 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Collective Learning: Learning Optimal Inputs and Weights Jointly in Deep Neural Networks
Paper and Code

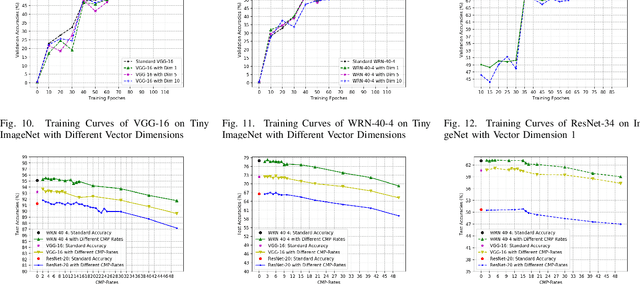

It is well observed that in deep learning and computer vision literature, visual data are always represented in a manually designed coding scheme (eg., RGB images are represented as integers ranging from 0 to 255 for each channel) when they are input to an end-to-end deep neural network (DNN) for any learning task. We boldly question whether the manually designed inputs are good for DNN training for different tasks and study whether the input to a DNN can be optimally learned end-to-end together with learning the weights of the DNN. In this paper, we propose the paradigm of {\em deep collective learning} which aims to learn the weights of DNNs and the inputs to DNNs simultaneously for given tasks. We note that collective learning has been implicitly but widely used in natural language processing while it has almost never been studied in computer vision. Consequently, we propose the lookup vision networks (Lookup-VNets) as a solution to deep collective learning in computer vision. This is achieved by associating each color in each channel with a vector in lookup tables. As learning inputs in computer vision has almost never been studied in the existing literature, we explore several aspects of this question through varieties of experiments on image classification tasks. Experimental results on four benchmark datasets, i.e., CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet (ILSVRC2012) have shown several surprising characteristics of Lookup-VNets and have demonstrated the advantages and promise of Lookup-VNets and deep collective learning.