 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Sampling Distribution Shift in Radio Map Estimation: A Trajectory-Aware Paradigm
May 27, 2026Learning-based radio map estimation (RME) plays a critical role in UAV-assisted wireless sensing, enabling tasks such as coverage prediction and network optimization. Most current methods assume an independently and identically distributed (i.i.d.) training and testing setting based on random sampling. However, practical UAV measurements are collected sequentially along feasible trajectories, resulting in highly structured and spatially correlated patterns. This mismatch introduces a sampling distribution shift that increases the intrinsic difficulty of spatial field recovery and compromises the generalization of models trained under i.i.d. assumptions. To mitigate this issue, we propose a trajectory-aware training paradigm based on Stochastic-Triggered Trajectory-Based Sampling (ST-TBS), which preserves trajectory continuity while introducing sampling variability. Moreover, from a statistical perspective, we show that trajectory-based sampling reduces spatial diversity and increases information redundancy compared to random sampling. Extensive experiments on the RadioMapSeer and SpectrumNet datasets demonstrate that models trained with random sampling suffer significant performance degradation under trajectory-based observations, with RMSE increasing from 0.0391 to 0.2632 on SpectrumNet. Conversely, our proposed ST-TBS method effectively reduces the RMSE to 0.0571. These results highlight the necessity of aligning training and deployment sampling distributions for reliable RME.
From Prediction to Diagnosis: Reasoning-Aware AI for Photovoltaic Defect Inspection
Mar 24, 2026Reliable photovoltaic defect identification is essential for maintaining energy yield, ensuring warranty compliance, and enabling scalable inspection of rapidly expanding solar fleets. Although recent advances in computer vision have improved automated defect detection, most existing systems operate as opaque classifiers that provide limited diagnostic insight for high-stakes energy infrastructure. Here we introduce REVL-PV, a vision-language framework that embeds domain-specific diagnostic reasoning into multimodal learning across electroluminescence, thermal, and visible-light imagery. By requiring the model to link visual evidence to plausible defect mechanisms before classification, the framework produces structured diagnostic reports aligned with professional photovoltaic inspection practice. Evaluated on 1,927 real-world modules spanning eight defect categories, REVL-PV achieves 93\% classification accuracy while producing interpretable diagnostic rationales and maintaining strong robustness under realistic image corruptions. A blind concordance study with a certified solar inspection expert shows strong semantic alignment between model explanations and expert assessments across defect identification, root-cause attribution, and visual descriptions. These results demonstrate that reasoning-aware multimodal learning establishes a general paradigm for trustworthy AI-assisted inspection of photovoltaic energy infrastructure.
Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
Feb 13, 2026In this report, we introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on large-scale cross-embodiment robot trajectories and vision-language data, endowing it with broad and generalizable action-generation capabilities while avoiding catastrophic forgetting of the visual-semantic knowledge of the underlying pre-trained VLM. During post-training, we propose several techniques for training the VLA model for asynchronous execution to address the inference latency during real-robot rollouts. During deployment, we carefully align the timesteps of consecutive predicted action chunks to ensure continuous and seamless real-time rollouts. We evaluate Xiaomi-Robotics-0 extensively in simulation benchmarks and on two challenging real-robot tasks that require precise and dexterous bimanual manipulation. Results show that our method achieves state-of-the-art performance across all simulation benchmarks. Moreover, Xiaomi-Robotics-0 can roll out fast and smoothly on real robots using a consumer-grade GPU, achieving high success rates and throughput on both real-robot tasks. To facilitate future research, code and model checkpoints are open-sourced at https://xiaomi-robotics-0.github.io
Retrieval Augmented Comic Image Generation
Jun 14, 2025



We present RaCig, a novel system for generating comic-style image sequences with consistent characters and expressive gestures. RaCig addresses two key challenges: (1) maintaining character identity and costume consistency across frames, and (2) producing diverse and vivid character gestures. Our approach integrates a retrieval-based character assignment module, which aligns characters in textual prompts with reference images, and a regional character injection mechanism that embeds character features into specified image regions. Experimental results demonstrate that RaCig effectively generates engaging comic narratives with coherent characters and dynamic interactions. The source code will be publicly available to support further research in this area.
7ABAW-Compound Expression Recognition via Curriculum Learning
Mar 11, 2025With the advent of deep learning, expression recognition has made significant advancements. However, due to the limited availability of annotated compound expression datasets and the subtle variations of compound expressions, Compound Emotion Recognition (CE) still holds considerable potential for exploration. To advance this task, the 7th Affective Behavior Analysis in-the-wild (ABAW) competition introduces the Compound Expression Challenge based on C-EXPR-DB, a limited dataset without labels. In this paper, we present a curriculum learning-based framework that initially trains the model on single-expression tasks and subsequently incorporates multi-expression data. This design ensures that our model first masters the fundamental features of basic expressions before being exposed to the complexities of compound emotions. Specifically, our designs can be summarized as follows: 1) Single-Expression Pre-training: The model is first trained on datasets containing single expressions to learn the foundational facial features associated with basic emotions. 2) Dynamic Compound Expression Generation: Given the scarcity of annotated compound expression datasets, we employ CutMix and Mixup techniques on the original single-expression images to create hybrid images exhibiting characteristics of multiple basic emotions. 3) Incremental Multi-Expression Integration: After performing well on single-expression tasks, the model is progressively exposed to multi-expression data, allowing the model to adapt to the complexity and variability of compound expressions. The official results indicate that our method achieves the \textbf{best} performance in this competition track with an F-score of 0.6063. Our code is released at https://github.com/YenanLiu/ABAW7th.
Global-Decision-Focused Neural ODEs for Proactive Grid Resilience Management
Feb 25, 2025Extreme hazard events such as wildfires and hurricanes increasingly threaten power systems, causing widespread outages and disrupting critical services. Recently, predict-then-optimize approaches have gained traction in grid operations, where system functionality forecasts are first generated and then used as inputs for downstream decision-making. However, this two-stage method often results in a misalignment between prediction and optimization objectives, leading to suboptimal resource allocation. To address this, we propose predict-all-then-optimize-globally (PATOG), a framework that integrates outage prediction with globally optimized interventions. At its core, our global-decision-focused (GDF) neural ODE model captures outage dynamics while optimizing resilience strategies in a decision-aware manner. Unlike conventional methods, our approach ensures spatially and temporally coherent decision-making, improving both predictive accuracy and operational efficiency. Experiments on synthetic and real-world datasets demonstrate significant improvements in outage prediction consistency and grid resilience.
Spatio-Temporal Conformal Prediction for Power Outage Data
Nov 26, 2024In recent years, increasingly unpredictable and severe global weather patterns have frequently caused long-lasting power outages. Building resilience, the ability to withstand, adapt to, and recover from major disruptions, has become crucial for the power industry. To enable rapid recovery, accurately predicting future outage numbers is essential. Rather than relying on simple point estimates, we analyze extensive quarter-hourly outage data and develop a graph conformal prediction method that delivers accurate prediction regions for outage numbers across the states for a time period. We demonstrate the effectiveness of this method through extensive numerical experiments in several states affected by extreme weather events that led to widespread outages.
Hierarchical Spatio-Temporal Uncertainty Quantification for Distributed Energy Adoption
Nov 19, 2024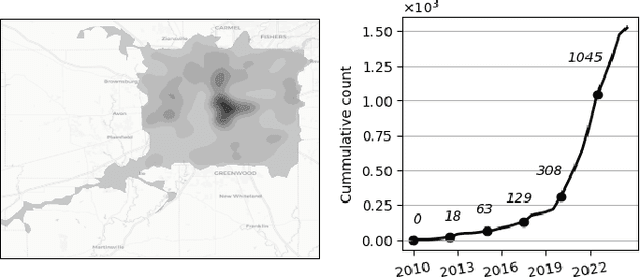
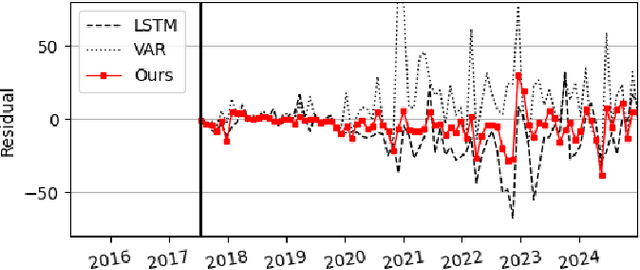
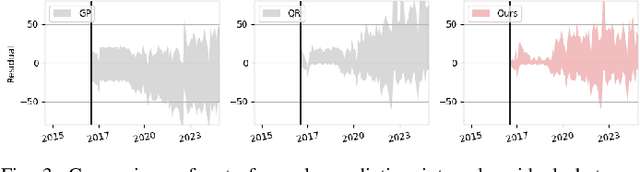
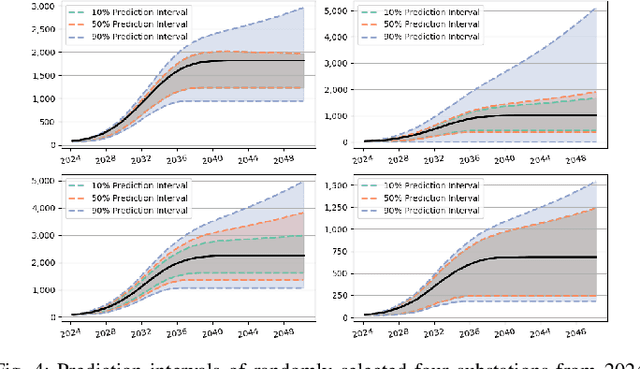
The rapid deployment of distributed energy resources (DER) has introduced significant spatio-temporal uncertainties in power grid management, necessitating accurate multilevel forecasting methods. However, existing approaches often produce overly conservative uncertainty intervals at individual spatial units and fail to properly capture uncertainties when aggregating predictions across different spatial scales. This paper presents a novel hierarchical spatio-temporal model based on the conformal prediction framework to address these challenges. Our approach generates circuit-level DER growth predictions and efficiently aggregates them to the substation level while maintaining statistical validity through a tailored non-conformity score. Applied to a decade of DER installation data from a local utility network, our method demonstrates superior performance over existing approaches, particularly in reducing prediction interval widths while maintaining coverage.
Affective Behaviour Analysis via Progressive Learning
Jul 26, 2024



Affective Behavior Analysis aims to develop emotionally intelligent technology that can recognize and respond to human emotions. To advance this, the 7th Affective Behavior Analysis in-the-wild (ABAW) competition establishes two tracks: i.e., the Multi-task Learning (MTL) Challenge and the Compound Expression (CE) challenge based on Aff-Wild2 and C-EXPR-DB datasets. In this paper, we present our methods and experimental results for the two competition tracks. Specifically, it can be summarized in the following four aspects: 1) To attain high-quality facial features, we train a Masked-Auto Encoder in a self-supervised manner. 2) We devise a temporal convergence module to capture the temporal information between video frames and explore the impact of window size and sequence length on each sub-task. 3) To facilitate the joint optimization of various sub-tasks, we explore the impact of sub-task joint training and feature fusion from individual tasks on each task performance improvement. 4) We utilize curriculum learning to transition the model from recognizing single expressions to recognizing compound expressions, thereby improving the accuracy of compound expression recognition. Extensive experiments demonstrate the superiority of our designs.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.