 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage: One-Step Video Diffusion for Photorealistic and Coherent Asset Editing in Driving Scenes
Dec 30, 2025Vision-centric autonomous driving systems rely on diverse and scalable training data to achieve robust performance. While video object editing offers a promising path for data augmentation, existing methods often struggle to maintain both high visual fidelity and temporal coherence. In this work, we propose \textbf{Mirage}, a one-step video diffusion model for photorealistic and coherent asset editing in driving scenes. Mirage builds upon a text-to-video diffusion prior to ensure temporal consistency across frames. However, 3D causal variational autoencoders often suffer from degraded spatial fidelity due to compression, and directly passing 3D encoder features to decoder layers breaks temporal causality. To address this, we inject temporally agnostic latents from a pretrained 2D encoder into the 3D decoder to restore detail while preserving causal structures. Furthermore, because scene objects and inserted assets are optimized under different objectives, their Gaussians exhibit a distribution mismatch that leads to pose misalignment. To mitigate this, we introduce a two-stage data alignment strategy combining coarse 3D alignment and fine 2D refinement, thereby improving alignment and providing cleaner supervision. Extensive experiments demonstrate that Mirage achieves high realism and temporal consistency across diverse editing scenarios. Beyond asset editing, Mirage can also generalize to other video-to-video translation tasks, serving as a reliable baseline for future research. Our code is available at https://github.com/wm-research/mirage.
CMamba: Learned Image Compression with State Space Models
Feb 07, 2025Learned Image Compression (LIC) has explored various architectures, such as Convolutional Neural Networks (CNNs) and transformers, in modeling image content distributions in order to achieve compression effectiveness. However, achieving high rate-distortion performance while maintaining low computational complexity (\ie, parameters, FLOPs, and latency) remains challenging. In this paper, we propose a hybrid Convolution and State Space Models (SSMs) based image compression framework, termed \textit{CMamba}, to achieve superior rate-distortion performance with low computational complexity. Specifically, CMamba introduces two key components: a Content-Adaptive SSM (CA-SSM) module and a Context-Aware Entropy (CAE) module. First, we observed that SSMs excel in modeling overall content but tend to lose high-frequency details. In contrast, CNNs are proficient at capturing local details. Motivated by this, we propose the CA-SSM module that can dynamically fuse global content extracted by SSM blocks and local details captured by CNN blocks in both encoding and decoding stages. As a result, important image content is well preserved during compression. Second, our proposed CAE module is designed to reduce spatial and channel redundancies in latent representations after encoding. Specifically, our CAE leverages SSMs to parameterize the spatial content in latent representations. Benefiting from SSMs, CAE significantly improves spatial compression efficiency while reducing spatial content redundancies. Moreover, along the channel dimension, CAE reduces inter-channel redundancies of latent representations via an autoregressive manner, which can fully exploit prior knowledge from previous channels without sacrificing efficiency. Experimental results demonstrate that CMamba achieves superior rate-distortion performance.
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
3DRealCar: An In-the-wild RGB-D Car Dataset with 360-degree Views
Jun 07, 2024

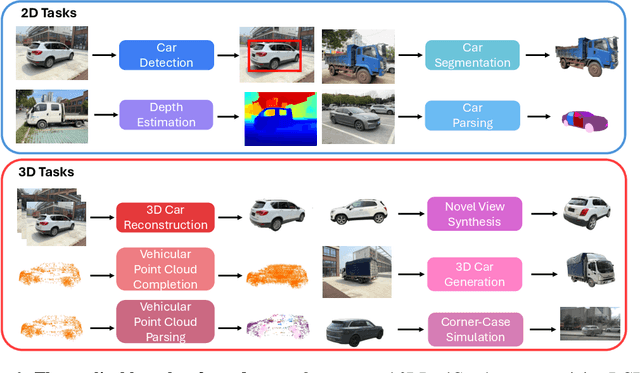
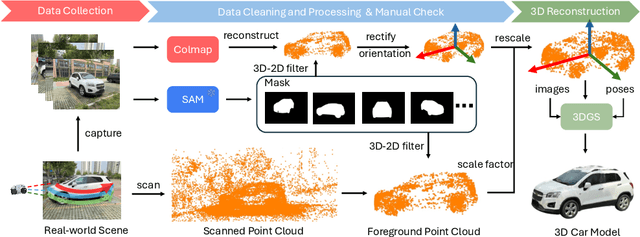
3D cars are commonly used in self-driving systems, virtual/augmented reality, and games. However, existing 3D car datasets are either synthetic or low-quality, presenting a significant gap toward the high-quality real-world 3D car datasets and limiting their applications in practical scenarios. In this paper, we propose the first large-scale 3D real car dataset, termed 3DRealCar, offering three distinctive features. (1) \textbf{High-Volume}: 2,500 cars are meticulously scanned by 3D scanners, obtaining car images and point clouds with real-world dimensions; (2) \textbf{High-Quality}: Each car is captured in an average of 200 dense, high-resolution 360-degree RGB-D views, enabling high-fidelity 3D reconstruction; (3) \textbf{High-Diversity}: The dataset contains various cars from over 100 brands, collected under three distinct lighting conditions, including reflective, standard, and dark. Additionally, we offer detailed car parsing maps for each instance to promote research in car parsing tasks. Moreover, we remove background point clouds and standardize the car orientation to a unified axis for the reconstruction only on cars without background and controllable rendering. We benchmark 3D reconstruction results with state-of-the-art methods across each lighting condition in 3DRealCar. Extensive experiments demonstrate that the standard lighting condition part of 3DRealCar can be used to produce a large number of high-quality 3D cars, improving various 2D and 3D tasks related to cars. Notably, our dataset brings insight into the fact that recent 3D reconstruction methods face challenges in reconstructing high-quality 3D cars under reflective and dark lighting conditions. \textcolor{red}{\href{https://xiaobiaodu.github.io/3drealcar/}{Our dataset is available here.}}
QGait: Toward Accurate Quantization for Gait Recognition with Binarized Input
May 22, 2024Existing deep learning methods have made significant progress in gait recognition. Typically, appearance-based models binarize inputs into silhouette sequences. However, mainstream quantization methods prioritize minimizing task loss over quantization error, which is detrimental to gait recognition with binarized inputs. Minor variations in silhouette sequences can be diminished in the network's intermediate layers due to the accumulation of quantization errors. To address this, we propose a differentiable soft quantizer, which better simulates the gradient of the round function during backpropagation. This enables the network to learn from subtle input perturbations. However, our theoretical analysis and empirical studies reveal that directly applying the soft quantizer can hinder network convergence. We further refine the training strategy to ensure convergence while simulating quantization errors. Additionally, we visualize the distribution of outputs from different samples in the feature space and observe significant changes compared to the full precision network, which harms performance. Based on this, we propose an Inter-class Distance-guided Distillation (IDD) strategy to preserve the relative distance between the embeddings of samples with different labels. Extensive experiments validate the effectiveness of our approach, demonstrating state-of-the-art accuracy across various settings and datasets. The code will be made publicly available.
Information Prebuilt Recurrent Reconstruction Network for Video Super-Resolution
Dec 10, 2021

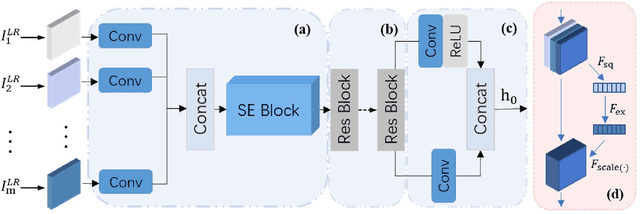
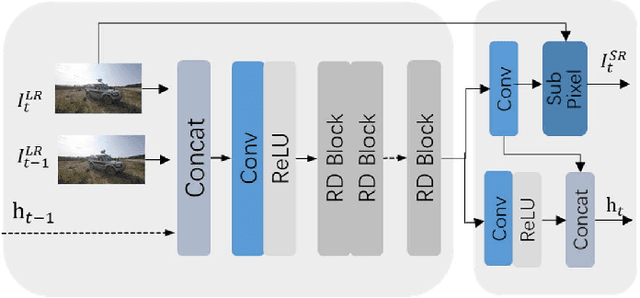
The video super-resolution (VSR) method based on the recurrent convolutional network has strong temporal modeling capability for video sequences. However, the input information received by different recurrent units in the unidirectional recurrent convolutional network is unbalanced. Early reconstruction frames receive less temporal information, resulting in fuzzy or artifact results. Although the bidirectional recurrent convolution network can alleviate this problem, it greatly increases reconstruction time and computational complexity. It is also not suitable for many application scenarios, such as online super-resolution. To solve the above problems, we propose an end-to-end information prebuilt recurrent reconstruction network (IPRRN), consisting of an information prebuilt network (IPNet) and a recurrent reconstruction network (RRNet). By integrating sufficient information from the front of the video to build the hidden state needed for the initially recurrent unit to help restore the earlier frames, the information prebuilt network balances the input information difference before and after without backward propagation. In addition, we demonstrate a compact recurrent reconstruction network, which has significant improvements in recovery quality and time efficiency. Many experiments have verified the effectiveness of our proposed network, and compared with the existing state-of-the-art methods, our method can effectively achieve higher quantitative and qualitative evaluation performance.