 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-GS: Real-time Gaussian Splatting for Mobile Devices
Mar 12, 20263D Gaussian Splatting (3DGS) has emerged as a powerful representation for high-quality rendering across a wide range of applications.However, its high computational demands and large storage costs pose significant challenges for deployment on mobile devices. In this work, we propose a mobile-tailored real-time Gaussian Splatting method, dubbed Mobile-GS, enabling efficient inference of Gaussian Splatting on edge devices. Specifically, we first identify alpha blending as the primary computational bottleneck, since it relies on the time-consuming Gaussian depth sorting process. To solve this issue, we propose a depth-aware order-independent rendering scheme that eliminates the need for sorting, thereby substantially accelerating rendering. Although this order-independent rendering improves rendering speed, it may introduce transparency artifacts in regions with overlapping geometry due to the scarcity of rendering order. To address this problem, we propose a neural view-dependent enhancement strategy, enabling more accurate modeling of view-dependent effects conditioned on viewing direction, 3D Gaussian geometry, and appearance attributes. In this way, Mobile-GS can achieve both high-quality and real-time rendering. Furthermore, to facilitate deployment on memory-constrained mobile platforms, we also introduce first-order spherical harmonics distillation, a neural vector quantization technique, and a contribution-based pruning strategy to reduce the number of Gaussian primitives and compress the 3D Gaussian representation with the assistance of neural networks. Extensive experiments demonstrate that our proposed Mobile-GS achieves real-time rendering and compact model size while preserving high visual quality, making it well-suited for mobile applications.
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
MVGS: Multi-view-regulated Gaussian Splatting for Novel View Synthesis
Oct 02, 2024



Recent works in volume rendering, \textit{e.g.} NeRF and 3D Gaussian Splatting (3DGS), significantly advance the rendering quality and efficiency with the help of the learned implicit neural radiance field or 3D Gaussians. Rendering on top of an explicit representation, the vanilla 3DGS and its variants deliver real-time efficiency by optimizing the parametric model with single-view supervision per iteration during training which is adopted from NeRF. Consequently, certain views are overfitted, leading to unsatisfying appearance in novel-view synthesis and imprecise 3D geometries. To solve aforementioned problems, we propose a new 3DGS optimization method embodying four key novel contributions: 1) We transform the conventional single-view training paradigm into a multi-view training strategy. With our proposed multi-view regulation, 3D Gaussian attributes are further optimized without overfitting certain training views. As a general solution, we improve the overall accuracy in a variety of scenarios and different Gaussian variants. 2) Inspired by the benefit introduced by additional views, we further propose a cross-intrinsic guidance scheme, leading to a coarse-to-fine training procedure concerning different resolutions. 3) Built on top of our multi-view regulated training, we further propose a cross-ray densification strategy, densifying more Gaussian kernels in the ray-intersect regions from a selection of views. 4) By further investigating the densification strategy, we found that the effect of densification should be enhanced when certain views are distinct dramatically. As a solution, we propose a novel multi-view augmented densification strategy, where 3D Gaussians are encouraged to get densified to a sufficient number accordingly, resulting in improved reconstruction accuracy.
DreamCar: Leveraging Car-specific Prior for in-the-wild 3D Car Reconstruction
Jul 24, 2024



Self-driving industries usually employ professional artists to build exquisite 3D cars. However, it is expensive to craft large-scale digital assets. Since there are already numerous datasets available that contain a vast number of images of cars, we focus on reconstructing high-quality 3D car models from these datasets. However, these datasets only contain one side of cars in the forward-moving scene. We try to use the existing generative models to provide more supervision information, but they struggle to generalize well in cars since they are trained on synthetic datasets not car-specific. In addition, The reconstructed 3D car texture misaligns due to a large error in camera pose estimation when dealing with in-the-wild images. These restrictions make it challenging for previous methods to reconstruct complete 3D cars. To address these problems, we propose a novel method, named DreamCar, which can reconstruct high-quality 3D cars given a few images even a single image. To generalize the generative model, we collect a car dataset, named Car360, with over 5,600 vehicles. With this dataset, we make the generative model more robust to cars. We use this generative prior specific to the car to guide its reconstruction via Score Distillation Sampling. To further complement the supervision information, we utilize the geometric and appearance symmetry of cars. Finally, we propose a pose optimization method that rectifies poses to tackle texture misalignment. Extensive experiments demonstrate that our method significantly outperforms existing methods in reconstructing high-quality 3D cars. \href{https://xiaobiaodu.github.io/dreamcar-project/}{Our code is available.}
3DRealCar: An In-the-wild RGB-D Car Dataset with 360-degree Views
Jun 07, 2024

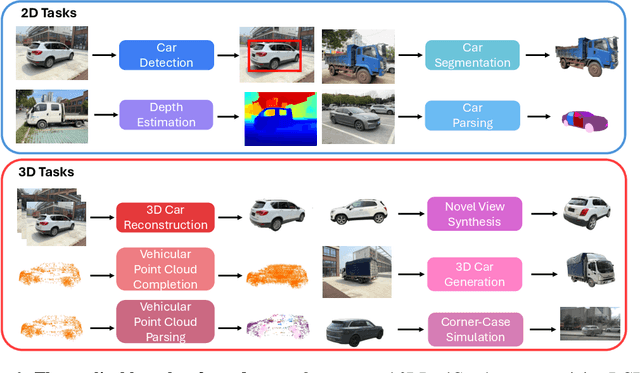
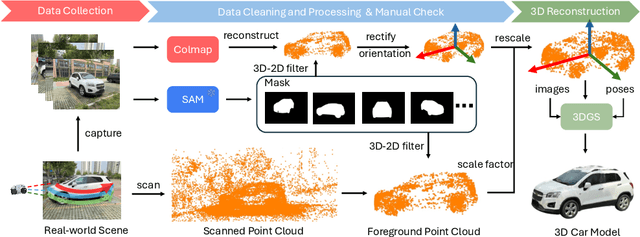
3D cars are commonly used in self-driving systems, virtual/augmented reality, and games. However, existing 3D car datasets are either synthetic or low-quality, presenting a significant gap toward the high-quality real-world 3D car datasets and limiting their applications in practical scenarios. In this paper, we propose the first large-scale 3D real car dataset, termed 3DRealCar, offering three distinctive features. (1) \textbf{High-Volume}: 2,500 cars are meticulously scanned by 3D scanners, obtaining car images and point clouds with real-world dimensions; (2) \textbf{High-Quality}: Each car is captured in an average of 200 dense, high-resolution 360-degree RGB-D views, enabling high-fidelity 3D reconstruction; (3) \textbf{High-Diversity}: The dataset contains various cars from over 100 brands, collected under three distinct lighting conditions, including reflective, standard, and dark. Additionally, we offer detailed car parsing maps for each instance to promote research in car parsing tasks. Moreover, we remove background point clouds and standardize the car orientation to a unified axis for the reconstruction only on cars without background and controllable rendering. We benchmark 3D reconstruction results with state-of-the-art methods across each lighting condition in 3DRealCar. Extensive experiments demonstrate that the standard lighting condition part of 3DRealCar can be used to produce a large number of high-quality 3D cars, improving various 2D and 3D tasks related to cars. Notably, our dataset brings insight into the fact that recent 3D reconstruction methods face challenges in reconstructing high-quality 3D cars under reflective and dark lighting conditions. \textcolor{red}{\href{https://xiaobiaodu.github.io/3drealcar/}{Our dataset is available here.}}