 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamouflage-aware Image-Text Retrieval via Expert Collaboration
Apr 01, 2026Camouflaged scene understanding (CSU) has attracted significant attention due to its broad practical implications. However, in this field, robust image-text cross-modal alignment remains under-explored, hindering deeper understanding of camouflaged scenarios and their related applications. To this end, we focus on the typical image-text retrieval task, and formulate a new task dubbed ``camouflage-aware image-text retrieval'' (CA-ITR). We first construct a dedicated camouflage image-text retrieval dataset (CamoIT), comprising $\sim$10.5K samples with multi-granularity textual annotations. Benchmark results conducted on CamoIT reveal the underlying challenges of CA-ITR for existing cutting-edge retrieval techniques, which are mainly caused by objects' camouflage properties as well as those complex image contents. As a solution, we propose a camouflage-expert collaborative network (CECNet), which features a dual-branch visual encoder: one branch captures holistic image representations, while the other incorporates a dedicated model to inject representations of camouflaged objects. A novel confidence-conditioned graph attention (C\textsuperscript{2}GA) mechanism is incorporated to exploit the complementarity across branches. Comparative experiments show that CECNet achieves $\sim$29% overall CA-ITR accuracy boost, surpassing seven representative retrieval models. The dataset and code will be available at https://github.com/jiangyao-scu/CA-ITR.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
TCIP: Threshold-Controlled Iterative Pyramid Network for Deformable Medical Image Registration
Oct 09, 2025Although pyramid networks have demonstrated superior performance in deformable medical image registration, their decoder architectures are inherently prone to propagating and accumulating anatomical structure misalignments. Moreover, most existing models do not adaptively determine the number of iterations for optimization under varying deformation requirements across images, resulting in either premature termination or excessive iterations that degrades registration accuracy. To effectively mitigate the accumulation of anatomical misalignments, we propose the Feature-Enhanced Residual Module (FERM) as the core component of each decoding layer in the pyramid network. FERM comprises three sequential blocks that extract anatomical semantic features, learn to suppress irrelevant features, and estimate the final deformation field, respectively. To adaptively determine the number of iterations for varying images, we propose the dual-stage Threshold-Controlled Iterative (TCI) strategy. In the first stage, TCI assesses registration stability and with asserted stability, it continues with the second stage to evaluate convergence. We coin the model that integrates FERM and TCI as Threshold-Controlled Iterative Pyramid (TCIP). Extensive experiments on three public brain MRI datasets and one abdomen CT dataset demonstrate that TCIP outperforms the state-of-the-art (SOTA) registration networks in terms of accuracy, while maintaining comparable inference speed and a compact model parameter size. Finally, we assess the generalizability of FERM and TCI by integrating them with existing registration networks and further conduct ablation studies to validate the effectiveness of these two proposed methods.
GELD: A Unified Neural Model for Efficiently Solving Traveling Salesman Problems Across Different Scales
Jun 07, 2025The Traveling Salesman Problem (TSP) is a well-known combinatorial optimization problem with broad real-world applications. Recent advancements in neural network-based TSP solvers have shown promising results. Nonetheless, these models often struggle to efficiently solve both small- and large-scale TSPs using the same set of pre-trained model parameters, limiting their practical utility. To address this issue, we introduce a novel neural TSP solver named GELD, built upon our proposed broad global assessment and refined local selection framework. Specifically, GELD integrates a lightweight Global-view Encoder (GE) with a heavyweight Local-view Decoder (LD) to enrich embedding representation while accelerating the decision-making process. Moreover, GE incorporates a novel low-complexity attention mechanism, allowing GELD to achieve low inference latency and scalability to larger-scale TSPs. Additionally, we propose a two-stage training strategy that utilizes training instances of different sizes to bolster GELD's generalization ability. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that GELD outperforms seven state-of-the-art models considering both solution quality and inference speed. Furthermore, GELD can be employed as a post-processing method to significantly elevate the quality of the solutions derived by existing neural TSP solvers via spending affordable additional computing time. Notably, GELD is shown as capable of solving TSPs with up to 744,710 nodes, first-of-its-kind to solve this large size TSP without relying on divide-and-conquer strategies to the best of our knowledge.
Efficient Heuristics Generation for Solving Combinatorial Optimization Problems Using Large Language Models
May 19, 2025


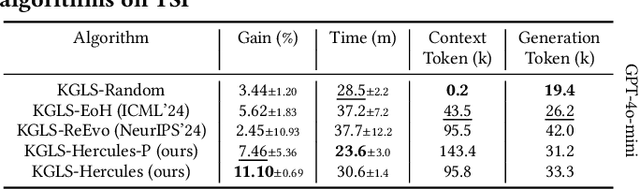
Recent studies exploited Large Language Models (LLMs) to autonomously generate heuristics for solving Combinatorial Optimization Problems (COPs), by prompting LLMs to first provide search directions and then derive heuristics accordingly. However, the absence of task-specific knowledge in prompts often leads LLMs to provide unspecific search directions, obstructing the derivation of well-performing heuristics. Moreover, evaluating the derived heuristics remains resource-intensive, especially for those semantically equivalent ones, often requiring omissible resource expenditure. To enable LLMs to provide specific search directions, we propose the Hercules algorithm, which leverages our designed Core Abstraction Prompting (CAP) method to abstract the core components from elite heuristics and incorporate them as prior knowledge in prompts. We theoretically prove the effectiveness of CAP in reducing unspecificity and provide empirical results in this work. To reduce computing resources required for evaluating the derived heuristics, we propose few-shot Performance Prediction Prompting (PPP), a first-of-its-kind method for the Heuristic Generation (HG) task. PPP leverages LLMs to predict the fitness values of newly derived heuristics by analyzing their semantic similarity to previously evaluated ones. We further develop two tailored mechanisms for PPP to enhance predictive accuracy and determine unreliable predictions, respectively. The use of PPP makes Hercules more resource-efficient and we name this variant Hercules-P. Extensive experiments across four HG tasks, five COPs, and eight LLMs demonstrate that Hercules outperforms the state-of-the-art LLM-based HG algorithms, while Hercules-P excels at minimizing required computing resources. In addition, we illustrate the effectiveness of CAP, PPP, and the other proposed mechanisms by conducting relevant ablation studies.
An Efficient Diffusion-based Non-Autoregressive Solver for Traveling Salesman Problem
Jan 23, 2025



Recent advances in neural models have shown considerable promise in solving Traveling Salesman Problems (TSPs) without relying on much hand-crafted engineering. However, while non-autoregressive (NAR) approaches benefit from faster inference through parallelism, they typically deliver solutions of inferior quality compared to autoregressive ones. To enhance the solution quality while maintaining fast inference, we propose DEITSP, a diffusion model with efficient iterations tailored for TSP that operates in a NAR manner. Firstly, we introduce a one-step diffusion model that integrates the controlled discrete noise addition process with self-consistency enhancement, enabling optimal solution prediction through simultaneous denoising of multiple solutions. Secondly, we design a dual-modality graph transformer to bolster the extraction and fusion of features from node and edge modalities, while further accelerating the inference with fewer layers. Thirdly, we develop an efficient iterative strategy that alternates between adding and removing noise to improve exploration compared to previous diffusion methods. Additionally, we devise a scheduling framework to progressively refine the solution space by adjusting noise levels, facilitating a smooth search for optimal solutions. Extensive experiments on real-world and large-scale TSP instances demonstrate that DEITSP performs favorably against existing neural approaches in terms of solution quality, inference latency, and generalization ability. Our code is available at $\href{https://github.com/DEITSP/DEITSP}{https://github.com/DEITSP/DEITSP}$.
AeroGen: Enhancing Remote Sensing Object Detection with Diffusion-Driven Data Generation
Nov 26, 2024
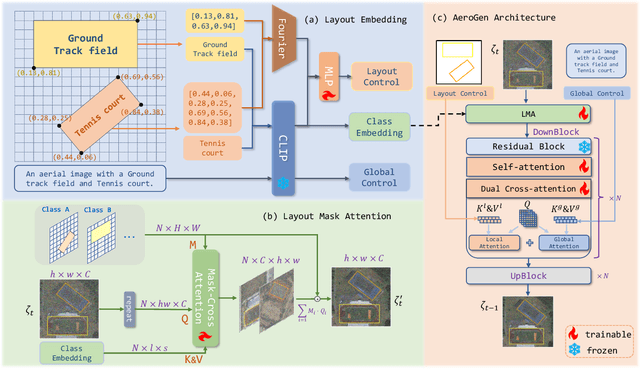
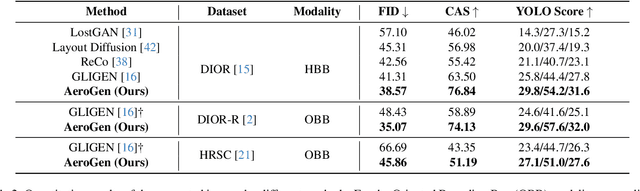
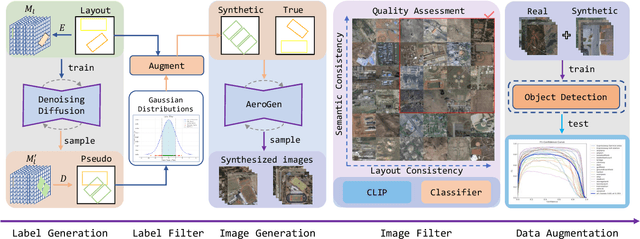
Remote sensing image object detection (RSIOD) aims to identify and locate specific objects within satellite or aerial imagery. However, there is a scarcity of labeled data in current RSIOD datasets, which significantly limits the performance of current detection algorithms. Although existing techniques, e.g., data augmentation and semi-supervised learning, can mitigate this scarcity issue to some extent, they are heavily dependent on high-quality labeled data and perform worse in rare object classes. To address this issue, this paper proposes a layout-controllable diffusion generative model (i.e. AeroGen) tailored for RSIOD. To our knowledge, AeroGen is the first model to simultaneously support horizontal and rotated bounding box condition generation, thus enabling the generation of high-quality synthetic images that meet specific layout and object category requirements. Additionally, we propose an end-to-end data augmentation framework that integrates a diversity-conditioned generator and a filtering mechanism to enhance both the diversity and quality of generated data. Experimental results demonstrate that the synthetic data produced by our method are of high quality and diversity. Furthermore, the synthetic RSIOD data can significantly improve the detection performance of existing RSIOD models, i.e., the mAP metrics on DIOR, DIOR-R, and HRSC datasets are improved by 3.7%, 4.3%, and 2.43%, respectively. The code is available at https://github.com/Sonettoo/AeroGen.
Hierarchical Spatio-Temporal Uncertainty Quantification for Distributed Energy Adoption
Nov 19, 2024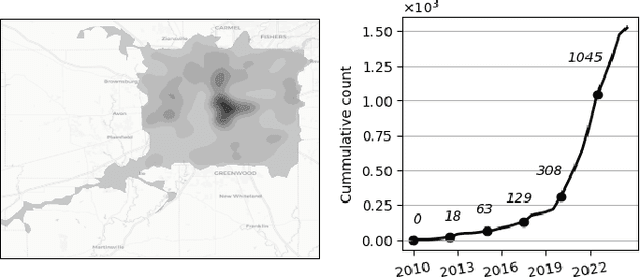
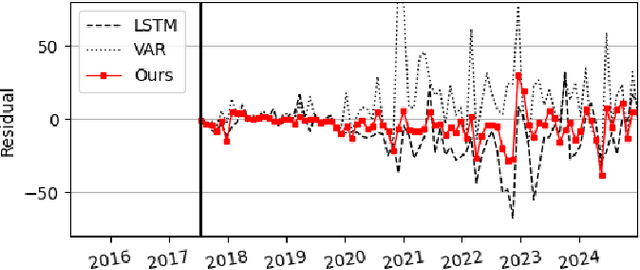
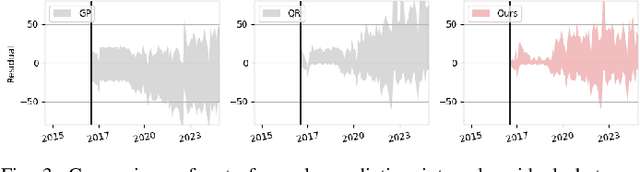
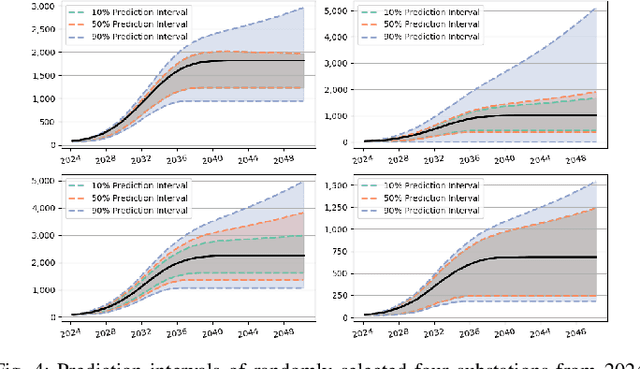
The rapid deployment of distributed energy resources (DER) has introduced significant spatio-temporal uncertainties in power grid management, necessitating accurate multilevel forecasting methods. However, existing approaches often produce overly conservative uncertainty intervals at individual spatial units and fail to properly capture uncertainties when aggregating predictions across different spatial scales. This paper presents a novel hierarchical spatio-temporal model based on the conformal prediction framework to address these challenges. Our approach generates circuit-level DER growth predictions and efficiently aggregates them to the substation level while maintaining statistical validity through a tailored non-conformity score. Applied to a decade of DER installation data from a local utility network, our method demonstrates superior performance over existing approaches, particularly in reducing prediction interval widths while maintaining coverage.
Improving Generalization of Neural Vehicle Routing Problem Solvers Through the Lens of Model Architecture
Jun 10, 2024
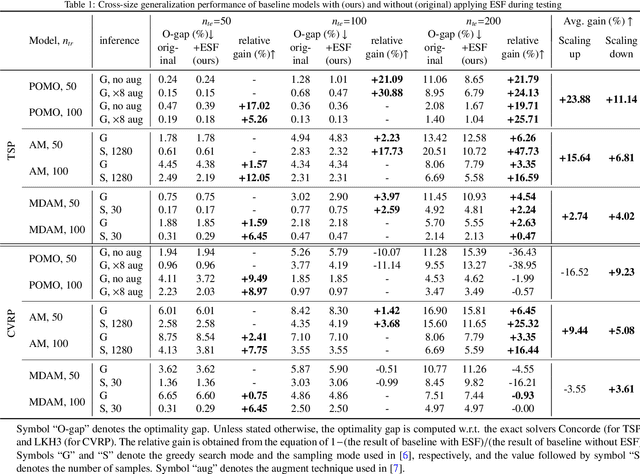
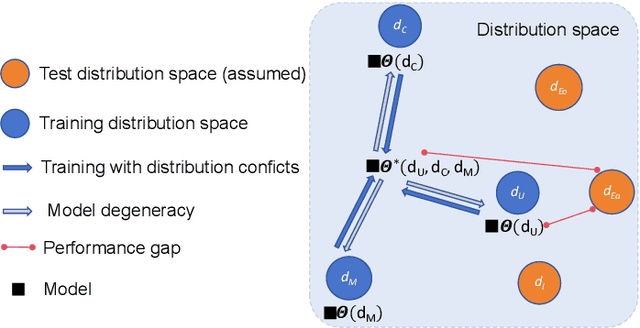
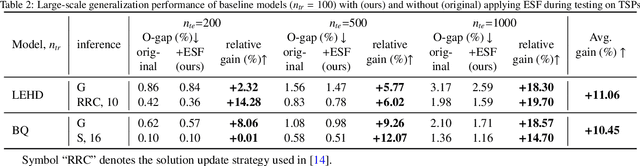
Neural models produce promising results when solving Vehicle Routing Problems (VRPs), but often fall short in generalization. Recent attempts to enhance model generalization often incur unnecessarily large training cost or cannot be directly applied to other models solving different VRP variants. To address these issues, we take a novel perspective on model architecture in this study. Specifically, we propose a plug-and-play Entropy-based Scaling Factor (ESF) and a Distribution-Specific (DS) decoder to enhance the size and distribution generalization, respectively. ESF adjusts the attention weight pattern of the model towards familiar ones discovered during training when solving VRPs of varying sizes. The DS decoder explicitly models VRPs of multiple training distribution patterns through multiple auxiliary light decoders, expanding the model representation space to encompass a broader range of distributional scenarios. We conduct extensive experiments on both synthetic and widely recognized real-world benchmarking datasets and compare the performance with seven baseline models. The results demonstrate the effectiveness of using ESF and DS decoder to obtain a more generalizable model and showcase their applicability to solve different VRP variants, i.e., travelling salesman problem and capacitated VRP. Notably, our proposed generic components require minimal computational resources, and can be effortlessly integrated into conventional generalization strategies to further elevate model generalization.
Neural Combinatorial Optimization Algorithms for Solving Vehicle Routing Problems: A Comprehensive Survey with Perspectives
Jun 01, 2024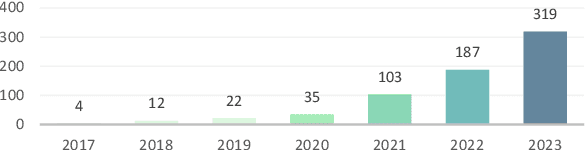
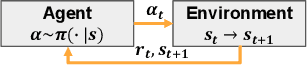
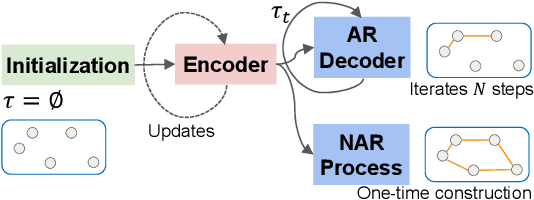
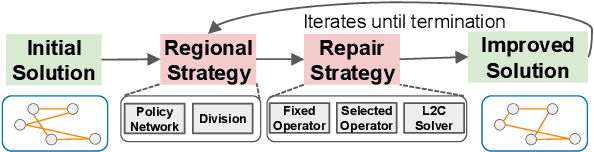
Although several surveys on Neural Combinatorial Optimization (NCO) solvers specifically designed to solve Vehicle Routing Problems (VRPs) have been conducted. These existing surveys did not cover the state-of-the-art (SOTA) NCO solvers emerged recently. More importantly, to provide a comprehensive taxonomy of NCO solvers with up-to-date coverage, based on our thorough review of relevant publications and preprints, we divide all NCO solvers into four distinct categories, namely Learning to Construct, Learning to Improve, Learning to Predict-Once, and Learning to Predict-Multiplicity solvers. Subsequently, we present the inadequacies of the SOTA solvers, including poor generalization, incapability to solve large-scale VRPs, inability to address most types of VRP variants simultaneously, and difficulty in comparing these NCO solvers with the conventional Operations Research algorithms. Simultaneously, we propose promising and viable directions to overcome these inadequacies. In addition, we compare the performance of representative NCO solvers from the Reinforcement, Supervised, and Unsupervised Learning paradigms across both small- and large-scale VRPs. Finally, following the proposed taxonomy, we provide an accompanying web page as a live repository for NCO solvers. Through this survey and the live repository, we hope to make the research community of NCO solvers for VRPs more thriving.