 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore User Neighborhood for Real-time E-commerce Recommendation
Feb 28, 2021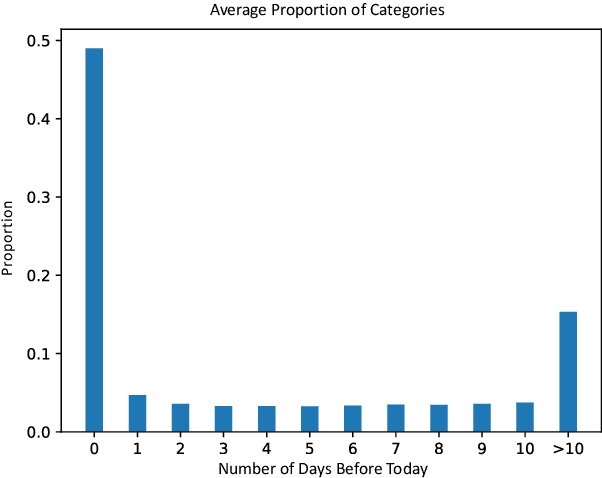
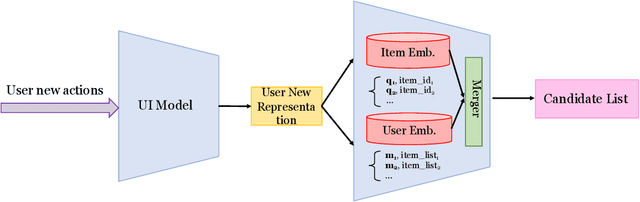
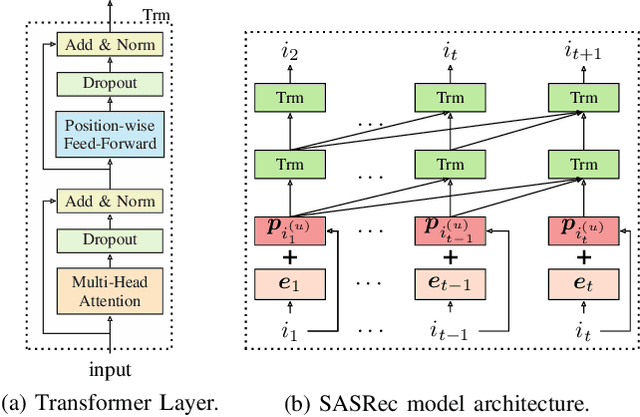
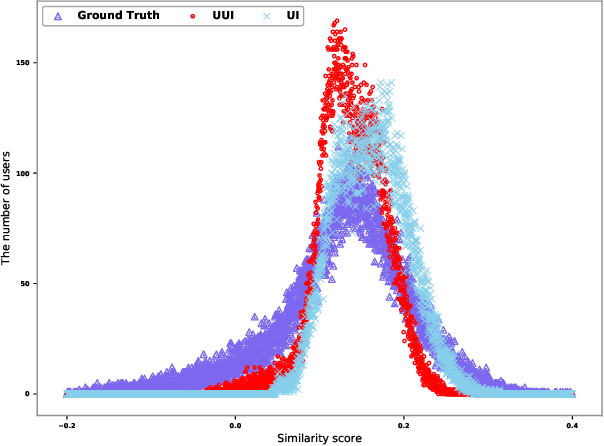
Recommender systems play a vital role in modern online services, such as Amazon and Taobao. Traditional personalized methods, which focus on user-item (UI) relations, have been widely applied in industrial settings, owing to their efficiency and effectiveness. Despite their success, we argue that these approaches ignore local information hidden in similar users. To tackle this problem, user-based methods exploit similar user relations to make recommendations in a local perspective. Nevertheless, traditional user-based methods, like userKNN and matrix factorization, are intractable to be deployed in the real-time applications since such transductive models have to be recomputed or retrained with any new interaction. To overcome this challenge, we propose a framework called self-complementary collaborative filtering~(SCCF) which can make recommendations with both global and local information in real time. On the one hand, it utilizes UI relations and user neighborhood to capture both global and local information. On the other hand, it can identify similar users for each user in real time by inferring user representations on the fly with an inductive model. The proposed framework can be seamlessly incorporated into existing inductive UI approach and benefit from user neighborhood with little additional computation. It is also the first attempt to apply user-based methods in real-time settings. The effectiveness and efficiency of SCCF are demonstrated through extensive offline experiments on four public datasets, as well as a large scale online A/B test in Taobao.
Commonsense knowledge adversarial dataset that challenges ELECTRA
Oct 25, 2020
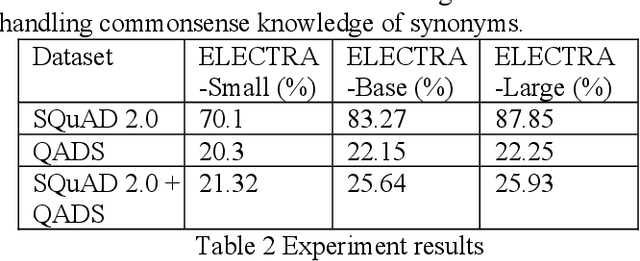
Commonsense knowledge is critical in human reading comprehension. While machine comprehension has made significant progress in recent years, the ability in handling commonsense knowledge remains limited. Synonyms are one of the most widely used commonsense knowledge. Constructing adversarial dataset is an important approach to find weak points of machine comprehension models and support the design of solutions. To investigate machine comprehension models' ability in handling the commonsense knowledge, we created a Question and Answer Dataset with common knowledge of Synonyms (QADS). QADS are questions generated based on SQuAD 2.0 by applying commonsense knowledge of synonyms. The synonyms are extracted from WordNet. Words often have multiple meanings and synonyms. We used an enhanced Lesk algorithm to perform word sense disambiguation to identify synonyms for the context. ELECTRA achieves the state-of-art result on the SQuAD 2.0 dataset in 2019. With scale, ELECTRA can achieve similar performance as BERT does. However, QADS shows that ELECTRA has little ability to handle commonsense knowledge of synonyms. In our experiment, ELECTRA-small can achieve 70% accuracy on SQuAD 2.0, but only 20% on QADS. ELECTRA-large did not perform much better. Its accuracy on SQuAD 2.0 is 88% but dropped significantly to 26% on QADS. In our earlier experiments, BERT, although also failed badly on QADS, was not as bad as ELECTRA. The result shows that even top-performing NLP models have little ability to handle commonsense knowledge which is essential in reading comprehension.
Privileged Features Distillation for E-Commerce Recommendations
Jul 11, 2019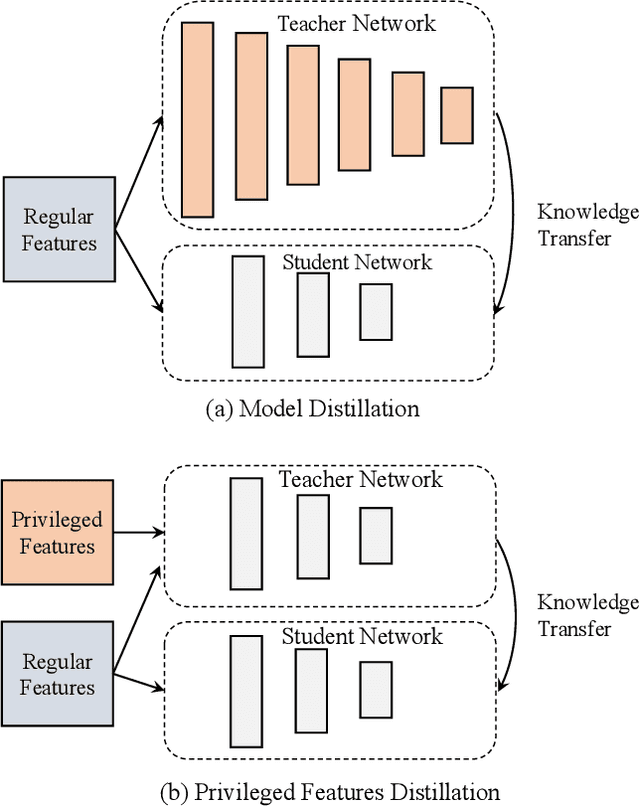
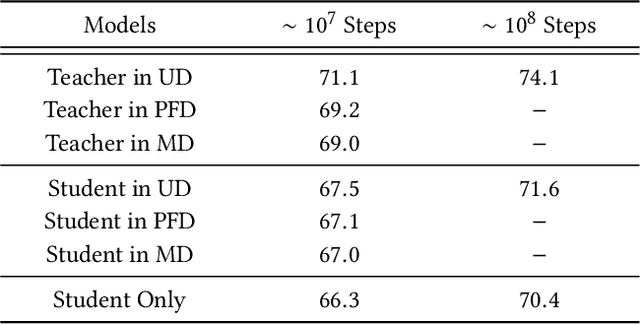
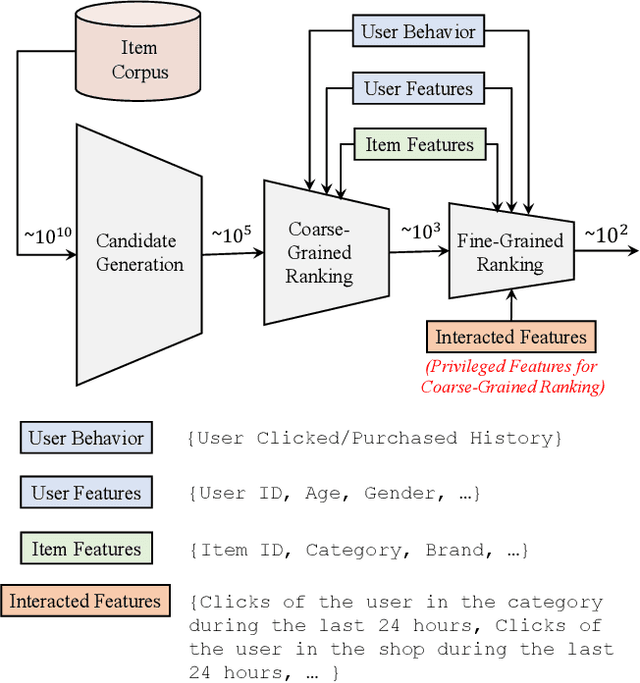

Features play an important role in most prediction tasks of e-commerce recommendations. To guarantee the consistence of off-line training and on-line serving, we usually utilize the same features that are both available. However, the consistence in turn neglects some discriminative features. For example, when estimating the conversion rate (CVR), i.e., the probability that a user would purchase the item after she has clicked it, features like dwell time on the item detailed page can be very informative. However, CVR prediction should be conducted for on-line ranking before the click happens. Thus we cannot get such post-event features during serving. Here we define the features that are discriminative but only available during training as the privileged features. Inspired by the distillation techniques which bridge the gap between training and inference, in this work, we propose privileged features distillation (PFD). We train two models, i.e., a student model that is the same as the original one and a teacher model that additionally utilizes the privileged features. Knowledge distilled from the more accurate teacher is transferred to the student, which helps to improve its prediction accuracy. During serving, only the student part is extracted. To our knowledge, this is the first work to fully exploit the potential of such features. To validate the effectiveness of PFD, we conduct experiments on two fundamental prediction tasks in Taobao recommendations, i.e., click-through rate (CTR) at coarse-grained ranking and CVR at fine-grained ranking. By distilling the interacted features that are prohibited during serving for CTR and the post-event features for CVR, we achieve significant improvements over both of the strong baselines. Besides, by addressing several issues of training PFD, we obtain comparable training speed as the baselines without any distillation.