 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivileged Features Distillation for E-Commerce Recommendations
Paper and Code
Jul 11, 2019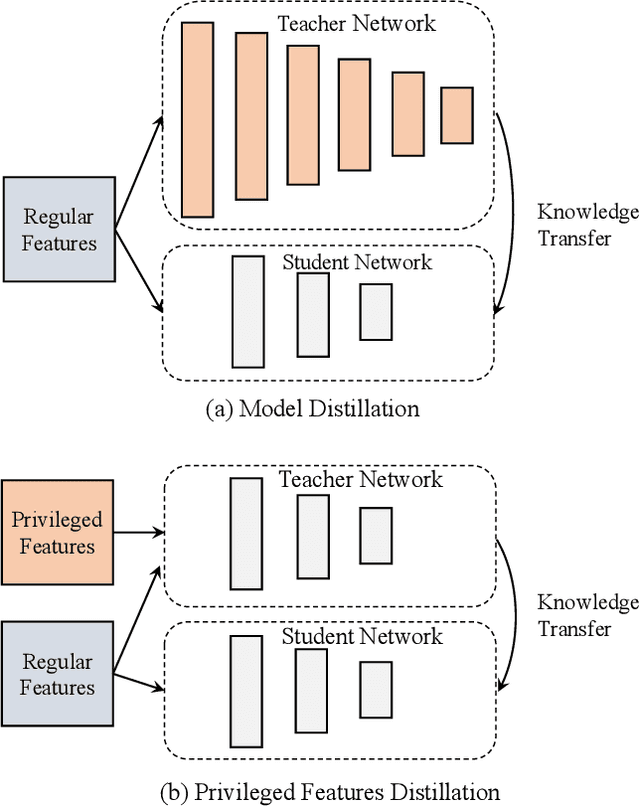
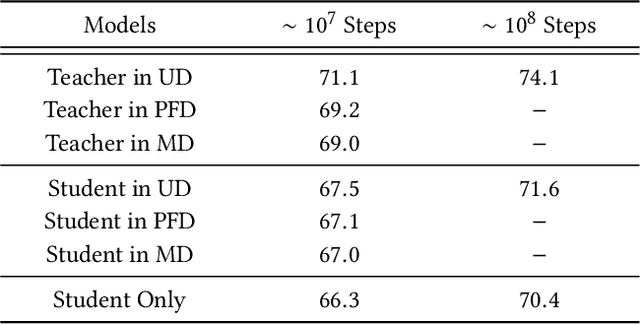
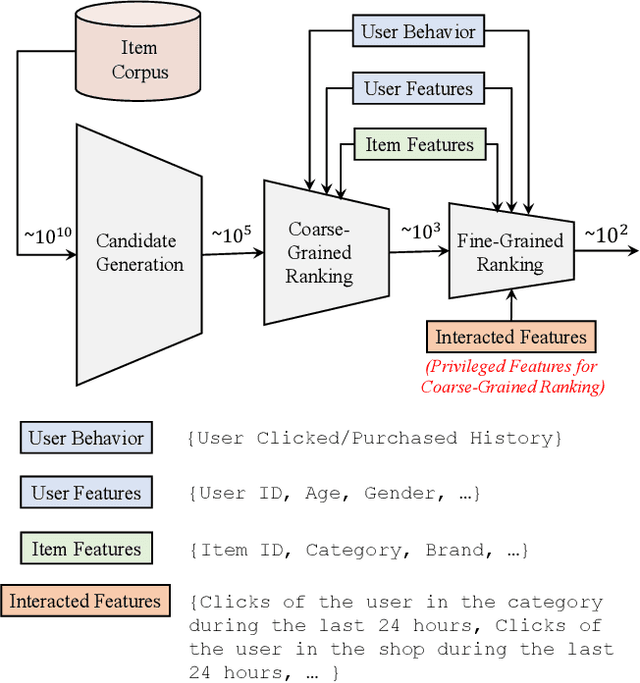

Features play an important role in most prediction tasks of e-commerce recommendations. To guarantee the consistence of off-line training and on-line serving, we usually utilize the same features that are both available. However, the consistence in turn neglects some discriminative features. For example, when estimating the conversion rate (CVR), i.e., the probability that a user would purchase the item after she has clicked it, features like dwell time on the item detailed page can be very informative. However, CVR prediction should be conducted for on-line ranking before the click happens. Thus we cannot get such post-event features during serving. Here we define the features that are discriminative but only available during training as the privileged features. Inspired by the distillation techniques which bridge the gap between training and inference, in this work, we propose privileged features distillation (PFD). We train two models, i.e., a student model that is the same as the original one and a teacher model that additionally utilizes the privileged features. Knowledge distilled from the more accurate teacher is transferred to the student, which helps to improve its prediction accuracy. During serving, only the student part is extracted. To our knowledge, this is the first work to fully exploit the potential of such features. To validate the effectiveness of PFD, we conduct experiments on two fundamental prediction tasks in Taobao recommendations, i.e., click-through rate (CTR) at coarse-grained ranking and CVR at fine-grained ranking. By distilling the interacted features that are prohibited during serving for CTR and the post-event features for CVR, we achieve significant improvements over both of the strong baselines. Besides, by addressing several issues of training PFD, we obtain comparable training speed as the baselines without any distillation.