 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Underwater Image Enhancement All Object Detectors Need?
Nov 30, 2023Underwater object detection is a crucial and challenging problem in marine engineering and aquatic robot. The difficulty is partly because of the degradation of underwater images caused by light selective absorption and scattering. Intuitively, enhancing underwater images can benefit high-level applications like underwater object detection. However, it is still unclear whether all object detectors need underwater image enhancement as pre-processing. We therefore pose the questions "Does underwater image enhancement really improve underwater object detection?" and "How does underwater image enhancement contribute to underwater object detection?". With these two questions, we conduct extensive studies. Specifically, we use 18 state-of-the-art underwater image enhancement algorithms, covering traditional, CNN-based, and GAN-based algorithms, to pre-process underwater object detection data. Then, we retrain 7 popular deep learning-based object detectors using the corresponding results enhanced by different algorithms, obtaining 126 underwater object detection models. Coupled with 7 object detection models retrained using raw underwater images, we employ these 133 models to comprehensively analyze the effect of underwater image enhancement on underwater object detection. We expect this study can provide sufficient exploration to answer the aforementioned questions and draw more attention of the community to the joint problem of underwater image enhancement and underwater object detection. The pre-trained models and results are publicly available and will be regularly updated. Project page: https://github.com/BIGWangYuDong/lqit/tree/main/configs/detection/uw_enhancement_affect_detection.
Cross-Domain Correlation Distillation for Unsupervised Domain Adaptation in Nighttime Semantic Segmentation
May 02, 2022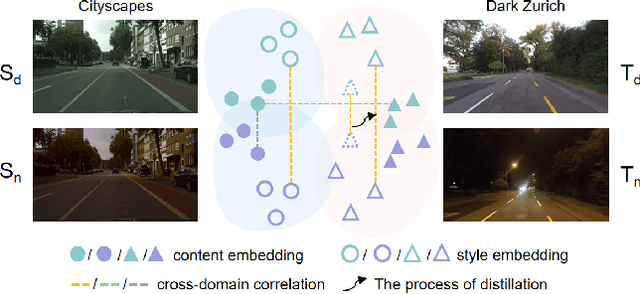
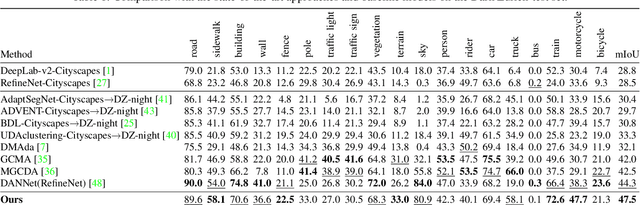


The performance of nighttime semantic segmentation is restricted by the poor illumination and a lack of pixel-wise annotation, which severely limit its application in autonomous driving. Existing works, e.g., using the twilight as the intermediate target domain to perform the adaptation from daytime to nighttime, may fail to cope with the inherent difference between datasets caused by the camera equipment and the urban style. Faced with these two types of domain shifts, i.e., the illumination and the inherent difference of the datasets, we propose a novel domain adaptation framework via cross-domain correlation distillation, called CCDistill. The invariance of illumination or inherent difference between two images is fully explored so as to make up for the lack of labels for nighttime images. Specifically, we extract the content and style knowledge contained in features, calculate the degree of inherent or illumination difference between two images. The domain adaptation is achieved using the invariance of the same kind of difference. Extensive experiments on Dark Zurich and ACDC demonstrate that CCDistill achieves the state-of-the-art performance for nighttime semantic segmentation. Notably, our method is a one-stage domain adaptation network which can avoid affecting the inference time. Our implementation is available at https://github.com/ghuan99/CCDistill.
UIEC^2-Net: CNN-based Underwater Image Enhancement Using Two Color Space
Mar 12, 2021


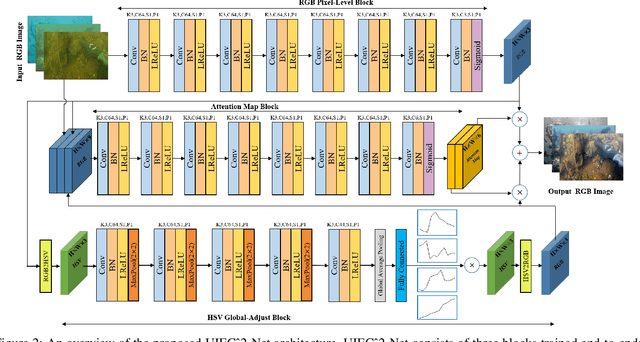
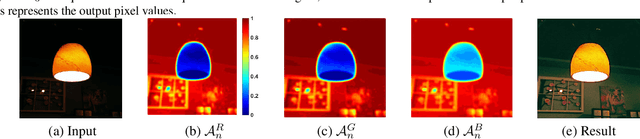
Underwater image enhancement has attracted much attention due to the rise of marine resource development in recent years. Benefit from the powerful representation capabilities of Convolution Neural Networks(CNNs), multiple underwater image enhancement algorithms based on CNNs have been proposed in the last few years. However, almost all of these algorithms employ RGB color space setting, which is insensitive to image properties such as luminance and saturation. To address this problem, we proposed Underwater Image Enhancement Convolution Neural Network using 2 Color Space (UICE^2-Net) that efficiently and effectively integrate both RGB Color Space and HSV Color Space in one single CNN. To our best knowledge, this method is the first to use HSV color space for underwater image enhancement based on deep learning. UIEC^2-Net is an end-to-end trainable network, consisting of three blocks as follow: a RGB pixel-level block implements fundamental operations such as denoising and removing color cast, a HSV global-adjust block for globally adjusting underwater image luminance, color and saturation by adopting a novel neural curve layer, and an attention map block for combining the advantages of RGB and HSV block output images by distributing weight to each pixel. Experimental results on synthetic and real-world underwater images show the good performance of our proposed method in both subjective comparisons and objective metrics.
Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement
Jan 19, 2020


The paper presents a novel method, Zero-Reference Deep Curve Estimation (Zero-DCE), which formulates light enhancement as a task of image-specific curve estimation with a deep network. Our method trains a lightweight deep network, DCE-Net, to estimate pixel-wise and high-order curves for dynamic range adjustment of a given image. The curve estimation is specially designed, considering pixel value range, monotonicity, and differentiability. Zero-DCE is appealing in its relaxed assumption on reference images, i.e., it does not require any paired or unpaired data during training. This is achieved through a set of carefully formulated non-reference loss functions, which implicitly measure the enhancement quality and drive the learning of the network. Our method is efficient as image enhancement can be achieved by an intuitive and simple nonlinear curve mapping. Despite its simplicity, we show that it generalizes well to diverse lighting conditions. Extensive experiments on various benchmarks demonstrate the advantages of our method over state-of-the-art methods qualitatively and quantitatively. Furthermore, the potential benefits of our Zero-DCE to face detection in the dark are discussed. Code and model will be available at https://github.com/Li-Chongyi/Zero-DCE.
Bi-Adversarial Auto-Encoder for Zero-Shot Learning
Nov 20, 2018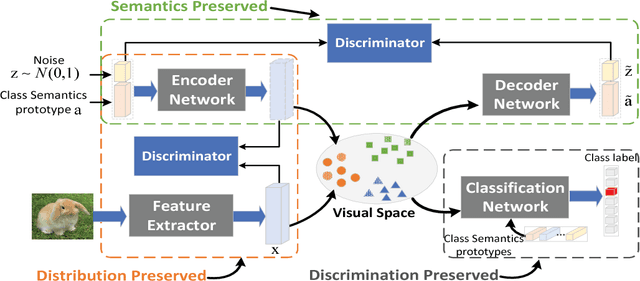

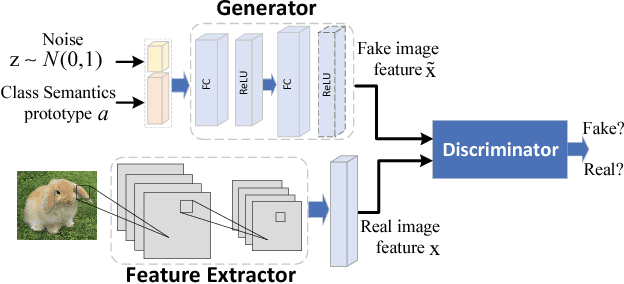

Existing generative Zero-Shot Learning (ZSL) methods only consider the unidirectional alignment from the class semantics to the visual features while ignoring the alignment from the visual features to the class semantics, which fails to construct the visual-semantic interactions well. In this paper, we propose to synthesize visual features based on an auto-encoder framework paired with bi-adversarial networks respectively for visual and semantic modalities to reinforce the visual-semantic interactions with a bi-directional alignment, which ensures the synthesized visual features to fit the real visual distribution and to be highly related to the semantics. The encoder aims at synthesizing real-like visual features while the decoder forces both the real and the synthesized visual features to be more related to the class semantics. To further capture the discriminative information of the synthesized visual features, both the real and synthesized visual features are forced to be classified into the correct classes via a classification network. Experimental results on four benchmark datasets show that the proposed approach is particularly competitive on both the traditional ZSL and the generalized ZSL tasks.
Stacked Semantic-Guided Attention Model for Fine-Grained Zero-Shot Learning
May 21, 2018



Zero-Shot Learning (ZSL) is achieved via aligning the semantic relationships between the global image feature vector and the corresponding class semantic descriptions. However, using the global features to represent fine-grained images may lead to sub-optimal results since they neglect the discriminative differences of local regions. Besides, different regions contain distinct discriminative information. The important regions should contribute more to the prediction. To this end, we propose a novel stacked semantics-guided attention (S2GA) model to obtain semantic relevant features by using individual class semantic features to progressively guide the visual features to generate an attention map for weighting the importance of different local regions. Feeding both the integrated visual features and the class semantic features into a multi-class classification architecture, the proposed framework can be trained end-to-end. Extensive experimental results on CUB and NABird datasets show that the proposed approach has a consistent improvement on both fine-grained zero-shot classification and retrieval tasks.
Zero-Shot Learning via Latent Space Encoding
Apr 20, 2018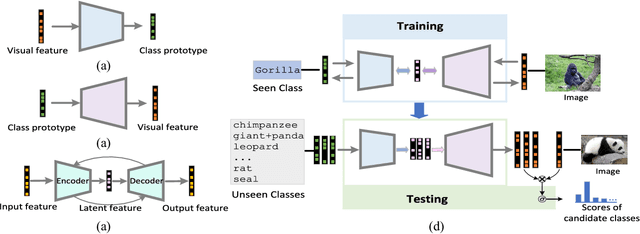
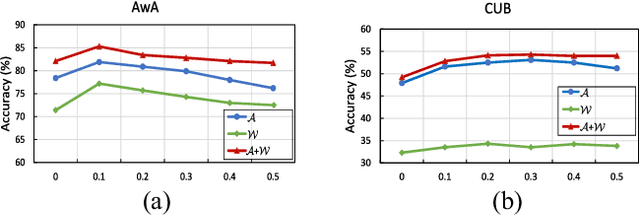
Zero-Shot Learning (ZSL) is typically achieved by resorting to a class semantic embedding space to transfer the knowledge from the seen classes to unseen ones. Capturing the common semantic characteristics between the visual modality and the class semantic modality (e.g., attributes or word vector) is a key to the success of ZSL. In this paper, we propose a novel encoder-decoder approach, namely Latent Space Encoding (LSE), to connect the semantic relations of different modalities. Instead of requiring a projection function to transfer information across different modalities like most previous work, LSE per- forms the interactions of different modalities via a feature aware latent space, which is learned in an implicit way. Specifically, different modalities are modeled separately but optimized jointly. For each modality, an encoder-decoder framework is performed to learn a feature aware latent space via jointly maximizing the recoverability of the original space from the latent space and the predictability of the latent space from the original space. To relate different modalities together, their features referring to the same concept are enforced to share the same latent codings. In this way, the common semantic characteristics of different modalities are generalized with the latent representations. Another property of the proposed approach is that it is easily extended to more modalities. Extensive experimental results on four benchmark datasets (AwA, CUB, aPY, and ImageNet) clearly demonstrate the superiority of the proposed approach on several ZSL tasks, including traditional ZSL, generalized ZSL, and zero-shot retrieval (ZSR).
A Cascaded Convolutional Neural Network for Single Image Dehazing
Mar 21, 2018

Images captured under outdoor scenes usually suffer from low contrast and limited visibility due to suspended atmospheric particles, which directly affects the quality of photos. Despite numerous image dehazing methods have been proposed, effective hazy image restoration remains a challenging problem. Existing learning-based methods usually predict the medium transmission by Convolutional Neural Networks (CNNs), but ignore the key global atmospheric light. Different from previous learning-based methods, we propose a flexible cascaded CNN for single hazy image restoration, which considers the medium transmission and global atmospheric light jointly by two task-driven subnetworks. Specifically, the medium transmission estimation subnetwork is inspired by the densely connected CNN while the global atmospheric light estimation subnetwork is a light-weight CNN. Besides, these two subnetworks are cascaded by sharing the common features. Finally, with the estimated model parameters, the haze-free image is obtained by the atmospheric scattering model inversion, which achieves more accurate and effective restoration performance. Qualitatively and quantitatively experimental results on the synthetic and real-world hazy images demonstrate that the proposed method effectively removes haze from such images, and outperforms several state-of-the-art dehazing methods.
Emerging from Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer
Jan 03, 2018



Underwater vision suffers from severe effects due to selective attenuation and scattering when light propagates through water. Such degradation not only affects the quality of underwater images but limits the ability of vision tasks. Different from existing methods which either ignore the wavelength dependency of the attenuation or assume a specific spectral profile, we tackle color distortion problem of underwater image from a new view. In this letter, we propose a weakly supervised color transfer method to correct color distortion, which relaxes the need of paired underwater images for training and allows for the underwater images unknown where were taken. Inspired by Cycle-Consistent Adversarial Networks, we design a multi-term loss function including adversarial loss, cycle consistency loss, and SSIM (Structural Similarity Index Measure) loss, which allows the content and structure of the corrected result the same as the input, but the color as if the image was taken without the water. Experiments on underwater images captured under diverse scenes show that our method produces visually pleasing results, even outperforms the art-of-the-state methods. Besides, our method can improve the performance of vision tasks.
* Submitted to IEEE Signal Processing Letters
DR-Net: Transmission Steered Single Image Dehazing Network with Weakly Supervised Refinement
Dec 02, 2017
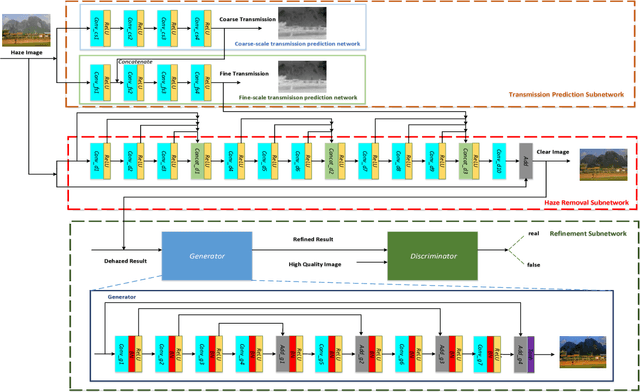


Despite the recent progress in image dehazing, several problems remain largely unsolved such as robustness for varying scenes, the visual quality of reconstructed images, and effectiveness and flexibility for applications. To tackle these problems, we propose a new deep network architecture for single image dehazing called DR-Net. Our model consists of three main subnetworks: a transmission prediction network that predicts transmission map for the input image, a haze removal network that reconstructs latent image steered by the transmission map, and a refinement network that enhances the details and color properties of the dehazed result via weakly supervised learning. Compared to previous methods, our method advances in three aspects: (i) pure data-driven model; (ii) the end-to-end system; (iii) superior robustness, accuracy, and applicability. Extensive experiments demonstrate that our DR-Net outperforms the state-of-the-art methods on both synthetic and real images in qualitative and quantitative metrics. Additionally, the utility of DR-Net has been illustrated by its potential usage in several important computer vision tasks.