 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetting the duration of online A/B experiments
Aug 05, 2024In designing an online A/B experiment, it is crucial to select a sample size and duration that ensure the resulting confidence interval (CI) for the treatment effect is the right width to detect an effect of meaningful magnitude with sufficient statistical power without wasting resources. While the relationship between sample size and CI width is well understood, the effect of experiment duration on CI width remains less clear. This paper provides an analytical formula for the width of a CI based on a ratio treatment effect estimator as a function of both sample size (N) and duration (T). The formula is derived from a mixed effects model with two variance components. One component, referred to as the temporal variance, persists over time for experiments where the same users are kept in the same experiment arm across different days. The remaining error variance component, by contrast, decays to zero as T gets large. The formula we derive introduces a key parameter that we call the user-specific temporal correlation (UTC), which quantifies the relative sizes of the two variance components and can be estimated from historical experiments. Higher UTC indicates a slower decay in CI width over time. On the other hand, when the UTC is 0 -- as for experiments where users shuffle in and out of the experiment across days -- the CI width decays at the standard parametric 1/T rate. We also study how access to pre-period data for the users in the experiment affects the CI width decay. We show our formula closely explains CI widths on real A/B experiments at YouTube.
Neural Combinatorial Optimization Algorithms for Solving Vehicle Routing Problems: A Comprehensive Survey with Perspectives
Jun 01, 2024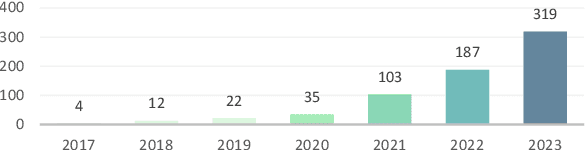
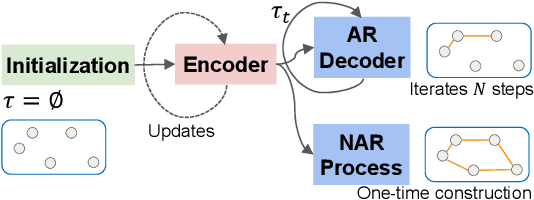
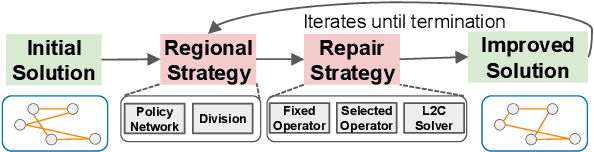
Although several surveys on Neural Combinatorial Optimization (NCO) solvers specifically designed to solve Vehicle Routing Problems (VRPs) have been conducted. These existing surveys did not cover the state-of-the-art (SOTA) NCO solvers emerged recently. More importantly, to provide a comprehensive taxonomy of NCO solvers with up-to-date coverage, based on our thorough review of relevant publications and preprints, we divide all NCO solvers into four distinct categories, namely Learning to Construct, Learning to Improve, Learning to Predict-Once, and Learning to Predict-Multiplicity solvers. Subsequently, we present the inadequacies of the SOTA solvers, including poor generalization, incapability to solve large-scale VRPs, inability to address most types of VRP variants simultaneously, and difficulty in comparing these NCO solvers with the conventional Operations Research algorithms. Simultaneously, we propose promising and viable directions to overcome these inadequacies. In addition, we compare the performance of representative NCO solvers from the Reinforcement, Supervised, and Unsupervised Learning paradigms across both small- and large-scale VRPs. Finally, following the proposed taxonomy, we provide an accompanying web page as a live repository for NCO solvers. Through this survey and the live repository, we hope to make the research community of NCO solvers for VRPs more thriving.