 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification Accuracy: Neural-MedBench and the Need for Deeper Reasoning Benchmarks
Sep 26, 2025Recent advances in vision-language models (VLMs) have achieved remarkable performance on standard medical benchmarks, yet their true clinical reasoning ability remains unclear. Existing datasets predominantly emphasize classification accuracy, creating an evaluation illusion in which models appear proficient while still failing at high-stakes diagnostic reasoning. We introduce Neural-MedBench, a compact yet reasoning-intensive benchmark specifically designed to probe the limits of multimodal clinical reasoning in neurology. Neural-MedBench integrates multi-sequence MRI scans, structured electronic health records, and clinical notes, and encompasses three core task families: differential diagnosis, lesion recognition, and rationale generation. To ensure reliable evaluation, we develop a hybrid scoring pipeline that combines LLM-based graders, clinician validation, and semantic similarity metrics. Through systematic evaluation of state-of-the-art VLMs, including GPT-4o, Claude-4, and MedGemma, we observe a sharp performance drop compared to conventional datasets. Error analysis shows that reasoning failures, rather than perceptual errors, dominate model shortcomings. Our findings highlight the necessity of a Two-Axis Evaluation Framework: breadth-oriented large datasets for statistical generalization, and depth-oriented, compact benchmarks such as Neural-MedBench for reasoning fidelity. We release Neural-MedBench at https://neuromedbench.github.io/ as an open and extensible diagnostic testbed, which guides the expansion of future benchmarks and enables rigorous yet cost-effective assessment of clinically trustworthy AI.
LLMs Caught in the Crossfire: Malware Requests and Jailbreak Challenges
Jun 09, 2025The widespread adoption of Large Language Models (LLMs) has heightened concerns about their security, particularly their vulnerability to jailbreak attacks that leverage crafted prompts to generate malicious outputs. While prior research has been conducted on general security capabilities of LLMs, their specific susceptibility to jailbreak attacks in code generation remains largely unexplored. To fill this gap, we propose MalwareBench, a benchmark dataset containing 3,520 jailbreaking prompts for malicious code-generation, designed to evaluate LLM robustness against such threats. MalwareBench is based on 320 manually crafted malicious code generation requirements, covering 11 jailbreak methods and 29 code functionality categories. Experiments show that mainstream LLMs exhibit limited ability to reject malicious code-generation requirements, and the combination of multiple jailbreak methods further reduces the model's security capabilities: specifically, the average rejection rate for malicious content is 60.93%, dropping to 39.92% when combined with jailbreak attack algorithms. Our work highlights that the code security capabilities of LLMs still pose significant challenges.
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Dec 04, 2023Vision transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it still remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone. For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.0 average mAP on THUMOS14, 37.12 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Is Underwater Image Enhancement All Object Detectors Need?
Nov 30, 2023Underwater object detection is a crucial and challenging problem in marine engineering and aquatic robot. The difficulty is partly because of the degradation of underwater images caused by light selective absorption and scattering. Intuitively, enhancing underwater images can benefit high-level applications like underwater object detection. However, it is still unclear whether all object detectors need underwater image enhancement as pre-processing. We therefore pose the questions "Does underwater image enhancement really improve underwater object detection?" and "How does underwater image enhancement contribute to underwater object detection?". With these two questions, we conduct extensive studies. Specifically, we use 18 state-of-the-art underwater image enhancement algorithms, covering traditional, CNN-based, and GAN-based algorithms, to pre-process underwater object detection data. Then, we retrain 7 popular deep learning-based object detectors using the corresponding results enhanced by different algorithms, obtaining 126 underwater object detection models. Coupled with 7 object detection models retrained using raw underwater images, we employ these 133 models to comprehensively analyze the effect of underwater image enhancement on underwater object detection. We expect this study can provide sufficient exploration to answer the aforementioned questions and draw more attention of the community to the joint problem of underwater image enhancement and underwater object detection. The pre-trained models and results are publicly available and will be regularly updated. Project page: https://github.com/BIGWangYuDong/lqit/tree/main/configs/detection/uw_enhancement_affect_detection.
Cross-Domain Correlation Distillation for Unsupervised Domain Adaptation in Nighttime Semantic Segmentation
May 02, 2022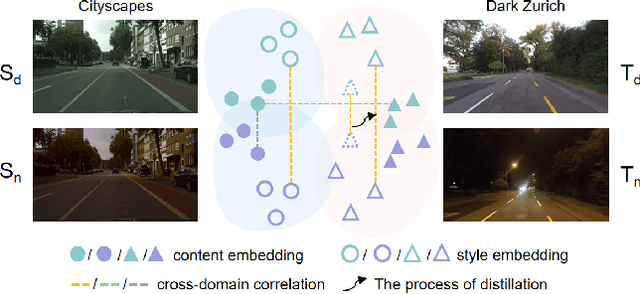
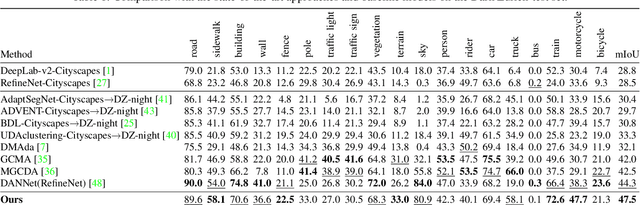


The performance of nighttime semantic segmentation is restricted by the poor illumination and a lack of pixel-wise annotation, which severely limit its application in autonomous driving. Existing works, e.g., using the twilight as the intermediate target domain to perform the adaptation from daytime to nighttime, may fail to cope with the inherent difference between datasets caused by the camera equipment and the urban style. Faced with these two types of domain shifts, i.e., the illumination and the inherent difference of the datasets, we propose a novel domain adaptation framework via cross-domain correlation distillation, called CCDistill. The invariance of illumination or inherent difference between two images is fully explored so as to make up for the lack of labels for nighttime images. Specifically, we extract the content and style knowledge contained in features, calculate the degree of inherent or illumination difference between two images. The domain adaptation is achieved using the invariance of the same kind of difference. Extensive experiments on Dark Zurich and ACDC demonstrate that CCDistill achieves the state-of-the-art performance for nighttime semantic segmentation. Notably, our method is a one-stage domain adaptation network which can avoid affecting the inference time. Our implementation is available at https://github.com/ghuan99/CCDistill.
UIEC^2-Net: CNN-based Underwater Image Enhancement Using Two Color Space
Mar 12, 2021


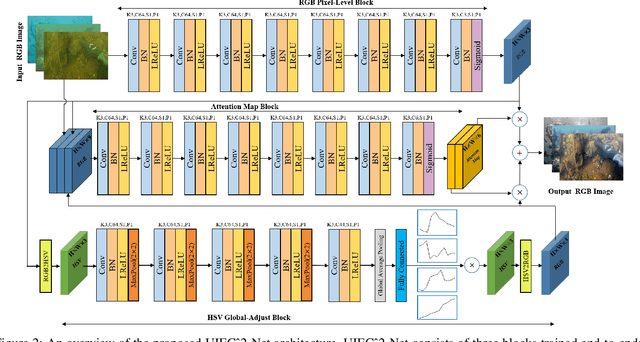
Underwater image enhancement has attracted much attention due to the rise of marine resource development in recent years. Benefit from the powerful representation capabilities of Convolution Neural Networks(CNNs), multiple underwater image enhancement algorithms based on CNNs have been proposed in the last few years. However, almost all of these algorithms employ RGB color space setting, which is insensitive to image properties such as luminance and saturation. To address this problem, we proposed Underwater Image Enhancement Convolution Neural Network using 2 Color Space (UICE^2-Net) that efficiently and effectively integrate both RGB Color Space and HSV Color Space in one single CNN. To our best knowledge, this method is the first to use HSV color space for underwater image enhancement based on deep learning. UIEC^2-Net is an end-to-end trainable network, consisting of three blocks as follow: a RGB pixel-level block implements fundamental operations such as denoising and removing color cast, a HSV global-adjust block for globally adjusting underwater image luminance, color and saturation by adopting a novel neural curve layer, and an attention map block for combining the advantages of RGB and HSV block output images by distributing weight to each pixel. Experimental results on synthetic and real-world underwater images show the good performance of our proposed method in both subjective comparisons and objective metrics.
Efficiently Embedding Dynamic Knowledge Graphs
Oct 15, 2019
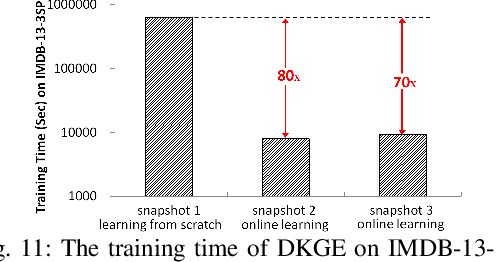

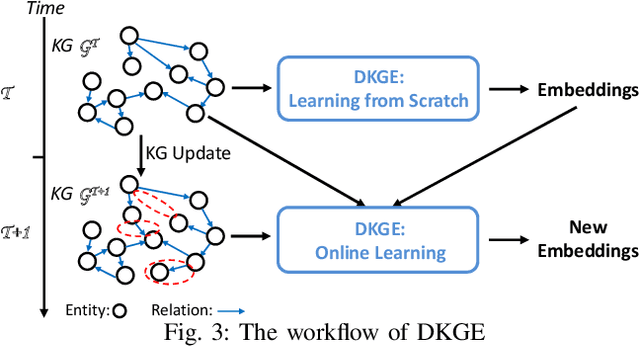
Knowledge graph (KG) embedding encodes the entities and relations from a KG into low-dimensional vector spaces to support various applications such as KG completion, question answering, and recommender systems. In real world, knowledge graphs (KGs) are dynamic and evolve over time with addition or deletion of triples. However, most existing models focus on embedding static KGs while neglecting dynamics. To adapt to the changes in a KG, these models need to be re-trained on the whole KG with a high time cost. In this paper, to tackle the aforementioned problem, we propose a new context-aware Dynamic Knowledge Graph Embedding (DKGE) method which supports the embedding learning in an online fashion. DKGE introduces two different representations (i.e., knowledge embedding and contextual element embedding) for each entity and each relation, in the joint modeling of entities and relations as well as their contexts, by employing two attentive graph convolutional networks, a gate strategy, and translation operations. This effectively helps limit the impacts of a KG update in certain regions, not in the entire graph, so that DKGE can rapidly acquire the updated KG embedding by a proposed online learning algorithm. Furthermore, DKGE can also learn KG embedding from scratch. Experiments on the tasks of link prediction and question answering in a dynamic environment demonstrate the effectiveness and efficiency of DKGE.