 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData driven approach towards more efficient Newton-Raphson power flow calculation for distribution grids
Apr 15, 2025Power flow (PF) calculations are fundamental to power system analysis to ensure stable and reliable grid operation. The Newton-Raphson (NR) method is commonly used for PF analysis due to its rapid convergence when initialized properly. However, as power grids operate closer to their capacity limits, ill-conditioned cases and convergence issues pose significant challenges. This work, therefore, addresses these challenges by proposing strategies to improve NR initialization, hence minimizing iterations and avoiding divergence. We explore three approaches: (i) an analytical method that estimates the basin of attraction using mathematical bounds on voltages, (ii) Two data-driven models leveraging supervised learning or physics-informed neural networks (PINNs) to predict optimal initial guesses, and (iii) a reinforcement learning (RL) approach that incrementally adjusts voltages to accelerate convergence. These methods are tested on benchmark systems. This research is particularly relevant for modern power systems, where high penetration of renewables and decentralized generation require robust and scalable PF solutions. In experiments, all three proposed methods demonstrate a strong ability to provide an initial guess for Newton-Raphson method to converge with fewer steps. The findings provide a pathway for more efficient real-time grid operations, which, in turn, support the transition toward smarter and more resilient electricity networks.
Incorporating Graph Attention Mechanism into Geometric Problem Solving Based on Deep Reinforcement Learning
Mar 14, 2024In the context of online education, designing an automatic solver for geometric problems has been considered a crucial step towards general math Artificial Intelligence (AI), empowered by natural language understanding and traditional logical inference. In most instances, problems are addressed by adding auxiliary components such as lines or points. However, adding auxiliary components automatically is challenging due to the complexity in selecting suitable auxiliary components especially when pivotal decisions have to be made. The state-of-the-art performance has been achieved by exhausting all possible strategies from the category library to identify the one with the maximum likelihood. However, an extensive strategy search have to be applied to trade accuracy for ef-ficiency. To add auxiliary components automatically and efficiently, we present deep reinforcement learning framework based on the language model, such as BERT. We firstly apply the graph attention mechanism to reduce the strategy searching space, called AttnStrategy, which only focus on the conclusion-related components. Meanwhile, a novel algorithm, named Automatically Adding Auxiliary Components using Reinforcement Learning framework (A3C-RL), is proposed by forcing an agent to select top strategies, which incorporates the AttnStrategy and BERT as the memory components. Results from extensive experiments show that the proposed A3C-RL algorithm can substantially enhance the average precision by 32.7% compared to the traditional MCTS. In addition, the A3C-RL algorithm outperforms humans on the geometric questions from the annual University Entrance Mathematical Examination of China.
ELMformer: Efficient Raw Image Restoration with a Locally Multiplicative Transformer
Aug 31, 2022


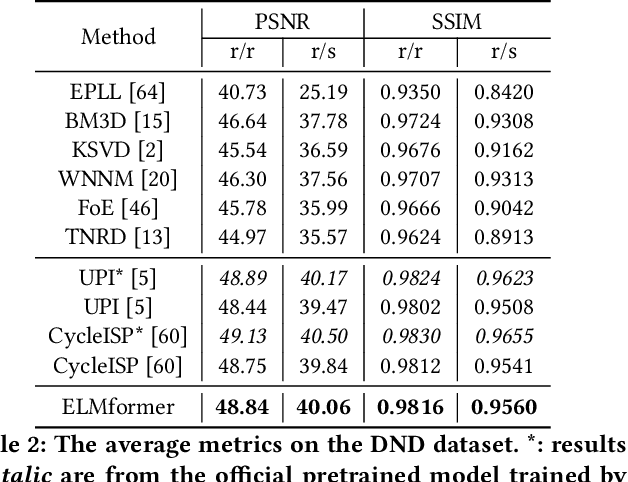
In order to get raw images of high quality for downstream Image Signal Process (ISP), in this paper we present an Efficient Locally Multiplicative Transformer called ELMformer for raw image restoration. ELMformer contains two core designs especially for raw images whose primitive attribute is single-channel. The first design is a Bi-directional Fusion Projection (BFP) module, where we consider both the color characteristics of raw images and spatial structure of single-channel. The second one is that we propose a Locally Multiplicative Self-Attention (L-MSA) scheme to effectively deliver information from the local space to relevant parts. ELMformer can efficiently reduce the computational consumption and perform well on raw image restoration tasks. Enhanced by these two core designs, ELMformer achieves the highest performance and keeps the lowest FLOPs on raw denoising and raw deblurring benchmarks compared with state-of-the-arts. Extensive experiments demonstrate the superiority and generalization ability of ELMformer. On SIDD benchmark, our method has even better denoising performance than ISP-based methods which need huge amount of additional sRGB training images. The codes are release at https://github.com/leonmakise/ELMformer.