 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Graph Attention Mechanism into Geometric Problem Solving Based on Deep Reinforcement Learning
Mar 14, 2024In the context of online education, designing an automatic solver for geometric problems has been considered a crucial step towards general math Artificial Intelligence (AI), empowered by natural language understanding and traditional logical inference. In most instances, problems are addressed by adding auxiliary components such as lines or points. However, adding auxiliary components automatically is challenging due to the complexity in selecting suitable auxiliary components especially when pivotal decisions have to be made. The state-of-the-art performance has been achieved by exhausting all possible strategies from the category library to identify the one with the maximum likelihood. However, an extensive strategy search have to be applied to trade accuracy for ef-ficiency. To add auxiliary components automatically and efficiently, we present deep reinforcement learning framework based on the language model, such as BERT. We firstly apply the graph attention mechanism to reduce the strategy searching space, called AttnStrategy, which only focus on the conclusion-related components. Meanwhile, a novel algorithm, named Automatically Adding Auxiliary Components using Reinforcement Learning framework (A3C-RL), is proposed by forcing an agent to select top strategies, which incorporates the AttnStrategy and BERT as the memory components. Results from extensive experiments show that the proposed A3C-RL algorithm can substantially enhance the average precision by 32.7% compared to the traditional MCTS. In addition, the A3C-RL algorithm outperforms humans on the geometric questions from the annual University Entrance Mathematical Examination of China.
Hierarchical Aspect-guided Explanation Generation for Explainable Recommendation
Oct 23, 2021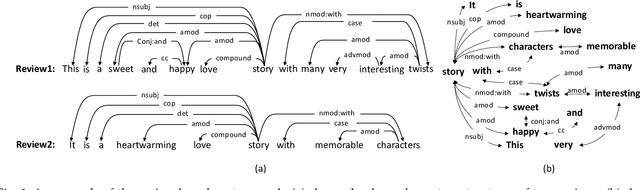
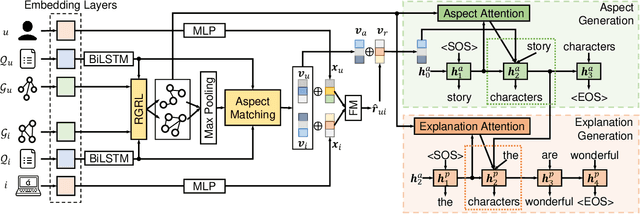
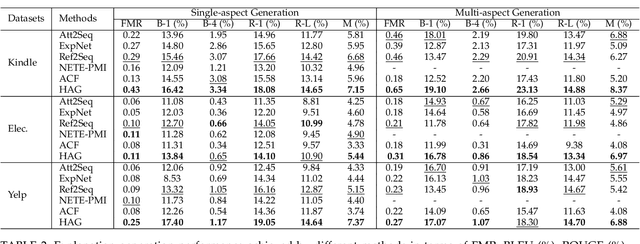
Explainable recommendation systems provide explanations for recommendation results to improve their transparency and persuasiveness. The existing explainable recommendation methods generate textual explanations without explicitly considering the user's preferences on different aspects of the item. In this paper, we propose a novel explanation generation framework, named Hierarchical Aspect-guided explanation Generation (HAG), for explainable recommendation. Specifically, HAG employs a review-based syntax graph to provide a unified view of the user/item details. An aspect-guided graph pooling operator is proposed to extract the aspect-relevant information from the review-based syntax graphs to model the user's preferences on an item at the aspect level. Then, a hierarchical explanation decoder is developed to generate aspects and aspect-relevant explanations based on the attention mechanism. The experimental results on three real datasets indicate that HAG outperforms state-of-the-art explanation generation methods in both single-aspect and multi-aspect explanation generation tasks, and also achieves comparable or even better preference prediction accuracy than strong baseline methods.
Commonsense knowledge adversarial dataset that challenges ELECTRA
Oct 25, 2020
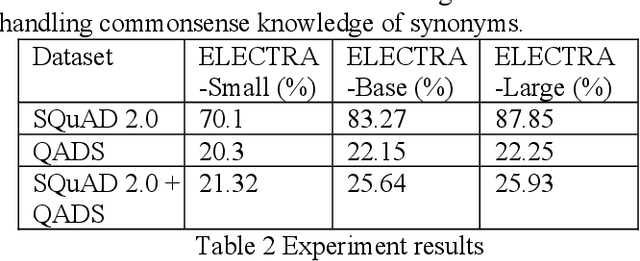
Commonsense knowledge is critical in human reading comprehension. While machine comprehension has made significant progress in recent years, the ability in handling commonsense knowledge remains limited. Synonyms are one of the most widely used commonsense knowledge. Constructing adversarial dataset is an important approach to find weak points of machine comprehension models and support the design of solutions. To investigate machine comprehension models' ability in handling the commonsense knowledge, we created a Question and Answer Dataset with common knowledge of Synonyms (QADS). QADS are questions generated based on SQuAD 2.0 by applying commonsense knowledge of synonyms. The synonyms are extracted from WordNet. Words often have multiple meanings and synonyms. We used an enhanced Lesk algorithm to perform word sense disambiguation to identify synonyms for the context. ELECTRA achieves the state-of-art result on the SQuAD 2.0 dataset in 2019. With scale, ELECTRA can achieve similar performance as BERT does. However, QADS shows that ELECTRA has little ability to handle commonsense knowledge of synonyms. In our experiment, ELECTRA-small can achieve 70% accuracy on SQuAD 2.0, but only 20% on QADS. ELECTRA-large did not perform much better. Its accuracy on SQuAD 2.0 is 88% but dropped significantly to 26% on QADS. In our earlier experiments, BERT, although also failed badly on QADS, was not as bad as ELECTRA. The result shows that even top-performing NLP models have little ability to handle commonsense knowledge which is essential in reading comprehension.
Commonsense Knowledge + BERT for Level 2 Reading Comprehension Ability Test
Sep 08, 2019Commonsense knowledge plays an important role when we read. The performance of BERT on SQuAD dataset shows that the accuracy of BERT can be better than human users. However, it does not mean that computers can surpass the human being in reading comprehension. CommonsenseQA is a large-scale dataset which is designed based on commonsense knowledge. BERT only achieved an accuracy of 55.9% on it. The result shows that computers cannot apply commonsense knowledge like human beings to answer questions. Comprehension Ability Test (CAT) divided the reading comprehension ability at four levels. We can achieve human like comprehension ability level by level. BERT has performed well at level 1 which does not require common knowledge. In this research, we propose a system which aims to allow computers to read articles and answer related questions with commonsense knowledge like a human being for CAT level 2. This system consists of three parts. Firstly, we built a commonsense knowledge graph; and then automatically constructed the commonsense knowledge question dataset according to it. Finally, BERT is combined with the commonsense knowledge to achieve the reading comprehension ability at CAT level 2. Experiments show that it can pass the CAT as long as the required common knowledge is included in the knowledge base.
Reading Comprehension Ability Test-A Turing Test for Reading Comprehension
Sep 05, 2019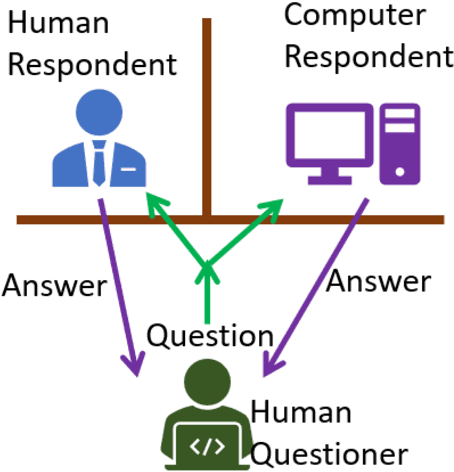
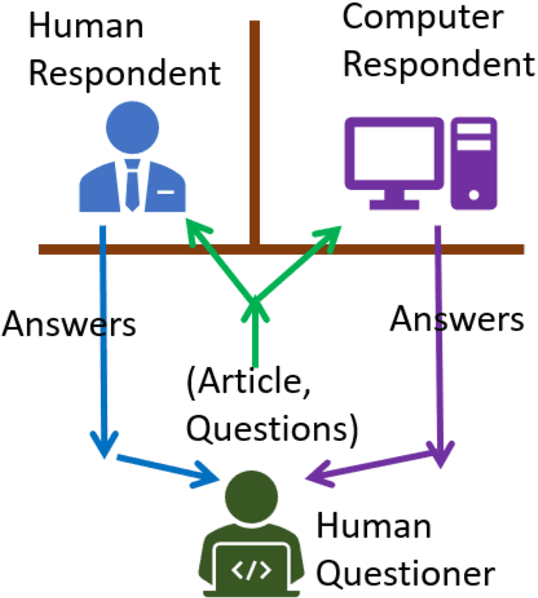
Reading comprehension is an important ability of human intelligence. Literacy and numeracy are two most essential foundation for people to succeed at study, at work and in life. Reading comprehension ability is a core component of literacy. In most of the education systems, developing reading comprehension ability is compulsory in the curriculum from year one to year 12. It is an indispensable ability in the dissemination of knowledge. With the emerging artificial intelligence, computers start to be able to read and understand like people in some context. They can even read better than human beings for some tasks, but have little clue in other tasks. It will be very beneficial if we can identify the levels of machine comprehension ability, which will direct us on the further improvement. Turing test is a well-known test of the difference between computer intelligence and human intelligence. In order to be able to compare the difference between people reading and machines reading, we proposed a test called (reading) Comprehension Ability Test (CAT).CAT is similar to Turing test, passing of which means we cannot differentiate people from algorithms in term of their comprehension ability. CAT has multiple levels showing the different abilities in reading comprehension, from identifying basic facts, performing inference, to understanding the intent and sentiment.