 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Learning via Latent Space Encoding
Paper and Code
Apr 20, 2018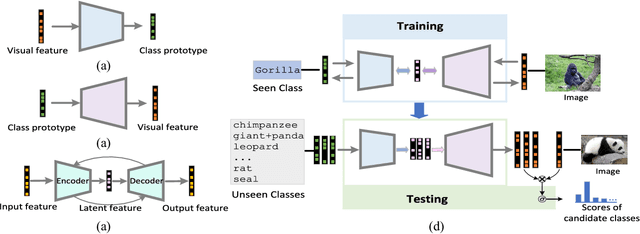
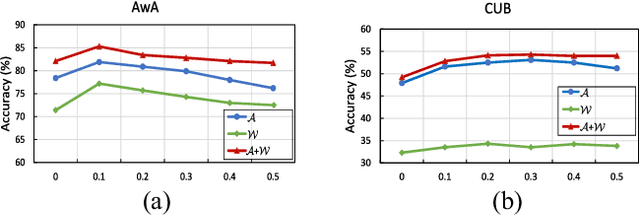
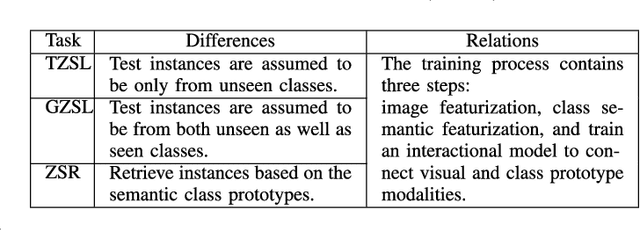
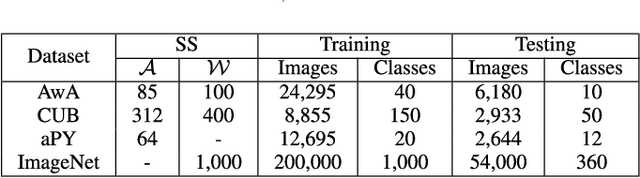
Zero-Shot Learning (ZSL) is typically achieved by resorting to a class semantic embedding space to transfer the knowledge from the seen classes to unseen ones. Capturing the common semantic characteristics between the visual modality and the class semantic modality (e.g., attributes or word vector) is a key to the success of ZSL. In this paper, we propose a novel encoder-decoder approach, namely Latent Space Encoding (LSE), to connect the semantic relations of different modalities. Instead of requiring a projection function to transfer information across different modalities like most previous work, LSE per- forms the interactions of different modalities via a feature aware latent space, which is learned in an implicit way. Specifically, different modalities are modeled separately but optimized jointly. For each modality, an encoder-decoder framework is performed to learn a feature aware latent space via jointly maximizing the recoverability of the original space from the latent space and the predictability of the latent space from the original space. To relate different modalities together, their features referring to the same concept are enforced to share the same latent codings. In this way, the common semantic characteristics of different modalities are generalized with the latent representations. Another property of the proposed approach is that it is easily extended to more modalities. Extensive experimental results on four benchmark datasets (AwA, CUB, aPY, and ImageNet) clearly demonstrate the superiority of the proposed approach on several ZSL tasks, including traditional ZSL, generalized ZSL, and zero-shot retrieval (ZSR).