 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025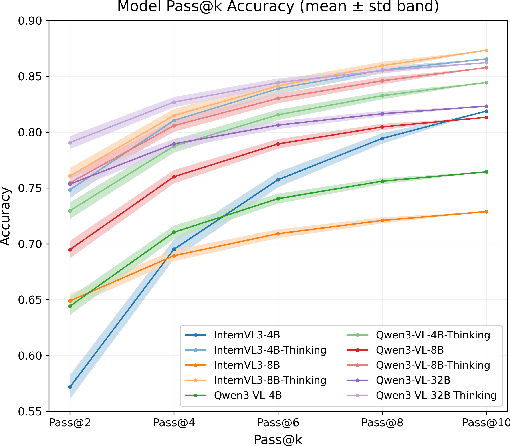

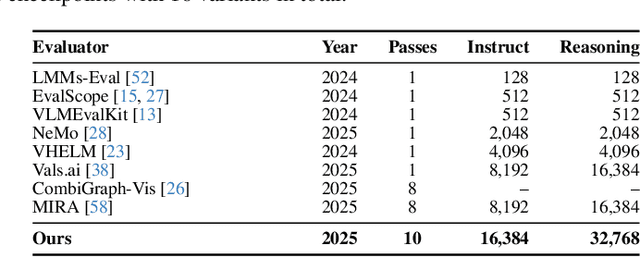
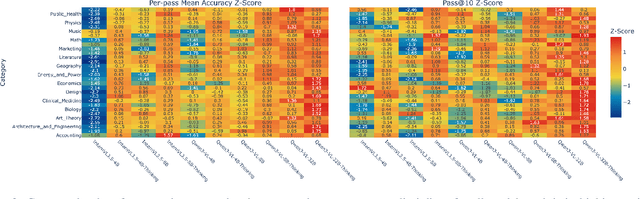
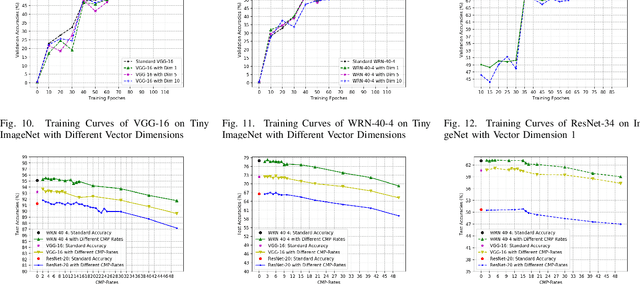
Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Locally Linear Region Knowledge Distillation
Oct 19, 2020



Knowledge distillation (KD) is an effective technique to transfer knowledge from one neural network (teacher) to another (student), thus improving the performance of the student. To make the student better mimic the behavior of the teacher, the existing work focuses on designing different criteria to align their logits or representations. Different from these efforts, we address knowledge distillation from a novel data perspective. We argue that transferring knowledge at sparse training data points cannot enable the student to well capture the local shape of the teacher function. To address this issue, we propose locally linear region knowledge distillation ($\rm L^2$RKD) which transfers the knowledge in local, linear regions from a teacher to a student. This is achieved by enforcing the student to mimic the outputs of the teacher function in local, linear regions. To the end, the student is able to better capture the local shape of the teacher function and thus achieves a better performance. Despite its simplicity, extensive experiments demonstrate that $\rm L^2$RKD is superior to the original KD in many aspects as it outperforms KD and the other state-of-the-art approaches by a large margin, shows robustness and superiority under few-shot settings, and is more compatible with the existing distillation approaches to further improve their performances significantly.
Deep Collective Learning: Learning Optimal Inputs and Weights Jointly in Deep Neural Networks
Sep 17, 2020
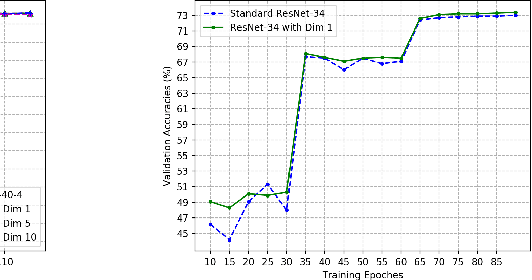

It is well observed that in deep learning and computer vision literature, visual data are always represented in a manually designed coding scheme (eg., RGB images are represented as integers ranging from 0 to 255 for each channel) when they are input to an end-to-end deep neural network (DNN) for any learning task. We boldly question whether the manually designed inputs are good for DNN training for different tasks and study whether the input to a DNN can be optimally learned end-to-end together with learning the weights of the DNN. In this paper, we propose the paradigm of {\em deep collective learning} which aims to learn the weights of DNNs and the inputs to DNNs simultaneously for given tasks. We note that collective learning has been implicitly but widely used in natural language processing while it has almost never been studied in computer vision. Consequently, we propose the lookup vision networks (Lookup-VNets) as a solution to deep collective learning in computer vision. This is achieved by associating each color in each channel with a vector in lookup tables. As learning inputs in computer vision has almost never been studied in the existing literature, we explore several aspects of this question through varieties of experiments on image classification tasks. Experimental results on four benchmark datasets, i.e., CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet (ILSVRC2012) have shown several surprising characteristics of Lookup-VNets and have demonstrated the advantages and promise of Lookup-VNets and deep collective learning.
Zero-Shot Learning via Latent Space Encoding
Apr 20, 2018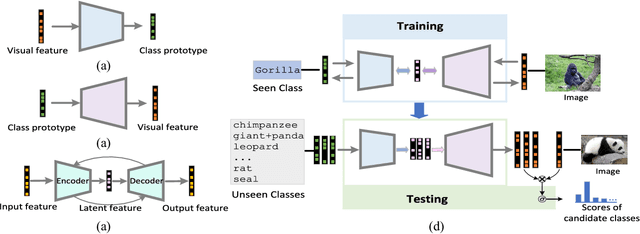
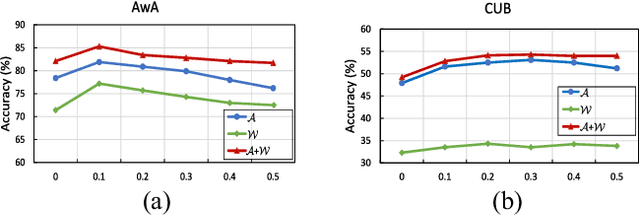
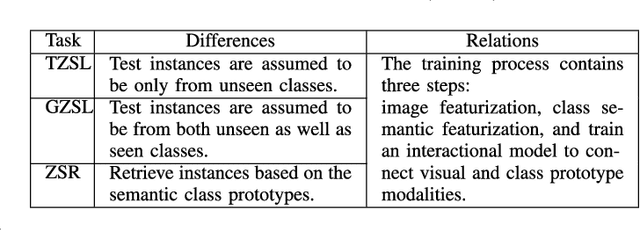
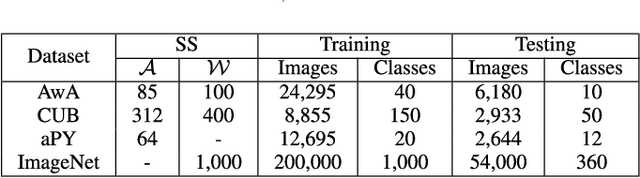
Zero-Shot Learning (ZSL) is typically achieved by resorting to a class semantic embedding space to transfer the knowledge from the seen classes to unseen ones. Capturing the common semantic characteristics between the visual modality and the class semantic modality (e.g., attributes or word vector) is a key to the success of ZSL. In this paper, we propose a novel encoder-decoder approach, namely Latent Space Encoding (LSE), to connect the semantic relations of different modalities. Instead of requiring a projection function to transfer information across different modalities like most previous work, LSE per- forms the interactions of different modalities via a feature aware latent space, which is learned in an implicit way. Specifically, different modalities are modeled separately but optimized jointly. For each modality, an encoder-decoder framework is performed to learn a feature aware latent space via jointly maximizing the recoverability of the original space from the latent space and the predictability of the latent space from the original space. To relate different modalities together, their features referring to the same concept are enforced to share the same latent codings. In this way, the common semantic characteristics of different modalities are generalized with the latent representations. Another property of the proposed approach is that it is easily extended to more modalities. Extensive experimental results on four benchmark datasets (AwA, CUB, aPY, and ImageNet) clearly demonstrate the superiority of the proposed approach on several ZSL tasks, including traditional ZSL, generalized ZSL, and zero-shot retrieval (ZSR).
Deep Air Learning: Interpolation, Prediction, and Feature Analysis of Fine-grained Air Quality
Apr 11, 2018
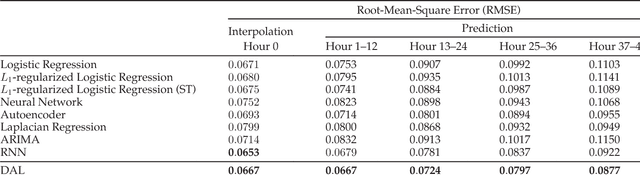
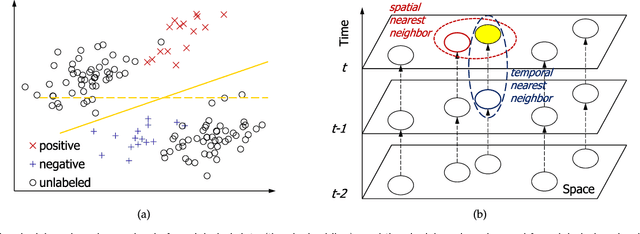

The interpolation, prediction, and feature analysis of fine-gained air quality are three important topics in the area of urban air computing. The solutions to these topics can provide extremely useful information to support air pollution control, and consequently generate great societal and technical impacts. Most of the existing work solves the three problems separately by different models. In this paper, we propose a general and effective approach to solve the three problems in one model called the Deep Air Learning (DAL). The main idea of DAL lies in embedding feature selection and semi-supervised learning in different layers of the deep learning network. The proposed approach utilizes the information pertaining to the unlabeled spatio-temporal data to improve the performance of the interpolation and the prediction, and performs feature selection and association analysis to reveal the main relevant features to the variation of the air quality. We evaluate our approach with extensive experiments based on real data sources obtained in Beijing, China. Experiments show that DAL is superior to the peer models from the recent literature when solving the topics of interpolation, prediction, and feature analysis of fine-gained air quality.
Boosted Zero-Shot Learning with Semantic Correlation Regularization
Jul 25, 2017

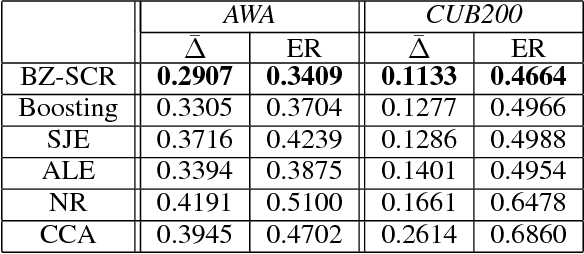
We study zero-shot learning (ZSL) as a transfer learning problem, and focus on the two key aspects of ZSL, model effectiveness and model adaptation. For effective modeling, we adopt the boosting strategy to learn a zero-shot classifier from weak models to a strong model. For adaptable knowledge transfer, we devise a Semantic Correlation Regularization (SCR) approach to regularize the boosted model to be consistent with the inter-class semantic correlations. With SCR embedded in the boosting objective, and with a self-controlled sample selection for learning robustness, we propose a unified framework, Boosted Zero-shot classification with Semantic Correlation Regularization (BZ-SCR). By balancing the SCR-regularized boosted model selection and the self-controlled sample selection, BZ-SCR is capable of capturing both discriminative and adaptable feature-to-class semantic alignments, while ensuring the reliability and adaptability of the learned samples. The experiments on two ZSL datasets show the superiority of BZ-SCR over the state-of-the-arts.