 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreDN: Spectral Disentanglement for Time Series Forecasting via Learnable Frequency Decomposition
Nov 14, 2025Time series forecasting is essential in a wide range of real world applications. Recently, frequency-domain methods have attracted increasing interest for their ability to capture global dependencies. However, when applied to non-stationary time series, these methods encounter the $\textit{spectral entanglement}$ and the computational burden of complex-valued learning. The $\textit{spectral entanglement}$ refers to the overlap of trends, periodicities, and noise across the spectrum due to $\textit{spectral leakage}$ and the presence of non-stationarity. However, existing decompositions are not suited to resolving spectral entanglement. To address this, we propose the Frequency Decomposition Network (FreDN), which introduces a learnable Frequency Disentangler module to separate trend and periodic components directly in the frequency domain. Furthermore, we propose a theoretically supported ReIm Block to reduce the complexity of complex-valued operations while maintaining performance. We also re-examine the frequency-domain loss function and provide new theoretical insights into its effectiveness. Extensive experiments on seven long-term forecasting benchmarks demonstrate that FreDN outperforms state-of-the-art methods by up to 10\%. Furthermore, compared with standard complex-valued architectures, our real-imaginary shared-parameter design reduces the parameter count and computational cost by at least 50\%.
CMamba: Learned Image Compression with State Space Models
Feb 07, 2025Learned Image Compression (LIC) has explored various architectures, such as Convolutional Neural Networks (CNNs) and transformers, in modeling image content distributions in order to achieve compression effectiveness. However, achieving high rate-distortion performance while maintaining low computational complexity (\ie, parameters, FLOPs, and latency) remains challenging. In this paper, we propose a hybrid Convolution and State Space Models (SSMs) based image compression framework, termed \textit{CMamba}, to achieve superior rate-distortion performance with low computational complexity. Specifically, CMamba introduces two key components: a Content-Adaptive SSM (CA-SSM) module and a Context-Aware Entropy (CAE) module. First, we observed that SSMs excel in modeling overall content but tend to lose high-frequency details. In contrast, CNNs are proficient at capturing local details. Motivated by this, we propose the CA-SSM module that can dynamically fuse global content extracted by SSM blocks and local details captured by CNN blocks in both encoding and decoding stages. As a result, important image content is well preserved during compression. Second, our proposed CAE module is designed to reduce spatial and channel redundancies in latent representations after encoding. Specifically, our CAE leverages SSMs to parameterize the spatial content in latent representations. Benefiting from SSMs, CAE significantly improves spatial compression efficiency while reducing spatial content redundancies. Moreover, along the channel dimension, CAE reduces inter-channel redundancies of latent representations via an autoregressive manner, which can fully exploit prior knowledge from previous channels without sacrificing efficiency. Experimental results demonstrate that CMamba achieves superior rate-distortion performance.
FlashVTG: Feature Layering and Adaptive Score Handling Network for Video Temporal Grounding
Dec 18, 2024
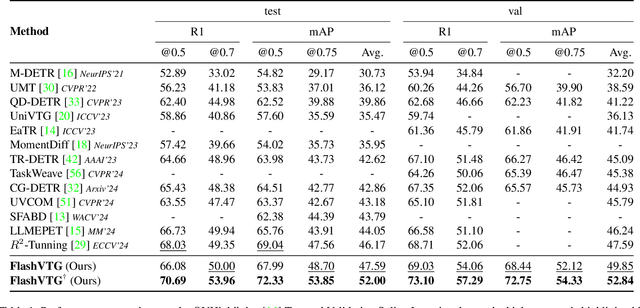

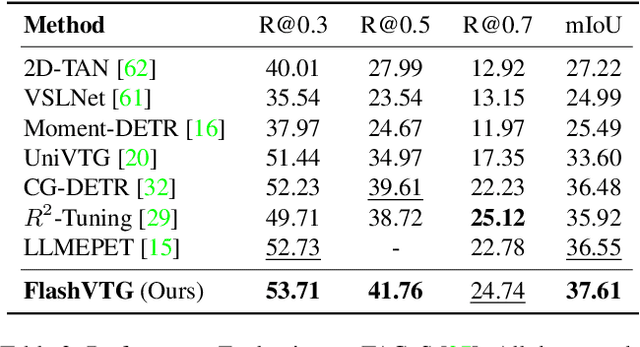
Text-guided Video Temporal Grounding (VTG) aims to localize relevant segments in untrimmed videos based on textual descriptions, encompassing two subtasks: Moment Retrieval (MR) and Highlight Detection (HD). Although previous typical methods have achieved commendable results, it is still challenging to retrieve short video moments. This is primarily due to the reliance on sparse and limited decoder queries, which significantly constrain the accuracy of predictions. Furthermore, suboptimal outcomes often arise because previous methods rank predictions based on isolated predictions, neglecting the broader video context. To tackle these issues, we introduce FlashVTG, a framework featuring a Temporal Feature Layering (TFL) module and an Adaptive Score Refinement (ASR) module. The TFL module replaces the traditional decoder structure to capture nuanced video content variations across multiple temporal scales, while the ASR module improves prediction ranking by integrating context from adjacent moments and multi-temporal-scale features. Extensive experiments demonstrate that FlashVTG achieves state-of-the-art performance on four widely adopted datasets in both MR and HD. Specifically, on the QVHighlights dataset, it boosts mAP by 5.8% for MR and 3.3% for HD. For short-moment retrieval, FlashVTG increases mAP to 125% of previous SOTA performance. All these improvements are made without adding training burdens, underscoring its effectiveness. Our code is available at https://github.com/Zhuo-Cao/FlashVTG.
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
Diverse Sign Language Translation
Oct 25, 2024



Like spoken languages, a single sign language expression could correspond to multiple valid textual interpretations. Hence, learning a rigid one-to-one mapping for sign language translation (SLT) models might be inadequate, particularly in the case of limited data. In this work, we introduce a Diverse Sign Language Translation (DivSLT) task, aiming to generate diverse yet accurate translations for sign language videos. Firstly, we employ large language models (LLM) to generate multiple references for the widely-used CSL-Daily and PHOENIX14T SLT datasets. Here, native speakers are only invited to touch up inaccurate references, thus significantly improving the annotation efficiency. Secondly, we provide a benchmark model to spur research in this task. Specifically, we investigate multi-reference training strategies to enable our DivSLT model to achieve diverse translations. Then, to enhance translation accuracy, we employ the max-reward-driven reinforcement learning objective that maximizes the reward of the translated result. Additionally, we utilize multiple metrics to assess the accuracy, diversity, and semantic precision of the DivSLT task. Experimental results on the enriched datasets demonstrate that our DivSLT method achieves not only better translation performance but also diverse translation results.
TokenBinder: Text-Video Retrieval with One-to-Many Alignment Paradigm
Sep 30, 2024



Text-Video Retrieval (TVR) methods typically match query-candidate pairs by aligning text and video features in coarse-grained, fine-grained, or combined (coarse-to-fine) manners. However, these frameworks predominantly employ a one(query)-to-one(candidate) alignment paradigm, which struggles to discern nuanced differences among candidates, leading to frequent mismatches. Inspired by Comparative Judgement in human cognitive science, where decisions are made by directly comparing items rather than evaluating them independently, we propose TokenBinder. This innovative two-stage TVR framework introduces a novel one-to-many coarse-to-fine alignment paradigm, imitating the human cognitive process of identifying specific items within a large collection. Our method employs a Focused-view Fusion Network with a sophisticated cross-attention mechanism, dynamically aligning and comparing features across multiple videos to capture finer nuances and contextual variations. Extensive experiments on six benchmark datasets confirm that TokenBinder substantially outperforms existing state-of-the-art methods. These results demonstrate its robustness and the effectiveness of its fine-grained alignment in bridging intra- and inter-modality information gaps in TVR tasks.
Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions
Aug 08, 2024



This paper considers a scenario in city navigation: an AI agent is provided with language descriptions of the goal location with respect to some well-known landmarks; By only observing the scene around, including recognizing landmarks and road network connections, the agent has to make decisions to navigate to the goal location without instructions. This problem is very challenging, because it requires agent to establish self-position and acquire spatial representation of complex urban environment, where landmarks are often invisible. In the absence of navigation instructions, such abilities are vital for the agent to make high-quality decisions in long-range city navigation. With the emergent reasoning ability of large language models (LLMs), a tempting baseline is to prompt LLMs to "react" on each observation and make decisions accordingly. However, this baseline has very poor performance that the agent often repeatedly visits same locations and make short-sighted, inconsistent decisions. To address these issues, this paper introduces a novel agentic workflow featured by its abilities to perceive, reflect and plan. Specifically, we find LLaVA-7B can be fine-tuned to perceive the direction and distance of landmarks with sufficient accuracy for city navigation. Moreover, reflection is achieved through a memory mechanism, where past experiences are stored and can be retrieved with current perception for effective decision argumentation. Planning uses reflection results to produce long-term plans, which can avoid short-sighted decisions in long-range navigation. We show the designed workflow significantly improves navigation ability of the LLM agent compared with the state-of-the-art baselines.
Affective Behaviour Analysis via Integrating Multi-Modal Knowledge
Mar 16, 2024



Affective Behavior Analysis aims to facilitate technology emotionally smart, creating a world where devices can understand and react to our emotions as humans do. To comprehensively evaluate the authenticity and applicability of emotional behavior analysis techniques in natural environments, the 6th competition on Affective Behavior Analysis in-the-wild (ABAW) utilizes the Aff-Wild2, Hume-Vidmimic2, and C-EXPR-DB datasets to set up five competitive tracks, i.e., Valence-Arousal (VA) Estimation, Expression (EXPR) Recognition, Action Unit (AU) Detection, Compound Expression (CE) Recognition, and Emotional Mimicry Intensity (EMI) Estimation. In this paper, we present our method designs for the five tasks. Specifically, our design mainly includes three aspects: 1) Utilizing a transformer-based feature fusion module to fully integrate emotional information provided by audio signals, visual images, and transcripts, offering high-quality expression features for the downstream tasks. 2) To achieve high-quality facial feature representations, we employ Masked-Auto Encoder as the visual features extraction model and fine-tune it with our facial dataset. 3) Considering the complexity of the video collection scenes, we conduct a more detailed dataset division based on scene characteristics and train the classifier for each scene. Extensive experiments demonstrate the superiority of our designs.
Divide and Ensemble: Progressively Learning for the Unknown
Oct 09, 2023
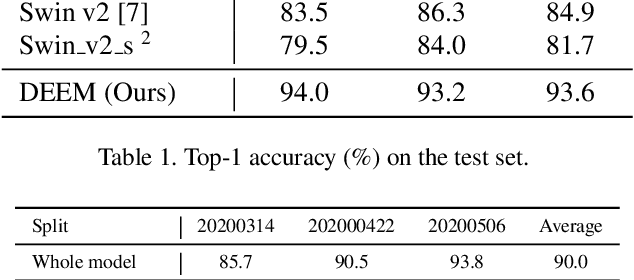


In the wheat nutrient deficiencies classification challenge, we present the DividE and EnseMble (DEEM) method for progressive test data predictions. We find that (1) test images are provided in the challenge; (2) samples are equipped with their collection dates; (3) the samples of different dates show notable discrepancies. Based on the findings, we partition the dataset into discrete groups by the dates and train models on each divided group. We then adopt the pseudo-labeling approach to label the test data and incorporate those with high confidence into the training set. In pseudo-labeling, we leverage models ensemble with different architectures to enhance the reliability of predictions. The pseudo-labeling and ensembled model training are iteratively conducted until all test samples are labeled. Finally, the separated models for each group are unified to obtain the model for the whole dataset. Our method achieves an average of 93.6\% Top-1 test accuracy~(94.0\% on WW2020 and 93.2\% on WR2021) and wins the 1$st$ place in the Deep Nutrient Deficiency Challenge~\footnote{https://cvppa2023.github.io/challenges/}.
When 3D Bounding-Box Meets SAM: Point Cloud Instance Segmentation with Weak-and-Noisy Supervision
Sep 02, 2023

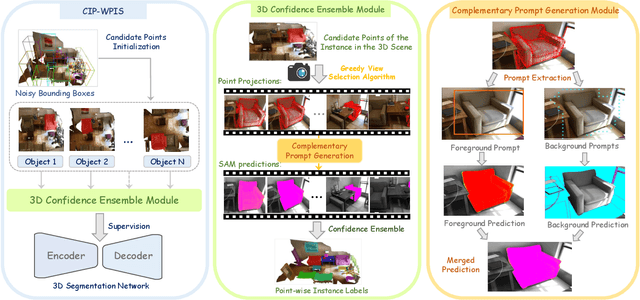

Learning from bounding-boxes annotations has shown great potential in weakly-supervised 3D point cloud instance segmentation. However, we observed that existing methods would suffer severe performance degradation with perturbed bounding box annotations. To tackle this issue, we propose a complementary image prompt-induced weakly-supervised point cloud instance segmentation (CIP-WPIS) method. CIP-WPIS leverages pretrained knowledge embedded in the 2D foundation model SAM and 3D geometric prior to achieve accurate point-wise instance labels from the bounding box annotations. Specifically, CP-WPIS first selects image views in which 3D candidate points of an instance are fully visible. Then, we generate complementary background and foreground prompts from projections to obtain SAM 2D instance mask predictions. According to these, we assign the confidence values to points indicating the likelihood of points belonging to the instance. Furthermore, we utilize 3D geometric homogeneity provided by superpoints to decide the final instance label assignments. In this fashion, we achieve high-quality 3D point-wise instance labels. Extensive experiments on both Scannet-v2 and S3DIS benchmarks demonstrate that our method is robust against noisy 3D bounding-box annotations and achieves state-of-the-art performance.