 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Inversion and Self-supervised Refinement for Radiology Report Generation
May 31, 2024Existing mainstream approaches follow the encoder-decoder paradigm for generating radiology reports. They focus on improving the network structure of encoders and decoders, which leads to two shortcomings: overlooking the modality gap and ignoring report content constraints. In this paper, we proposed Textual Inversion and Self-supervised Refinement (TISR) to address the above two issues. Specifically, textual inversion can project text and image into the same space by representing images as pseudo words to eliminate the cross-modeling gap. Subsequently, self-supervised refinement refines these pseudo words through contrastive loss computation between images and texts, enhancing the fidelity of generated reports to images. Notably, TISR is orthogonal to most existing methods, plug-and-play. We conduct experiments on two widely-used public datasets and achieve significant improvements on various baselines, which demonstrates the effectiveness and generalization of TISR. The code will be available soon.
Visual Attention Network for Low Dose CT
Oct 31, 2018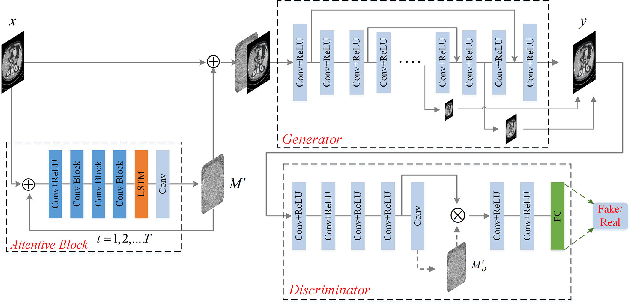
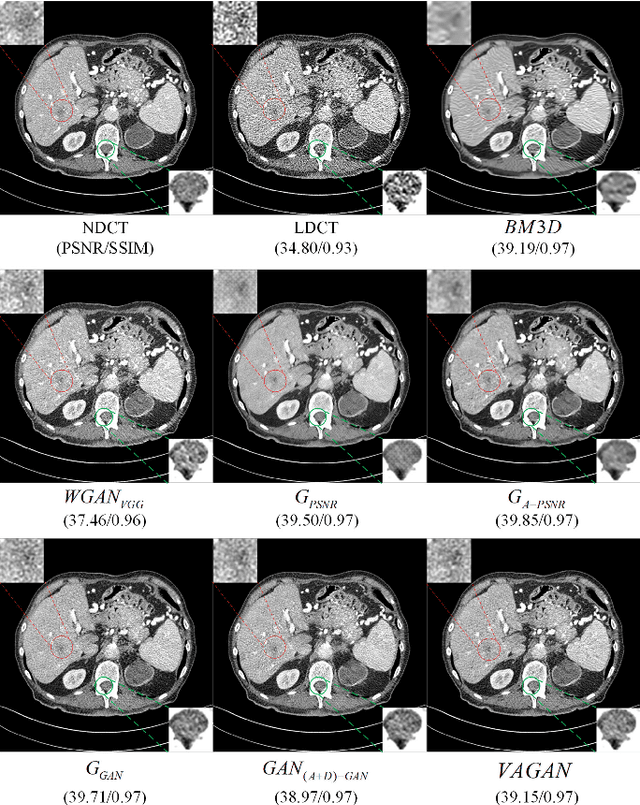
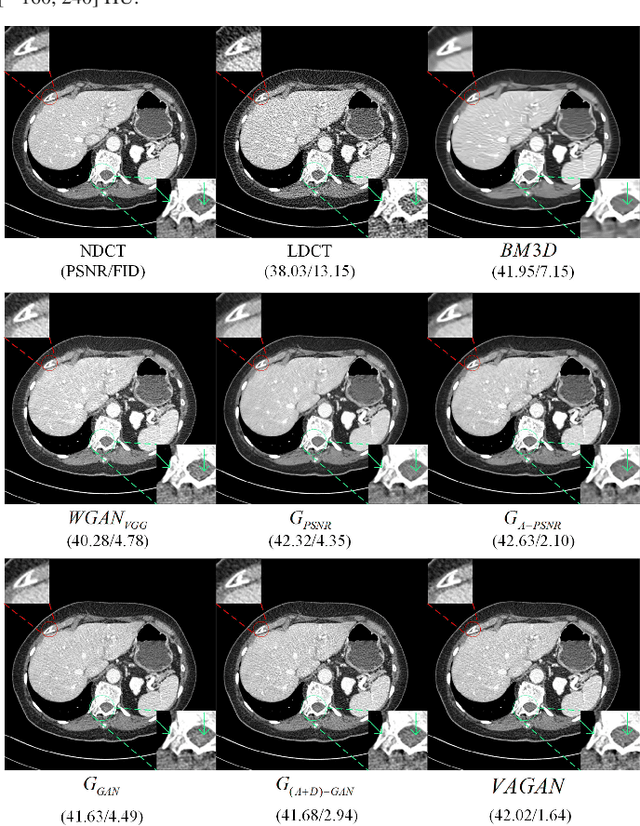

Noise and artifacts are intrinsic to low dose CT (LDCT) data acquisition, and will significantly affect the imaging performance. Perfect noise removal and image restoration is intractable in the context of LDCT due to the statistical and technical uncertainties. In this paper, we apply the generative adversarial network (GAN) framework with a visual attention mechanism to deal with this problem in a data-driven/machine learning fashion. Our main idea is to inject visual attention knowledge into the learning process of GAN to provide a powerful prior of the noise distribution. By doing this, both the generator and discriminator networks are empowered with visual attention information so they will not only pay special attention to noisy regions and surrounding structures but also explicitly assess the local consistency of the recovered regions. Our experiments qualitatively and quantitatively demonstrate the effectiveness of the proposed method with clinic CT images.
LEARN: Learned Experts' Assessment-based Reconstruction Network for Sparse-data CT
Feb 10, 2018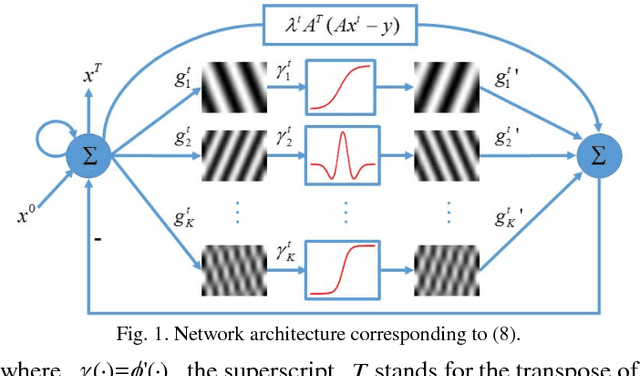
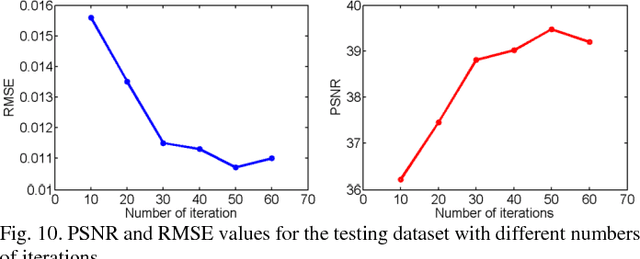
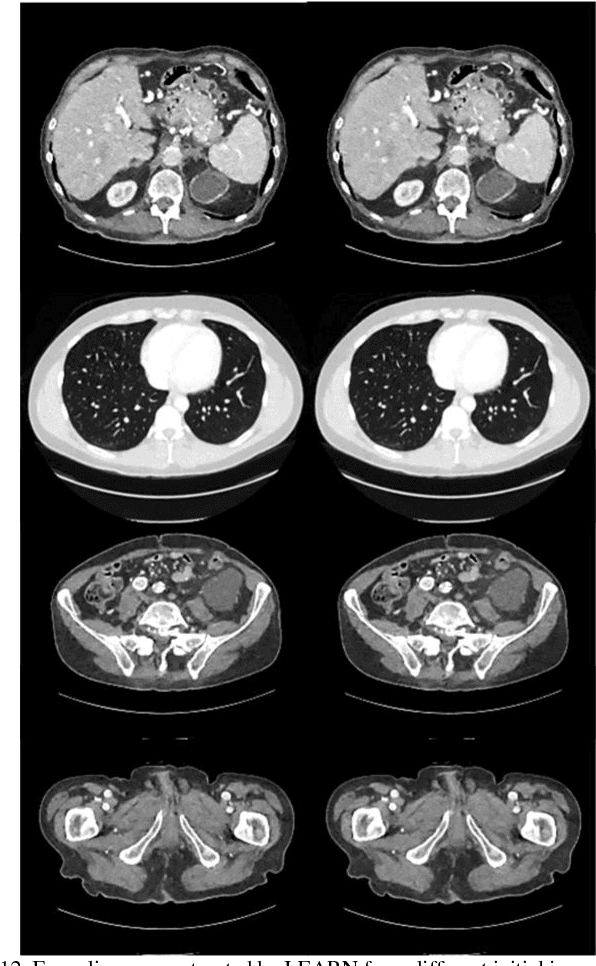
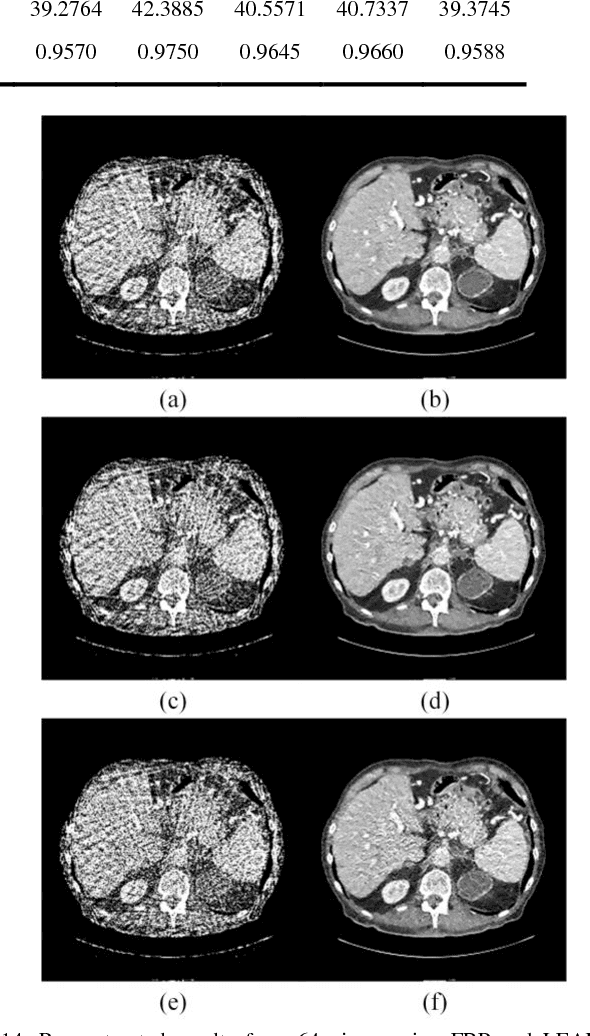
Compressive sensing (CS) has proved effective for tomographic reconstruction from sparsely collected data or under-sampled measurements, which are practically important for few-view CT, tomosynthesis, interior tomography, and so on. To perform sparse-data CT, the iterative reconstruction commonly use regularizers in the CS framework. Currently, how to choose the parameters adaptively for regularization is a major open problem. In this paper, inspired by the idea of machine learning especially deep learning, we unfold a state-of-the-art "fields of experts" based iterative reconstruction scheme up to a number of iterations for data-driven training, construct a Learned Experts' Assessment-based Reconstruction Network ("LEARN") for sparse-data CT, and demonstrate the feasibility and merits of our LEARN network. The experimental results with our proposed LEARN network produces a competitive performance with the well-known Mayo Clinic Low-Dose Challenge Dataset relative to several state-of-the-art methods, in terms of artifact reduction, feature preservation, and computational speed. This is consistent to our insight that because all the regularization terms and parameters used in the iterative reconstruction are now learned from the training data, our LEARN network utilizes application-oriented knowledge more effectively and recovers underlying images more favorably than competing algorithms. Also, the number of layers in the LEARN network is only 12, reducing the computational complexity of typical iterative algorithms by orders of magnitude.
Low-Dose CT with a Residual Encoder-Decoder Convolutional Neural Network
Jun 11, 2017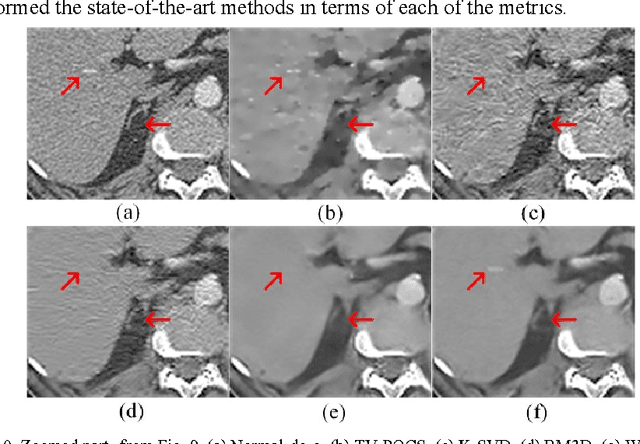

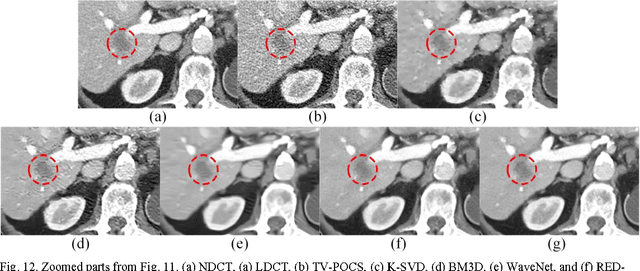
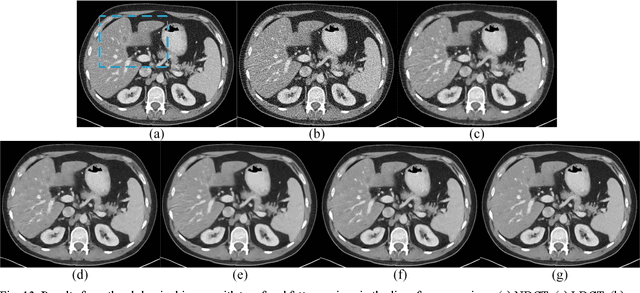
Given the potential X-ray radiation risk to the patient, low-dose CT has attracted a considerable interest in the medical imaging field. The current main stream low-dose CT methods include vendor-specific sinogram domain filtration and iterative reconstruction, but they need to access original raw data whose formats are not transparent to most users. Due to the difficulty of modeling the statistical characteristics in the image domain, the existing methods for directly processing reconstructed images cannot eliminate image noise very well while keeping structural details. Inspired by the idea of deep learning, here we combine the autoencoder, the deconvolution network, and shortcut connections into the residual encoder-decoder convolutional neural network (RED-CNN) for low-dose CT imaging. After patch-based training, the proposed RED-CNN achieves a competitive performance relative to the-state-of-art methods in both simulated and clinical cases. Especially, our method has been favorably evaluated in terms of noise suppression, structural preservation and lesion detection.
Low-dose CT denoising with convolutional neural network
Oct 02, 2016

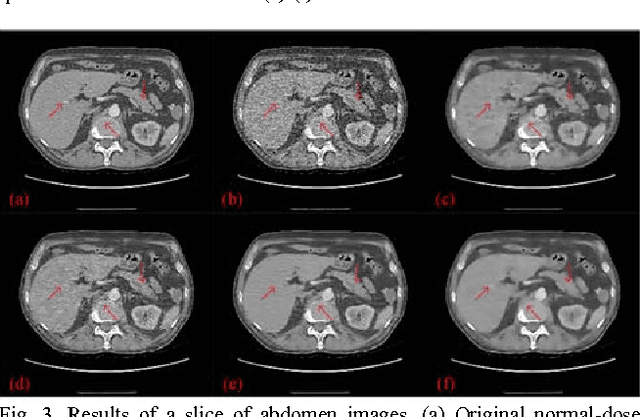

To reduce the potential radiation risk, low-dose CT has attracted much attention. However, simply lowering the radiation dose will lead to significant deterioration of the image quality. In this paper, we propose a noise reduction method for low-dose CT via deep neural network without accessing original projection data. A deep convolutional neural network is trained to transform low-dose CT images towards normal-dose CT images, patch by patch. Visual and quantitative evaluation demonstrates a competing performance of the proposed method.