 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResonant Beam Multi-Target DOA Estimation
Dec 20, 2024With the increasing demand for internet of things (IoT) applications, especially for location-based services, how to locate passive mobile targets (MTs) with minimal beam control has become a challenge. Resonant beam systems are considered promising IoT technologies with advantages such as beam self-alignment and energy concentration. To establish a resonant system in the radio frequency (RF) band and achieve multi-target localization, this paper designs a multi-target resonant system architecture, allowing a single base station (BS) to independently connect with multiple MTs. By employing a retro-directive array, a multi-channel cyclic model is established to realize one-to-many electromagnetic wave propagation and MT direction-of-arrival (DOA) estimation through echo resonance. Simulation results show that the proposed system supports resonant establishment between the BS and multiple MTs. This helps the BS to still have high DOA estimation accuracy in the face of multiple passive MTs, and can ensure that the DOA error is less than 1 degree within a range of 6 meters at a 50degree field of view, with higher accuracy than active beamforming localization systems.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024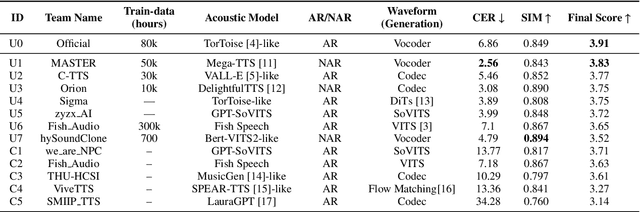
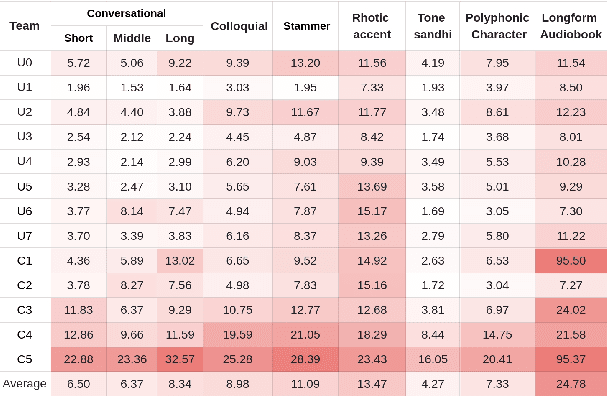
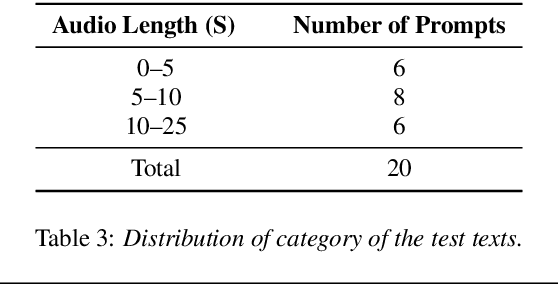
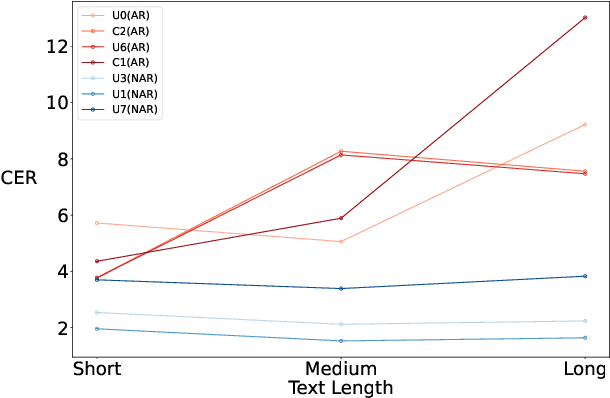
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022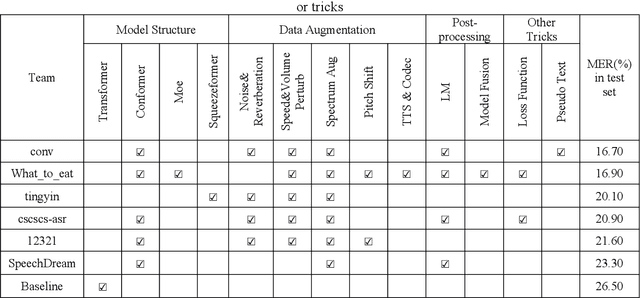
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022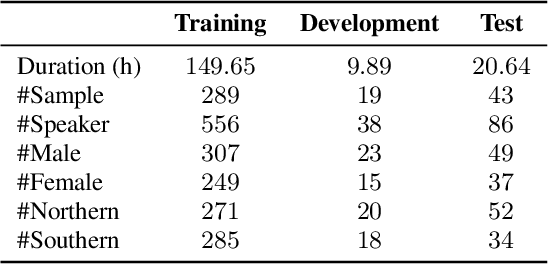

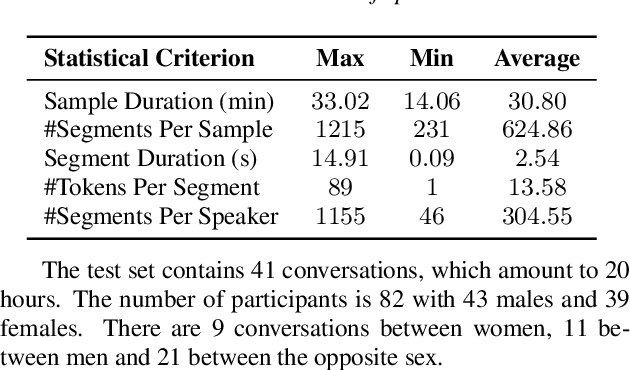
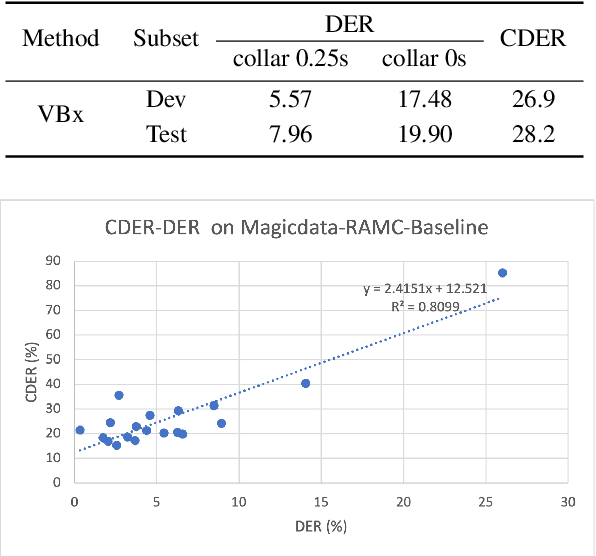
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational Speech Dataset
Mar 31, 2022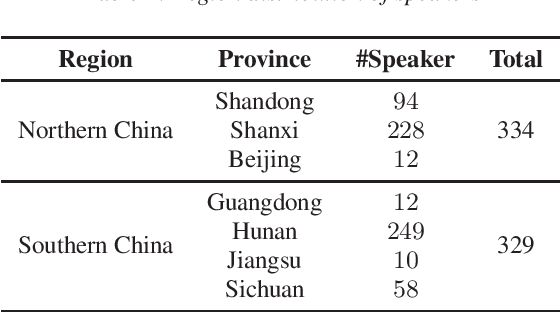
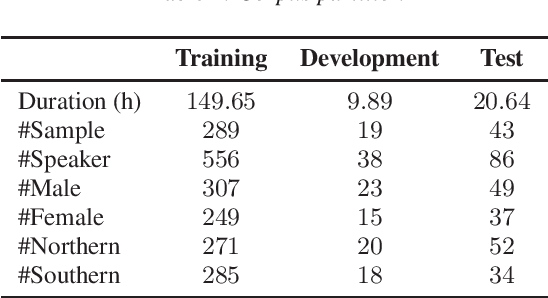
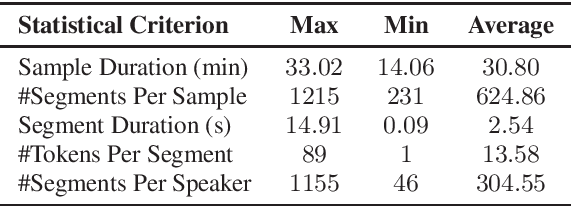
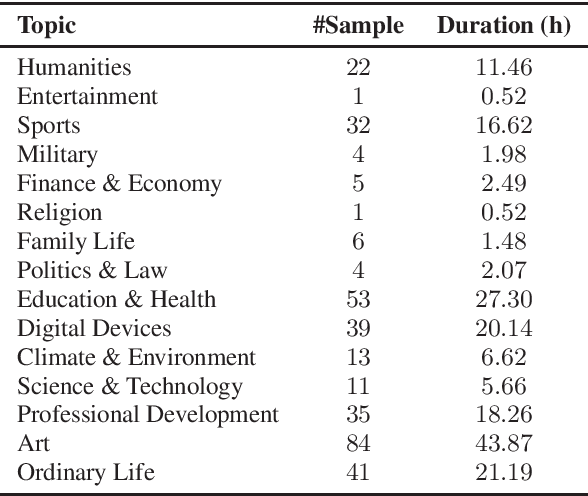
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.
Long-Range Optical Wireless Information and Power Transfer
Jul 30, 2021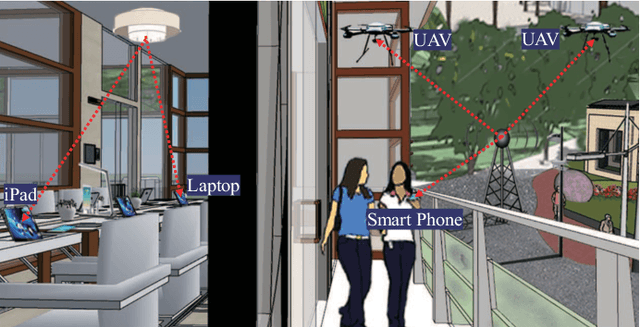
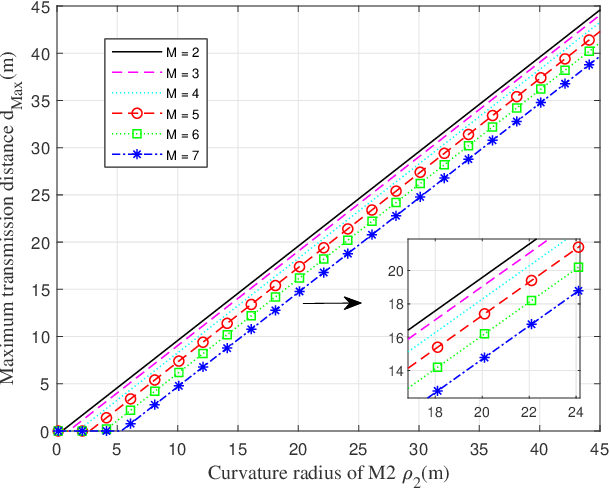
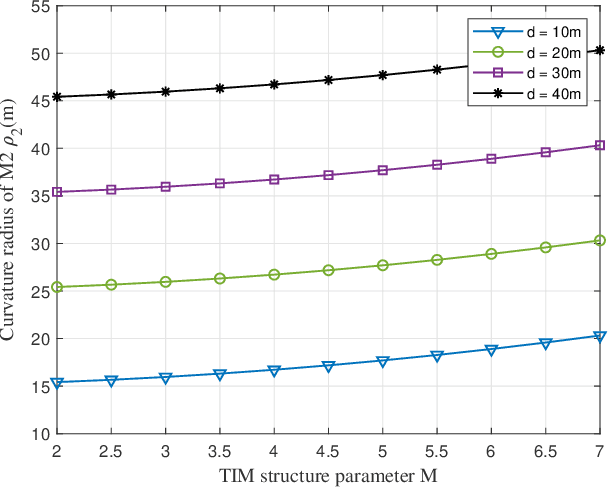
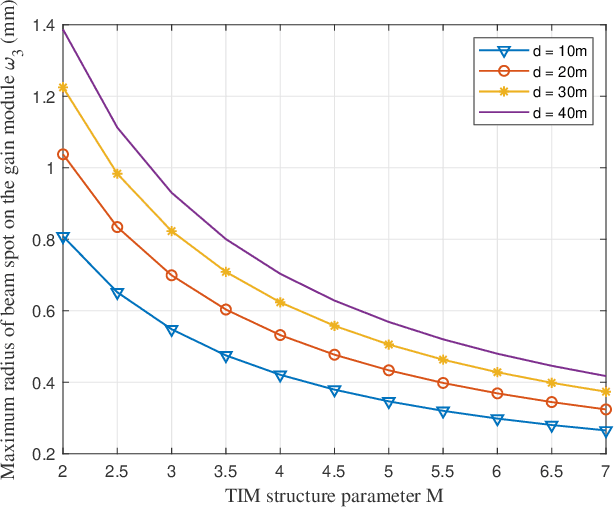
Simultaneous wireless information and power transfer (SWIPT) is a remarkable technology to support data and energy transfer in the era of Internet of Things (IoT). In this paper, we propose a beam-compression resonant beam (BCRB) system for long-range optical wireless information and power transfer based on the telescope-like internal modulator (TIM). Utilizing the TIM, the resonant beam is compressed, making the transmission energy be further concentrated. Thus the over-the-air power loss produced by the beam diverged decreases, which enables the long-range SWIPT capability. We establish the analytical models of the transmission loss, the stability condition, the output power, and the spectral efficiency of the BCRB system, and evaluate the performance on the beam-compression, energy delivery, and data transfer. Numerical analysis illustrates that the exemplary BCRB system can deliver 6 W power and have 14 bit/s/Hz spectral efficiency over 200 m distance. Overall, the BCRB system is a potential scheme for long-range SWIPT in IoT.
Lightweight Mask R-CNN for Long-Range Wireless Power Transfer Systems
Apr 19, 2020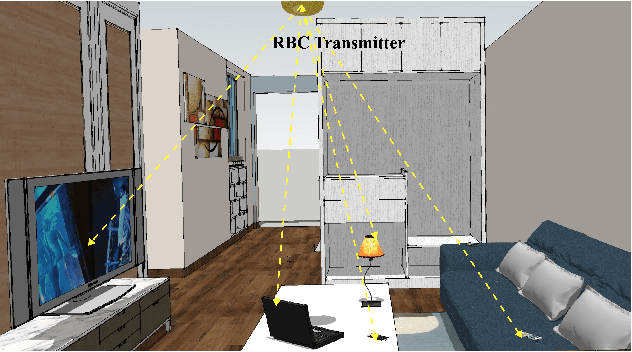
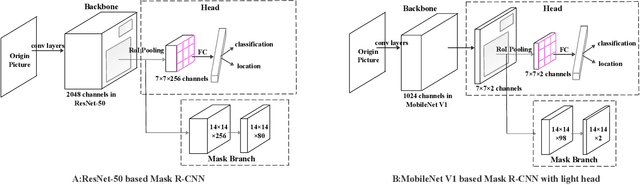


Resonant Beam Charging (RBC) is a wireless charging technology which supports multi-watt power transfer over meter-level distance. The features of safety, mobility and simultaneous charging capability enable RBC to charge multiple mobile devices safely at the same time. To detect the devices that need to be charged, a Mask R-CNN based dection model is proposed in previous work. However, considering the constraints of the RBC system, it's not easy to apply Mask R-CNN in lightweight hardware-embedded devices because of its heavy model and huge computation. Thus, we propose a machine learning detection approach which provides a lighter and faster model based on traditional Mask R-CNN. The proposed approach makes the object detection much easier to be transplanted on mobile devices and reduce the burden of hardware computation. By adjusting the structure of the backbone and the head part of Mask R-CNN, we reduce the average detection time from $1.02\mbox{s}$ per image to $0.6132\mbox{s}$, and reduce the model size from $245\mbox{MB}$ to $47.1\mbox{MB}$. The improved model is much more suitable for the application in the RBC system.