 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClearAIR: A Human-Visual-Perception-Inspired All-in-One Image Restoration
Jan 06, 2026All-in-One Image Restoration (AiOIR) has advanced significantly, offering promising solutions for complex real-world degradations. However, most existing approaches rely heavily on degradation-specific representations, often resulting in oversmoothing and artifacts. To address this, we propose ClearAIR, a novel AiOIR framework inspired by Human Visual Perception (HVP) and designed with a hierarchical, coarse-to-fine restoration strategy. First, leveraging the global priority of early HVP, we employ a Multimodal Large Language Model (MLLM)-based Image Quality Assessment (IQA) model for overall evaluation. Unlike conventional IQA, our method integrates cross-modal understanding to more accurately characterize complex, composite degradations. Building upon this overall assessment, we then introduce a region awareness and task recognition pipeline. A semantic cross-attention, leveraging semantic guidance unit, first produces coarse semantic prompts. Guided by this regional context, a degradation-aware module implicitly captures region-specific degradation characteristics, enabling more precise local restoration. Finally, to recover fine details, we propose an internal clue reuse mechanism. It operates in a self-supervised manner to mine and leverage the intrinsic information of the image itself, substantially enhancing detail restoration. Experimental results show that ClearAIR achieves superior performance across diverse synthetic and real-world datasets.
EASE: Practical and Efficient Safety Alignment for Small Language Models
Nov 09, 2025Small language models (SLMs) are increasingly deployed on edge devices, making their safety alignment crucial yet challenging. Current shallow alignment methods that rely on direct refusal of malicious queries fail to provide robust protection, particularly against adversarial jailbreaks. While deliberative safety reasoning alignment offers deeper alignment for defending against sophisticated attacks, effectively implanting such reasoning capability in SLMs with limited capabilities remains an open challenge. Moreover, safety reasoning incurs significant computational overhead as models apply reasoning to nearly all queries, making it impractical for resource-constrained edge deployment scenarios that demand rapid responses. We propose EASE, a novel framework that enables practical and Efficient safety Alignment for Small languagE models. Our approach first identifies the optimal safety reasoning teacher that can effectively distill safety reasoning capabilities to SLMs. We then align models to selectively activate safety reasoning for dangerous adversarial jailbreak queries while providing direct responses to straightforward malicious queries and general helpful tasks. This selective mechanism enables small models to maintain robust safety guarantees against sophisticated attacks while preserving computational efficiency for benign interactions. Experimental results demonstrate that EASE reduces jailbreak attack success rates by up to 17% compared to shallow alignment methods while reducing inference overhead by up to 90% compared to deliberative safety reasoning alignment, making it practical for SLMs real-world edge deployments.
Perceive-IR: Learning to Perceive Degradation Better for All-in-One Image Restoration
Aug 28, 2024



The limitations of task-specific and general image restoration methods for specific degradation have prompted the development of all-in-one image restoration techniques. However, the diversity of patterns among multiple degradation, along with the significant uncertainties in mapping between degraded images of different severities and their corresponding undistorted versions, pose significant challenges to the all-in-one restoration tasks. To address these challenges, we propose Perceive-IR, an all-in-one image restorer designed to achieve fine-grained quality control that enables restored images to more closely resemble their undistorted counterparts, regardless of the type or severity of degradation. Specifically, Perceive-IR contains two stages: (1) prompt learning stage and (2) restoration stage. In the prompt learning stage, we leverage prompt learning to acquire a fine-grained quality perceiver capable of distinguishing three-tier quality levels by constraining the prompt-image similarity in the CLIP perception space. Subsequently, this quality perceiver and difficulty-adaptive perceptual loss are integrated as a quality-aware learning strategy to realize fine-grained quality control in restoration stage. For the restoration stage, a semantic guidance module (SGM) and compact feature extraction (CFE) are proposed to further promote the restoration process by utilizing the robust semantic information from the pre-trained large scale vision models and distinguishing degradation-specific features. Extensive experiments demonstrate that our Perceive-IR outperforms state-of-the-art methods in all-in-one image restoration tasks and exhibit superior generalization ability when dealing with unseen tasks.
Enhancing RAW-to-sRGB with Decoupled Style Structure in Fourier Domain
Jan 04, 2024


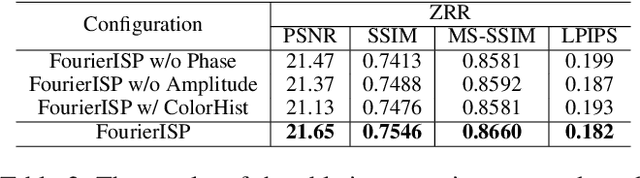
RAW to sRGB mapping, which aims to convert RAW images from smartphones into RGB form equivalent to that of Digital Single-Lens Reflex (DSLR) cameras, has become an important area of research. However, current methods often ignore the difference between cell phone RAW images and DSLR camera RGB images, a difference that goes beyond the color matrix and extends to spatial structure due to resolution variations. Recent methods directly rebuild color mapping and spatial structure via shared deep representation, limiting optimal performance. Inspired by Image Signal Processing (ISP) pipeline, which distinguishes image restoration and enhancement, we present a novel Neural ISP framework, named FourierISP. This approach breaks the image down into style and structure within the frequency domain, allowing for independent optimization. FourierISP is comprised of three subnetworks: Phase Enhance Subnet for structural refinement, Amplitude Refine Subnet for color learning, and Color Adaptation Subnet for blending them in a smooth manner. This approach sharpens both color and structure, and extensive evaluations across varied datasets confirm that our approach realizes state-of-the-art results. Code will be available at ~\url{https://github.com/alexhe101/FourierISP}.
ProRes: Exploring Degradation-aware Visual Prompt for Universal Image Restoration
Jun 23, 2023Image restoration aims to reconstruct degraded images, e.g., denoising or deblurring. Existing works focus on designing task-specific methods and there are inadequate attempts at universal methods. However, simply unifying multiple tasks into one universal architecture suffers from uncontrollable and undesired predictions. To address those issues, we explore prompt learning in universal architectures for image restoration tasks. In this paper, we present Degradation-aware Visual Prompts, which encode various types of image degradation, e.g., noise and blur, into unified visual prompts. These degradation-aware prompts provide control over image processing and allow weighted combinations for customized image restoration. We then leverage degradation-aware visual prompts to establish a controllable and universal model for image restoration, called ProRes, which is applicable to an extensive range of image restoration tasks. ProRes leverages the vanilla Vision Transformer (ViT) without any task-specific designs. Furthermore, the pre-trained ProRes can easily adapt to new tasks through efficient prompt tuning with only a few images. Without bells and whistles, ProRes achieves competitive performance compared to task-specific methods and experiments can demonstrate its ability for controllable restoration and adaptation for new tasks. The code and models will be released in \url{https://github.com/leonmakise/ProRes}.
Long-term Wind Power Forecasting with Hierarchical Spatial-Temporal Transformer
May 30, 2023Wind power is attracting increasing attention around the world due to its renewable, pollution-free, and other advantages. However, safely and stably integrating the high permeability intermittent power energy into electric power systems remains challenging. Accurate wind power forecasting (WPF) can effectively reduce power fluctuations in power system operations. Existing methods are mainly designed for short-term predictions and lack effective spatial-temporal feature augmentation. In this work, we propose a novel end-to-end wind power forecasting model named Hierarchical Spatial-Temporal Transformer Network (HSTTN) to address the long-term WPF problems. Specifically, we construct an hourglass-shaped encoder-decoder framework with skip-connections to jointly model representations aggregated in hierarchical temporal scales, which benefits long-term forecasting. Based on this framework, we capture the inter-scale long-range temporal dependencies and global spatial correlations with two parallel Transformer skeletons and strengthen the intra-scale connections with downsampling and upsampling operations. Moreover, the complementary information from spatial and temporal features is fused and propagated in each other via Contextual Fusion Blocks (CFBs) to promote the prediction further. Extensive experimental results on two large-scale real-world datasets demonstrate the superior performance of our HSTTN over existing solutions.
OpenInst: A Simple Query-Based Method for Open-World Instance Segmentation
Mar 28, 2023



Open-world instance segmentation has recently gained significant popularitydue to its importance in many real-world applications, such as autonomous driving, robot perception, and remote sensing. However, previous methods have either produced unsatisfactory results or relied on complex systems and paradigms. We wonder if there is a simple way to obtain state-of-the-art results. Fortunately, we have identified two observations that help us achieve the best of both worlds: 1) query-based methods demonstrate superiority over dense proposal-based methods in open-world instance segmentation, and 2) learning localization cues is sufficient for open world instance segmentation. Based on these observations, we propose a simple query-based method named OpenInst for open world instance segmentation. OpenInst leverages advanced query-based methods like QueryInst and focuses on learning localization cues. Notably, OpenInst is an extremely simple and straightforward framework without any auxiliary modules or post-processing, yet achieves state-of-the-art results on multiple benchmarks. Specifically, in the COCO$\to$UVO scenario, OpenInst achieves a mask AR of 53.3, outperforming the previous best methods by 2.0 AR with a simpler structure. We hope that OpenInst can serve as a solid baselines for future research in this area.
MM-SFENet: Multi-scale Multi-task Localization and Classification of Bladder Cancer in MRI with Spatial Feature Encoder Network
Feb 22, 2023Background and Objective: Bladder cancer is a common malignant urinary carcinoma, with muscle-invasive and non-muscle-invasive as its two major subtypes. This paper aims to achieve automated bladder cancer invasiveness localization and classification based on MRI. Method: Different from previous efforts that segment bladder wall and tumor, we propose a novel end-to-end multi-scale multi-task spatial feature encoder network (MM-SFENet) for locating and classifying bladder cancer, according to the classification criteria of the spatial relationship between the tumor and bladder wall. First, we built a backbone with residual blocks to distinguish bladder wall and tumor; then, a spatial feature encoder is designed to encode the multi-level features of the backbone to learn the criteria. Results: We substitute Smooth-L1 Loss with IoU Loss for multi-task learning, to improve the accuracy of the classification task. By testing a total of 1287 MRIs collected from 98 patients at the hospital, the mAP and IoU are used as the evaluation metrics. The experimental result could reach 93.34\% and 83.16\% on test set. Conclusions: The experimental result demonstrates the effectiveness of the proposed MM-SFENet on the localization and classification of bladder cancer. It may provide an effective supplementary diagnosis method for bladder cancer staging.
BB-GCN: A Bi-modal Bridged Graph Convolutional Network for Multi-label Chest X-Ray Recognition
Feb 22, 2023



Multi-label chest X-ray (CXR) recognition involves simultaneously diagnosing and identifying multiple labels for different pathologies. Since pathological labels have rich information about their relationship to each other, modeling the co-occurrence dependencies between pathological labels is essential to improve recognition performance. However, previous methods rely on state variable coding and attention mechanisms-oriented to model local label information, and lack learning of global co-occurrence relationships between labels. Furthermore, these methods roughly integrate image features and label embedding, ignoring the alignment and compactness problems in cross-modal vector fusion.To solve these problems, a Bi-modal Bridged Graph Convolutional Network (BB-GCN) model is proposed. This model mainly consists of a backbone module, a pathology Label Co-occurrence relationship Embedding (LCE) module, and a Transformer Bridge Graph (TBG) module. Specifically, the backbone module obtains image visual feature representation. The LCE module utilizes a graph to model the global co-occurrence relationship between multiple labels and employs graph convolutional networks for learning inference. The TBG module bridges the cross-modal vectors more compactly and efficiently through the GroupSum method.We have evaluated the effectiveness of the proposed BB-GCN in two large-scale CXR datasets (ChestX-Ray14 and CheXpert). Our model achieved state-of-the-art performance: the mean AUC scores for the 14 pathologies were 0.835 and 0.813, respectively.The proposed LCE and TBG modules can jointly effectively improve the recognition performance of BB-GCN. Our model also achieves satisfactory results in multi-label chest X-ray recognition and exhibits highly competitive generalization performance.
ELMformer: Efficient Raw Image Restoration with a Locally Multiplicative Transformer
Aug 31, 2022


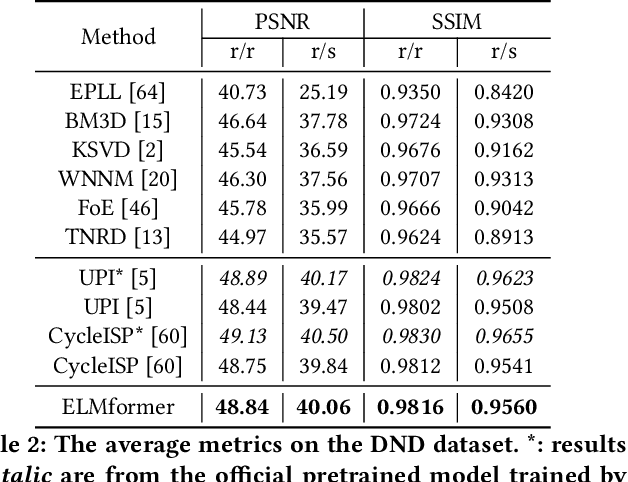
In order to get raw images of high quality for downstream Image Signal Process (ISP), in this paper we present an Efficient Locally Multiplicative Transformer called ELMformer for raw image restoration. ELMformer contains two core designs especially for raw images whose primitive attribute is single-channel. The first design is a Bi-directional Fusion Projection (BFP) module, where we consider both the color characteristics of raw images and spatial structure of single-channel. The second one is that we propose a Locally Multiplicative Self-Attention (L-MSA) scheme to effectively deliver information from the local space to relevant parts. ELMformer can efficiently reduce the computational consumption and perform well on raw image restoration tasks. Enhanced by these two core designs, ELMformer achieves the highest performance and keeps the lowest FLOPs on raw denoising and raw deblurring benchmarks compared with state-of-the-arts. Extensive experiments demonstrate the superiority and generalization ability of ELMformer. On SIDD benchmark, our method has even better denoising performance than ISP-based methods which need huge amount of additional sRGB training images. The codes are release at https://github.com/leonmakise/ELMformer.