 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDMA-Based Passive Multiple Users SWIPT Utilizing Resonant Beams
May 24, 2025The rapid development of IoT technology has led to a shortage of spectrum resources and energy, giving rise to simultaneous wireless information and power transfer (SWIPT) technology. However, traditional multiple input multiple output (MIMO)-based SWIPT faces challenges in target detection. We have designed a passive multi-user resonant beam system (MU-RBS) that can achieve efficient power transfer and communication through adaptive beam alignment. The frequency division multiple access (FDMA) is employed in the downlink (DL) channel, while frequency conversion is utilized in the uplink (UL) channel to avoid echo interference and co-channel interference, and the system architecture design and corresponding mathematical model are presented. The simulation results show that MU-RBS can achieve adaptive beam-forming without the target transmitting pilot signals, has high directivity, and as the number of iterations increases, the power transmission efficiency, signal-to-noise ratio and spectral efficiency of the UL and DL are continuously optimized until the system reaches the optimal state.
A Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
Triply Laplacian Scale Mixture Modeling for Seismic Data Noise Suppression
Feb 20, 2025Sparsity-based tensor recovery methods have shown great potential in suppressing seismic data noise. These methods exploit tensor sparsity measures capturing the low-dimensional structures inherent in seismic data tensors to remove noise by applying sparsity constraints through soft-thresholding or hard-thresholding operators. However, in these methods, considering that real seismic data are non-stationary and affected by noise, the variances of tensor coefficients are unknown and may be difficult to accurately estimate from the degraded seismic data, leading to undesirable noise suppression performance. In this paper, we propose a novel triply Laplacian scale mixture (TLSM) approach for seismic data noise suppression, which significantly improves the estimation accuracy of both the sparse tensor coefficients and hidden scalar parameters. To make the optimization problem manageable, an alternating direction method of multipliers (ADMM) algorithm is employed to solve the proposed TLSM-based seismic data noise suppression problem. Extensive experimental results on synthetic and field seismic data demonstrate that the proposed TLSM algorithm outperforms many state-of-the-art seismic data noise suppression methods in both quantitative and qualitative evaluations while providing exceptional computational efficiency.
Resonant Beam Multi-Target DOA Estimation
Dec 20, 2024With the increasing demand for internet of things (IoT) applications, especially for location-based services, how to locate passive mobile targets (MTs) with minimal beam control has become a challenge. Resonant beam systems are considered promising IoT technologies with advantages such as beam self-alignment and energy concentration. To establish a resonant system in the radio frequency (RF) band and achieve multi-target localization, this paper designs a multi-target resonant system architecture, allowing a single base station (BS) to independently connect with multiple MTs. By employing a retro-directive array, a multi-channel cyclic model is established to realize one-to-many electromagnetic wave propagation and MT direction-of-arrival (DOA) estimation through echo resonance. Simulation results show that the proposed system supports resonant establishment between the BS and multiple MTs. This helps the BS to still have high DOA estimation accuracy in the face of multiple passive MTs, and can ensure that the DOA error is less than 1 degree within a range of 6 meters at a 50degree field of view, with higher accuracy than active beamforming localization systems.
Resonant Beam Enabled Passive 3D Positioning
Dec 20, 2024
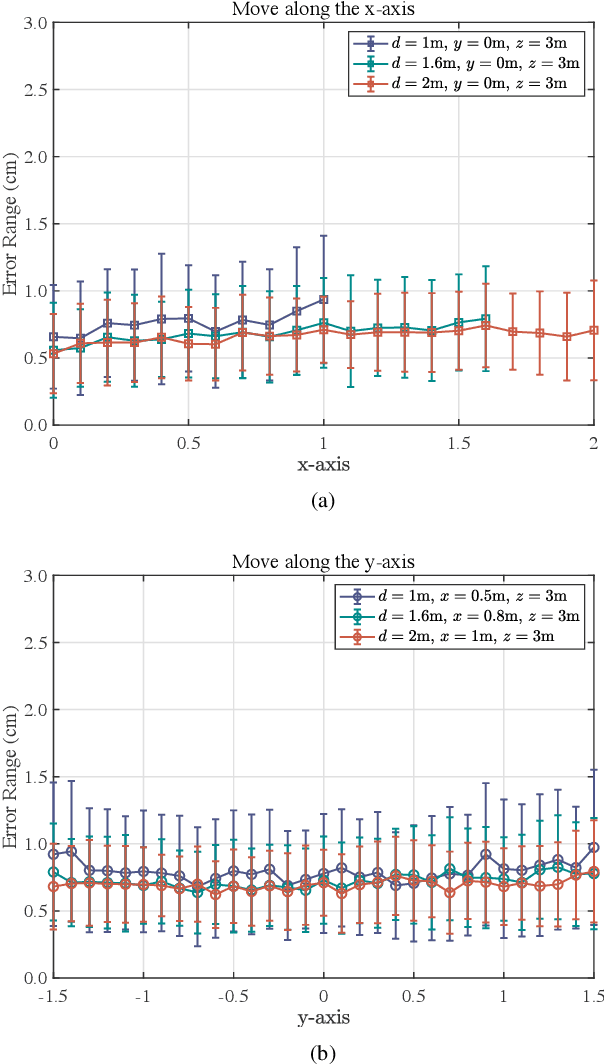

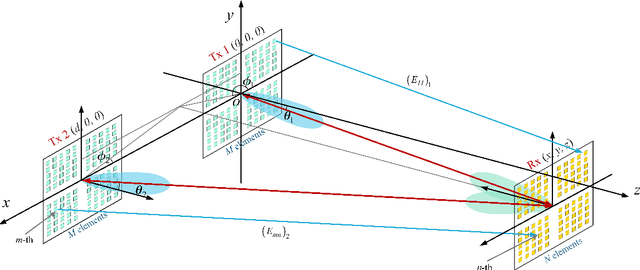
With the rapid development of the internet of things (IoT), location-based services are becoming increasingly prominent in various aspects of social life, and accurate location information is crucial. However, RF-based indoor positioning solutions are severely limited in positioning accuracy due to signal transmission losses and directional difficulties, and optical indoor positioning methods require high propagation conditions. To achieve higher accuracy in indoor positioning, we utilize the principle of resonance to design a triangulation-based resonant beam positioning system (TRBPS) in the RF band. The proposed system employs phase-conjugation antenna arrays and resonance mechanism to achieve energy concentration and beam self-alignment, without requiring active signals from the target for positioning and complex beam control algorithms. Numerical evaluations indicate that TRBPS can achieve millimeter-level accuracy within a range of 3.6 m without the need for additional embedded systems.
See Where You Read with Eye Gaze Tracking and Large Language Model
Sep 28, 2024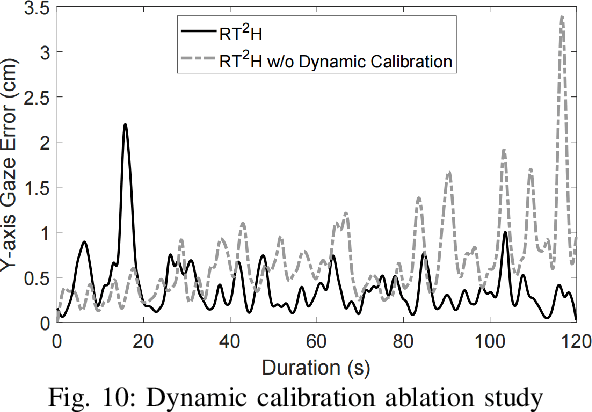

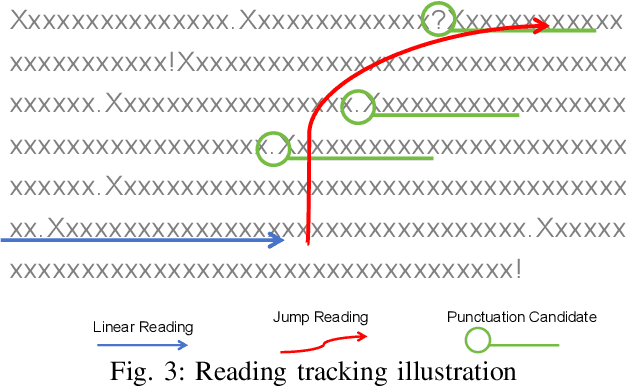
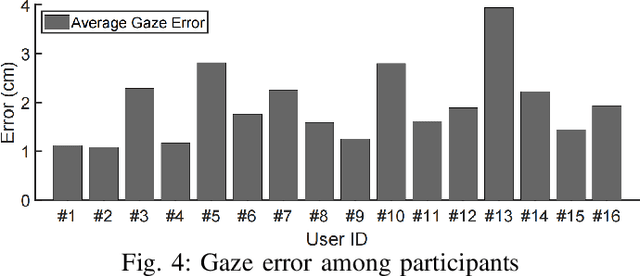
Losing track of reading progress during line switching can be frustrating. Eye gaze tracking technology offers a potential solution by highlighting read paragraphs, aiding users in avoiding wrong line switches. However, the gap between gaze tracking accuracy (2-3 cm) and text line spacing (3-5 mm) makes direct application impractical. Existing methods leverage the linear reading pattern but fail during jump reading. This paper presents a reading tracking and highlighting system that supports both linear and jump reading. Based on experimental insights from the gaze nature study of 16 users, two gaze error models are designed to enable both jump reading detection and relocation. The system further leverages the large language model's contextual perception capability in aiding reading tracking. A reading tracking domain-specific line-gaze alignment opportunity is also exploited to enable dynamic and frequent calibration of the gaze results. Controlled experiments demonstrate reliable linear reading tracking, as well as 84% accuracy in tracking jump reading. Furthermore, real field tests with 18 volunteers demonstrated the system's effectiveness in tracking and highlighting read paragraphs, improving reading efficiency, and enhancing user experience.
Resonant Beam Enabled DoA Estimation in Passive Positioning System
Aug 08, 2024



The rapid advancement of the next generation of communications and internet of things (IoT) technologies has made the provision of location-based services for diverse devices an increasingly pressing necessity. Localizing devices with/without intelligent computing abilities, including both active and passive devices is essential, especially in indoor scenarios. For traditional RF positioning systems, aligning transmission signals and dealing with signal interference in complex environments are inevitable challenges. Therefore, this paper proposed a new passive positioning system, the RF-band resonant beam positioning system (RF-RBPS), which achieves energy concentration and beam alignment by amplifying echoes between the base station (BS) and the passive target (PT), without the need for complex channel estimation and time-consuming beamforming and provides high-precision direction of arrival (DoA) estimation for battery-free targets using the resonant mechanism. The direction information of the PT is estimated using the multiple signal classification (MUSIC) algorithm at the end of BS. The feasibility of the proposed system is validated through theoretical analysis and simulations. Results indicate that the proposed RF-RBPS surpasses RF-band active positioning system (RF-APS) in precision, achieving millimeter-level precision at 2m within an elevation angle of 35$^\circ$, and an error of less than 3cm at 2.5m within an elevation angle of 35$^\circ$.
Maintaining Adversarial Robustness in Continuous Learning
Feb 17, 2024Adversarial robustness is essential for security and reliability of machine learning systems. However, the adversarial robustness gained by sophisticated defense algorithms is easily erased as the neural network evolves to learn new tasks. This vulnerability can be addressed by fostering a novel capability for neural networks, termed continual robust learning, which focuses on both the (classification) performance and adversarial robustness on previous tasks during continuous learning. To achieve continuous robust learning, we propose an approach called Double Gradient Projection that projects the gradients for weight updates orthogonally onto two crucial subspaces -- one for stabilizing the smoothed sample gradients and another for stabilizing the final outputs of the neural network. The experimental results on four benchmarks demonstrate that the proposed approach effectively maintains continuous robustness against strong adversarial attacks, outperforming the baselines formed by combining the existing defense strategies and continual learning methods.
DePRL: Achieving Linear Convergence Speedup in Personalized Decentralized Learning with Shared Representations
Dec 17, 2023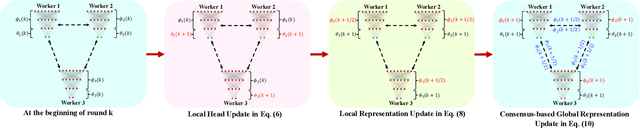


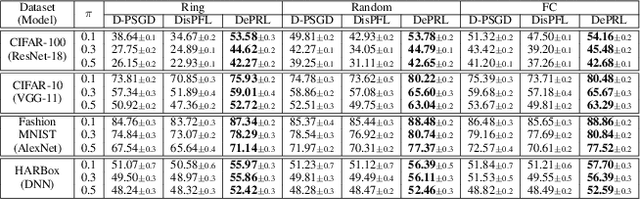
Decentralized learning has emerged as an alternative method to the popular parameter-server framework which suffers from high communication burden, single-point failure and scalability issues due to the need of a central server. However, most existing works focus on a single shared model for all workers regardless of the data heterogeneity problem, rendering the resulting model performing poorly on individual workers. In this work, we propose a novel personalized decentralized learning algorithm named DePRL via shared representations. Our algorithm relies on ideas from representation learning theory to learn a low-dimensional global representation collaboratively among all workers in a fully decentralized manner, and a user-specific low-dimensional local head leading to a personalized solution for each worker. We show that DePRL achieves, for the first time, a provable linear speedup for convergence with general non-linear representations (i.e., the convergence rate is improved linearly with respect to the number of workers). Experimental results support our theoretical findings showing the superiority of our method in data heterogeneous environments.
Straggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Jun 11, 2023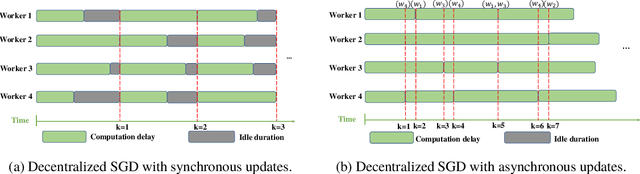
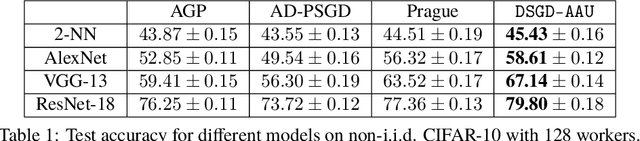
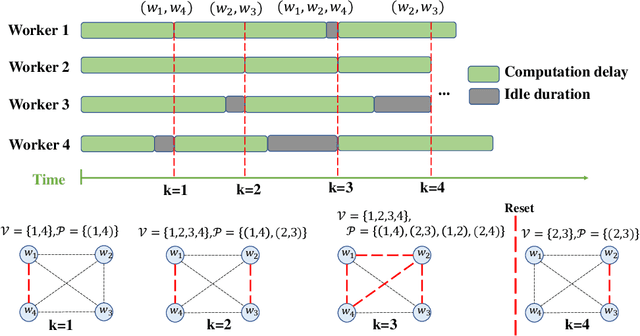

With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of the stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). Experimental results on a suite of datasets and deep neural network models are provided to verify our theoretical results.