heterogeneity in inference compute properties and fluctuations in inference workloads, to significantly improve energy-efficiency. However, such a diverse and dynamic environment creates a large search-space where different system configurations (e.g., number of instances, model parallelism, and GPU frequency) translate into different energy-performance trade-offs. To address these challenges, we propose DynamoLLM, the first energy-management framework for LLM inference environments. DynamoLLM automatically and dynamically reconfigures the inference cluster to optimize for energy and cost of LLM serving under the service's performance SLOs. We show that at a service-level, DynamoLLM conserves 53% energy and 38% operational carbon emissions, and reduces 61% cost to the customer, while meeting the latency SLOs.
Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference
Mar 29, 2024With the ubiquitous use of modern large language models (LLMs) across industries, the inference serving for these models is ever expanding. Given the high compute and memory requirements of modern LLMs, more and more top-of-the-line GPUs are being deployed to serve these models. Energy availability has come to the forefront as the biggest challenge for data center expansion to serve these models. In this paper, we present the trade-offs brought up by making energy efficiency the primary goal of LLM serving under performance SLOs. We show that depending on the inputs, the model, and the service-level agreements, there are several knobs available to the LLM inference provider to use for being energy efficient. We characterize the impact of these knobs on the latency, throughput, as well as the energy. By exploring these trade-offs, we offer valuable insights into optimizing energy usage without compromising on performance, thereby paving the way for sustainable and cost-effective LLM deployment in data center environments.
Input-sensitive dense-sparse primitive compositions for GNN acceleration
Jun 27, 2023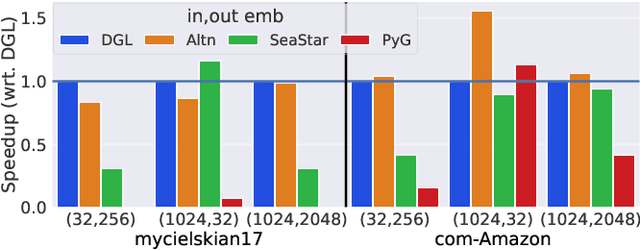
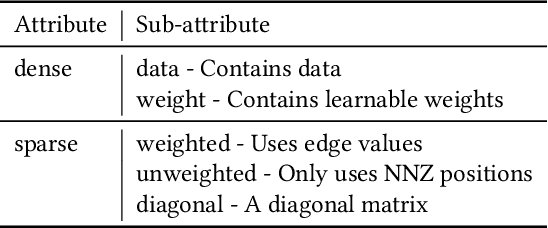
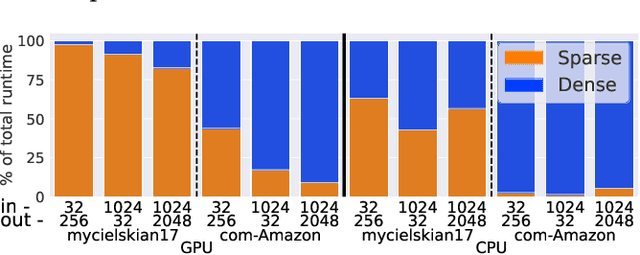
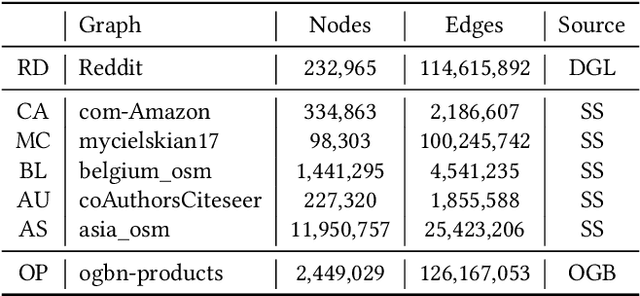
Graph neural networks (GNN) have become an important class of neural network models that have gained popularity in domains such as social and financial network analysis. Different phases of GNN computations can be modeled using both dense and sparse matrix operations. There have been many frameworks and optimization techniques proposed in the literature to accelerate GNNs. However, getting consistently high performance across many input graphs with different sparsity patterns and GNN embedding sizes has remained difficult. In this paper, we propose different algebraic reassociations of GNN computations that lead to novel dense and sparse matrix primitive selections and compositions. We show that the profitability of these compositions depends on the input graph, embedding size, and the target hardware. We developed SENSEi, a system that uses a data-driven adaptive strategy to select the best composition given the input graph and GNN embedding sizes. Our evaluations on a wide range of graphs and embedding sizes show that SENSEi achieves geomean speedups of $1.105\times$ (up to $2.959\times$) and $1.187\times$ (up to $1.99\times$) on graph convolutional networks and geomean speedups of $2.307\times$ (up to $35.866\times$) and $1.44\times$ (up to $5.69\times$) on graph attention networks on CPUs and GPUs respectively over the widely used Deep Graph Library. Further, we show that the compositions yield notable synergistic performance benefits on top of other established sparse optimizations such as sparse matrix tiling by evaluating against a well-tuned baseline.
Defensive ML: Defending Architectural Side-channels with Adversarial Obfuscation
Feb 03, 2023Side-channel attacks that use machine learning (ML) for signal analysis have become prominent threats to computer security, as ML models easily find patterns in signals. To address this problem, this paper explores using Adversarial Machine Learning (AML) methods as a defense at the computer architecture layer to obfuscate side channels. We call this approach Defensive ML, and the generator to obfuscate signals, defender. Defensive ML is a workflow to design, implement, train, and deploy defenders for different environments. First, we design a defender architecture given the physical characteristics and hardware constraints of the side-channel. Next, we use our DefenderGAN structure to train the defender. Finally, we apply defensive ML to thwart two side-channel attacks: one based on memory contention and the other on application power. The former uses a hardware defender with ns-level response time that attains a high level of security with half the performance impact of a traditional scheme; the latter uses a software defender with ms-level response time that provides better security than a traditional scheme with only 70% of its power overhead.
SparseTrain:Leveraging Dynamic Sparsity in Training DNNs on General-Purpose SIMD Processors
Nov 22, 2019
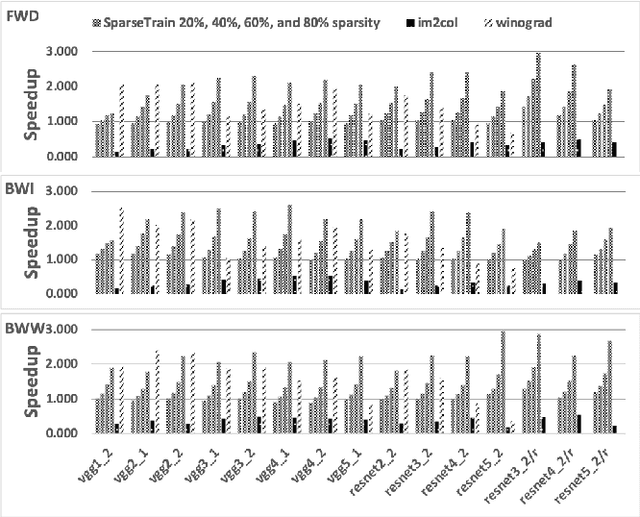
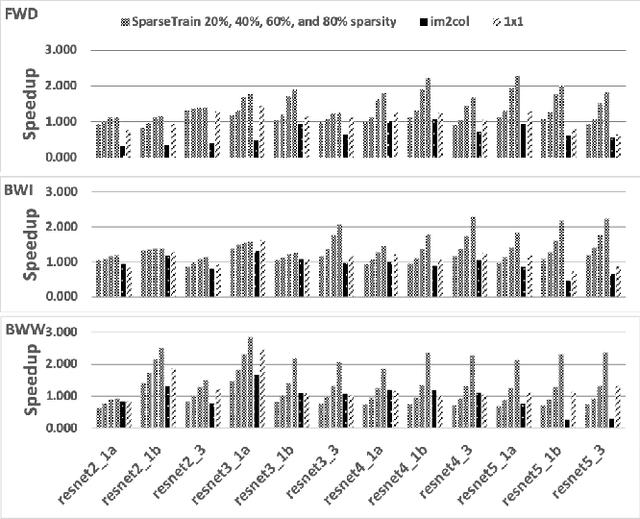
Our community has greatly improved the efficiency of deep learning applications, including by exploiting sparsity in inputs. Most of that work, though, is for inference, where weight sparsity is known statically, and/or for specialized hardware. We propose a scheme to leverage dynamic sparsity during training. In particular, we exploit zeros introduced by the ReLU activation function to both feature maps and their gradients. This is challenging because the sparsity degree is moderate and the locations of zeros change over time. We also rely purely on software. We identify zeros in a dense data representation without transforming the data and performs conventional vectorized computation. Variations of the scheme are applicable to all major components of training: forward propagation, backward propagation by inputs, and backward propagation by weights. Our method significantly outperforms a highly-optimized dense direct convolution on several popular deep neural networks. At realistic sparsity, we speed up the training of the non-initial convolutional layers in VGG16, ResNet-34, ResNet-50, and Fixup ResNet-50 by 2.19x, 1.37x, 1.31x, and 1.51x respectively on an Intel Skylake-X CPU.
Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures
Aug 14, 2018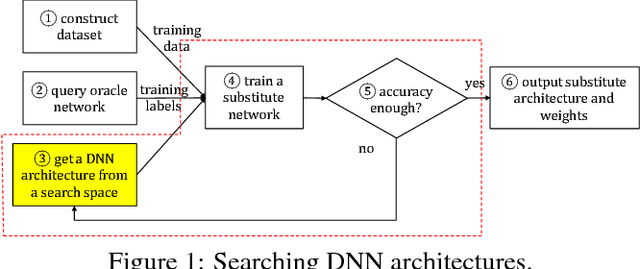


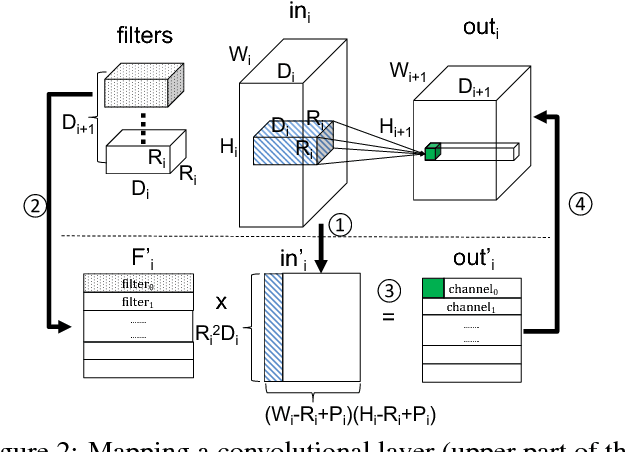
Deep Neural Networks (DNNs) are fast becoming ubiquitous for their ability to attain good accuracy in various machine learning tasks. A DNN's architecture (i.e., its hyper-parameters) broadly determines the DNN's accuracy and performance, and is often confidential. Attacking a DNN in the cloud to obtain its architecture can potentially provide major commercial value. Further, attaining a DNN's architecture facilitates other, existing DNN attacks. This paper presents Cache Telepathy: a fast and accurate mechanism to steal a DNN's architecture using the cache side channel. Our attack is based on the insight that DNN inference relies heavily on tiled GEMM (Generalized Matrix Multiply), and that DNN architecture parameters determine the number of GEMM calls and the dimensions of the matrices used in the GEMM functions. Such information can be leaked through the cache side channel. This paper uses Prime+Probe and Flush+Reload to attack VGG and ResNet DNNs running OpenBLAS and Intel MKL libraries. Our attack is effective in helping obtain the architectures by very substantially reducing the search space of target DNN architectures. For example, for VGG using OpenBLAS, it reduces the search space from more than $10^{35}$ architectures to just 16.