 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition
Oct 24, 2019

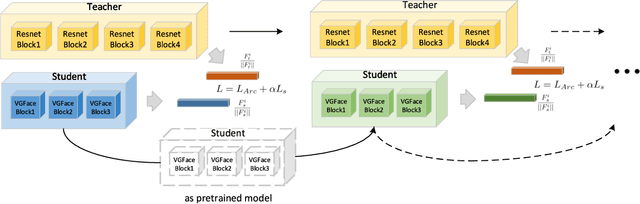

To improve the discriminative and generalization ability of lightweight network for face recognition, we propose an efficient variable group convolutional network called VarGFaceNet. Variable group convolution is introduced by VarGNet to solve the conflict between small computational cost and the unbalance of computational intensity inside a block. We employ variable group convolution to design our network which can support large scale face identification while reduce computational cost and parameters. Specifically, we use a head setting to reserve essential information at the start of the network and propose a particular embedding setting to reduce parameters of fully-connected layer for embedding. To enhance interpretation ability, we employ an equivalence of angular distillation loss to guide our lightweight network and we apply recursive knowledge distillation to relieve the discrepancy between the teacher model and the student model. The champion of deepglint-light track of LFR (2019) challenge demonstrates the effectiveness of our model and approach. Implementation of VarGFaceNet will be released at https://github.com/zma-c-137/VarGFaceNet soon.
Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures
Aug 14, 2018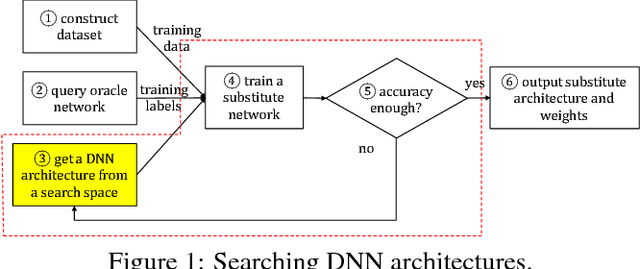


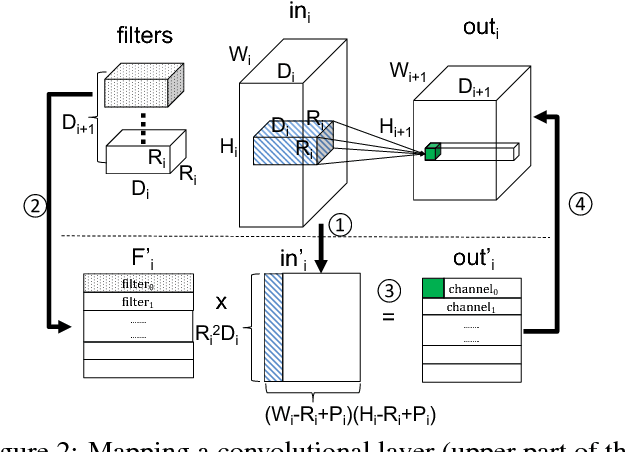
Deep Neural Networks (DNNs) are fast becoming ubiquitous for their ability to attain good accuracy in various machine learning tasks. A DNN's architecture (i.e., its hyper-parameters) broadly determines the DNN's accuracy and performance, and is often confidential. Attacking a DNN in the cloud to obtain its architecture can potentially provide major commercial value. Further, attaining a DNN's architecture facilitates other, existing DNN attacks. This paper presents Cache Telepathy: a fast and accurate mechanism to steal a DNN's architecture using the cache side channel. Our attack is based on the insight that DNN inference relies heavily on tiled GEMM (Generalized Matrix Multiply), and that DNN architecture parameters determine the number of GEMM calls and the dimensions of the matrices used in the GEMM functions. Such information can be leaked through the cache side channel. This paper uses Prime+Probe and Flush+Reload to attack VGG and ResNet DNNs running OpenBLAS and Intel MKL libraries. Our attack is effective in helping obtain the architectures by very substantially reducing the search space of target DNN architectures. For example, for VGG using OpenBLAS, it reduces the search space from more than $10^{35}$ architectures to just 16.
UCNN: Exploiting Computational Reuse in Deep Neural Networks via Weight Repetition
Apr 18, 2018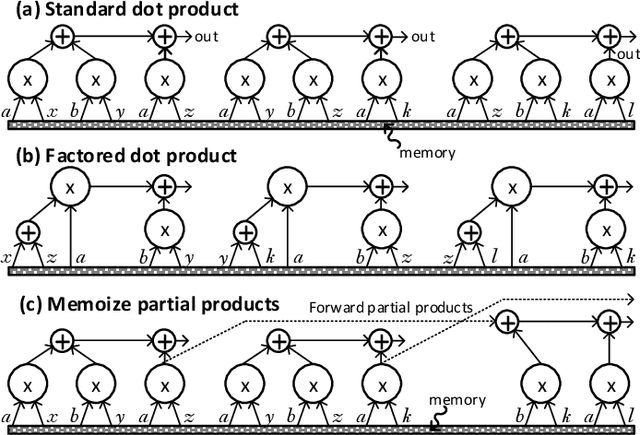
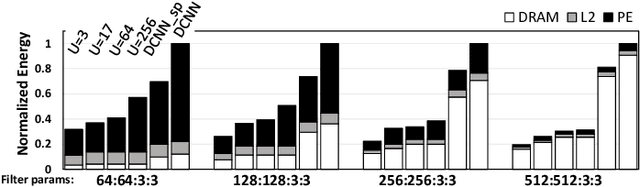
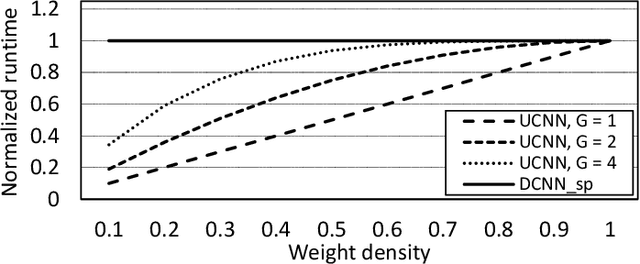
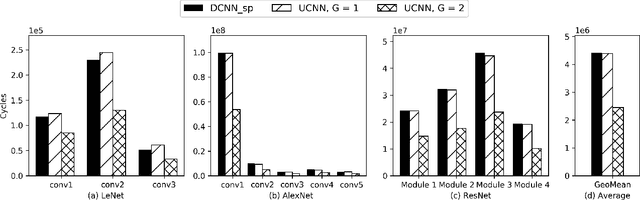
Convolutional Neural Networks (CNNs) have begun to permeate all corners of electronic society (from voice recognition to scene generation) due to their high accuracy and machine efficiency per operation. At their core, CNN computations are made up of multi-dimensional dot products between weight and input vectors. This paper studies how weight repetition ---when the same weight occurs multiple times in or across weight vectors--- can be exploited to save energy and improve performance during CNN inference. This generalizes a popular line of work to improve efficiency from CNN weight sparsity, as reducing computation due to repeated zero weights is a special case of reducing computation due to repeated weights. To exploit weight repetition, this paper proposes a new CNN accelerator called the Unique Weight CNN Accelerator (UCNN). UCNN uses weight repetition to reuse CNN sub-computations (e.g., dot products) and to reduce CNN model size when stored in off-chip DRAM ---both of which save energy. UCNN further improves performance by exploiting sparsity in weights. We evaluate UCNN with an accelerator-level cycle and energy model and with an RTL implementation of the UCNN processing element. On three contemporary CNNs, UCNN improves throughput-normalized energy consumption by 1.2x - 4x, relative to a similarly provisioned baseline accelerator that uses Eyeriss-style sparsity optimizations. At the same time, the UCNN processing element adds only 17-24% area overhead relative to the same baseline.