 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks
Jun 07, 2023To promote the development of Vision-Language Pre-training (VLP) and multimodal Large Language Model (LLM) in the Chinese community, we firstly release the largest public Chinese high-quality video-language dataset named Youku-mPLUG, which is collected from Youku, a well-known Chinese video-sharing website, with strict criteria of safety, diversity, and quality. Youku-mPLUG contains 10 million Chinese video-text pairs filtered from 400 million raw videos across a wide range of 45 diverse categories for large-scale pre-training. In addition, to facilitate a comprehensive evaluation of video-language models, we carefully build the largest human-annotated Chinese benchmarks covering three popular video-language tasks of cross-modal retrieval, video captioning, and video category classification. Youku-mPLUG can enable researchers to conduct more in-depth multimodal research and develop better applications in the future. Furthermore, we release popular video-language pre-training models, ALPRO and mPLUG-2, and our proposed modularized decoder-only model mPLUG-video pre-trained on Youku-mPLUG. Experiments show that models pre-trained on Youku-mPLUG gain up to 23.1% improvement in video category classification. Besides, mPLUG-video achieves a new state-of-the-art result on these benchmarks with 80.5% top-1 accuracy in video category classification and 68.9 CIDEr score in video captioning, respectively. Finally, we scale up mPLUG-video based on the frozen Bloomz with only 1.7% trainable parameters as Chinese multimodal LLM, and demonstrate impressive instruction and video understanding ability. The zero-shot instruction understanding experiment indicates that pretraining with Youku-mPLUG can enhance the ability to comprehend overall and detailed visual semantics, recognize scene text, and leverage open-domain knowledge.
Hierarchical Aspect-guided Explanation Generation for Explainable Recommendation
Oct 23, 2021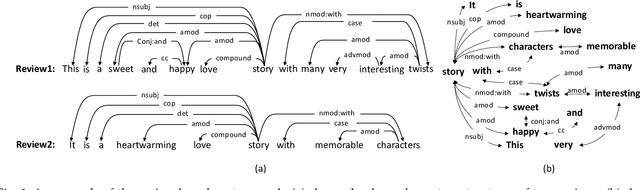
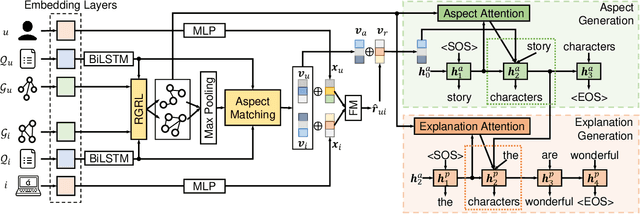
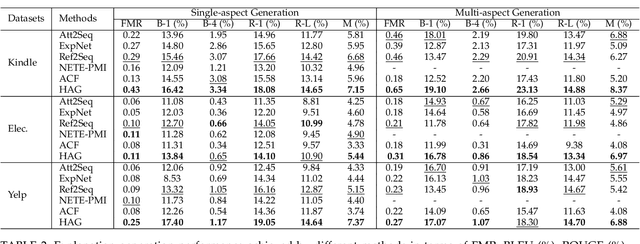
Explainable recommendation systems provide explanations for recommendation results to improve their transparency and persuasiveness. The existing explainable recommendation methods generate textual explanations without explicitly considering the user's preferences on different aspects of the item. In this paper, we propose a novel explanation generation framework, named Hierarchical Aspect-guided explanation Generation (HAG), for explainable recommendation. Specifically, HAG employs a review-based syntax graph to provide a unified view of the user/item details. An aspect-guided graph pooling operator is proposed to extract the aspect-relevant information from the review-based syntax graphs to model the user's preferences on an item at the aspect level. Then, a hierarchical explanation decoder is developed to generate aspects and aspect-relevant explanations based on the attention mechanism. The experimental results on three real datasets indicate that HAG outperforms state-of-the-art explanation generation methods in both single-aspect and multi-aspect explanation generation tasks, and also achieves comparable or even better preference prediction accuracy than strong baseline methods.
Commonsense knowledge adversarial dataset that challenges ELECTRA
Oct 25, 2020
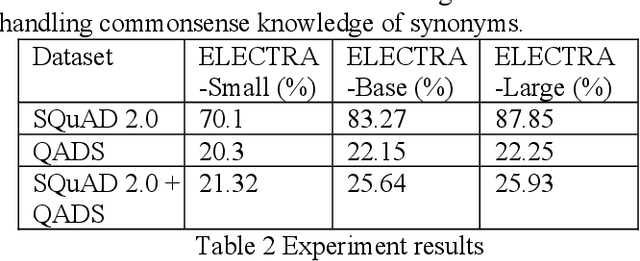
Commonsense knowledge is critical in human reading comprehension. While machine comprehension has made significant progress in recent years, the ability in handling commonsense knowledge remains limited. Synonyms are one of the most widely used commonsense knowledge. Constructing adversarial dataset is an important approach to find weak points of machine comprehension models and support the design of solutions. To investigate machine comprehension models' ability in handling the commonsense knowledge, we created a Question and Answer Dataset with common knowledge of Synonyms (QADS). QADS are questions generated based on SQuAD 2.0 by applying commonsense knowledge of synonyms. The synonyms are extracted from WordNet. Words often have multiple meanings and synonyms. We used an enhanced Lesk algorithm to perform word sense disambiguation to identify synonyms for the context. ELECTRA achieves the state-of-art result on the SQuAD 2.0 dataset in 2019. With scale, ELECTRA can achieve similar performance as BERT does. However, QADS shows that ELECTRA has little ability to handle commonsense knowledge of synonyms. In our experiment, ELECTRA-small can achieve 70% accuracy on SQuAD 2.0, but only 20% on QADS. ELECTRA-large did not perform much better. Its accuracy on SQuAD 2.0 is 88% but dropped significantly to 26% on QADS. In our earlier experiments, BERT, although also failed badly on QADS, was not as bad as ELECTRA. The result shows that even top-performing NLP models have little ability to handle commonsense knowledge which is essential in reading comprehension.
Time-aware Graph Embedding: A temporal smoothness and task-oriented approach
Jul 22, 2020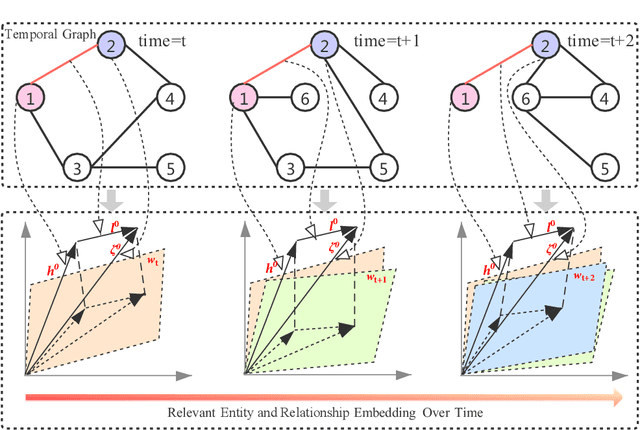

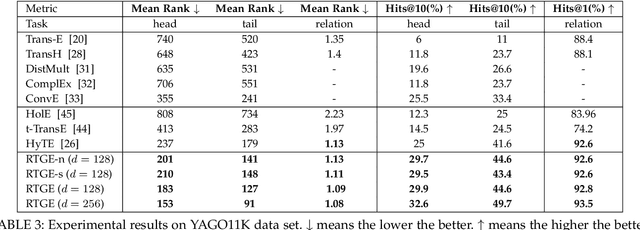
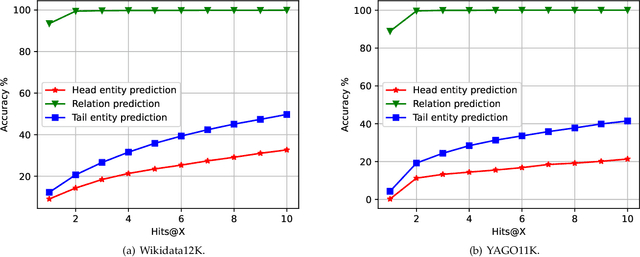
Knowledge graph embedding, which aims to learn the low-dimensional representations of entities and relationships, has attracted considerable research efforts recently. However, most knowledge graph embedding methods focus on the structural relationships in fixed triples while ignoring the temporal information. Currently, existing time-aware graph embedding methods only focus on the factual plausibility, while ignoring the temporal smoothness which models the interactions between a fact and its contexts, and thus can capture fine-granularity temporal relationships. This leads to the limited performance of embedding related applications. To solve this problem, this paper presents a Robustly Time-aware Graph Embedding (RTGE) method by incorporating temporal smoothness. Two major innovations of our paper are presented here. At first, RTGE integrates a measure of temporal smoothness in the learning process of the time-aware graph embedding. Via the proposed additional smoothing factor, RTGE can preserve both structural information and evolutionary patterns of a given graph. Secondly, RTGE provides a general task-oriented negative sampling strategy associated with temporally-aware information, which further improves the adaptive ability of the proposed algorithm and plays an essential role in obtaining superior performance in various tasks. Extensive experiments conducted on multiple benchmark tasks show that RTGE can increase performance in entity/relationship/temporal scoping prediction tasks.
Commonsense Knowledge + BERT for Level 2 Reading Comprehension Ability Test
Sep 08, 2019Commonsense knowledge plays an important role when we read. The performance of BERT on SQuAD dataset shows that the accuracy of BERT can be better than human users. However, it does not mean that computers can surpass the human being in reading comprehension. CommonsenseQA is a large-scale dataset which is designed based on commonsense knowledge. BERT only achieved an accuracy of 55.9% on it. The result shows that computers cannot apply commonsense knowledge like human beings to answer questions. Comprehension Ability Test (CAT) divided the reading comprehension ability at four levels. We can achieve human like comprehension ability level by level. BERT has performed well at level 1 which does not require common knowledge. In this research, we propose a system which aims to allow computers to read articles and answer related questions with commonsense knowledge like a human being for CAT level 2. This system consists of three parts. Firstly, we built a commonsense knowledge graph; and then automatically constructed the commonsense knowledge question dataset according to it. Finally, BERT is combined with the commonsense knowledge to achieve the reading comprehension ability at CAT level 2. Experiments show that it can pass the CAT as long as the required common knowledge is included in the knowledge base.
Reading Comprehension Ability Test-A Turing Test for Reading Comprehension
Sep 05, 2019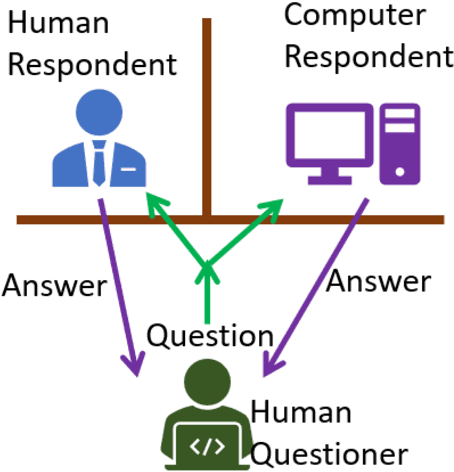
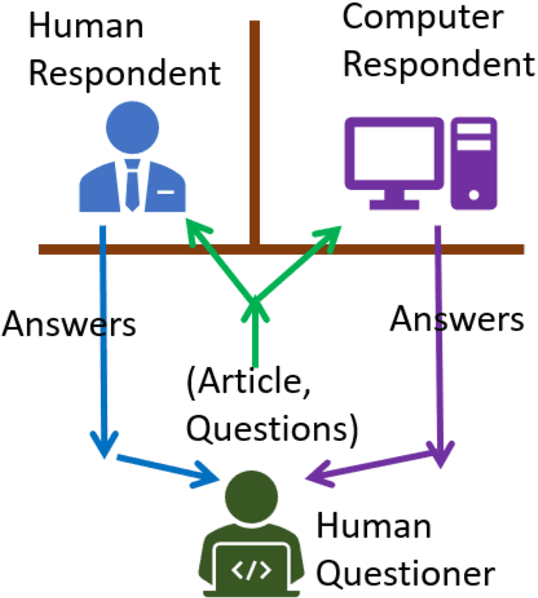
Reading comprehension is an important ability of human intelligence. Literacy and numeracy are two most essential foundation for people to succeed at study, at work and in life. Reading comprehension ability is a core component of literacy. In most of the education systems, developing reading comprehension ability is compulsory in the curriculum from year one to year 12. It is an indispensable ability in the dissemination of knowledge. With the emerging artificial intelligence, computers start to be able to read and understand like people in some context. They can even read better than human beings for some tasks, but have little clue in other tasks. It will be very beneficial if we can identify the levels of machine comprehension ability, which will direct us on the further improvement. Turing test is a well-known test of the difference between computer intelligence and human intelligence. In order to be able to compare the difference between people reading and machines reading, we proposed a test called (reading) Comprehension Ability Test (CAT).CAT is similar to Turing test, passing of which means we cannot differentiate people from algorithms in term of their comprehension ability. CAT has multiple levels showing the different abilities in reading comprehension, from identifying basic facts, performing inference, to understanding the intent and sentiment.