 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NPU-HWC System for the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge
Oct 31, 2024This paper presents the NPU-HWC system submitted to the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge 2024 (ICAGC). Our system consists of two modules: a speech generator for Track 1 and a background audio generator for Track 2. In Track 1, we employ Single-Codec to tokenize the speech into discrete tokens and use a language-model-based approach to achieve zero-shot speaking style cloning. The Single-Codec effectively decouples timbre and speaking style at the token level, reducing the acoustic modeling burden on the autoregressive language model. Additionally, we use DSPGAN to upsample 16 kHz mel-spectrograms to high-fidelity 48 kHz waveforms. In Track 2, we propose a background audio generator based on large language models (LLMs). This system produces scene-appropriate accompaniment descriptions, synthesizes background audio with Tango 2, and integrates it with the speech generated by our Track 1 system. Our submission achieves the second place and the first place in Track 1 and Track 2 respectively.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024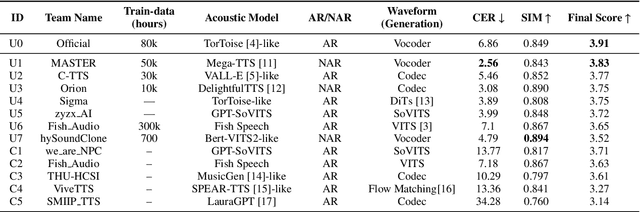
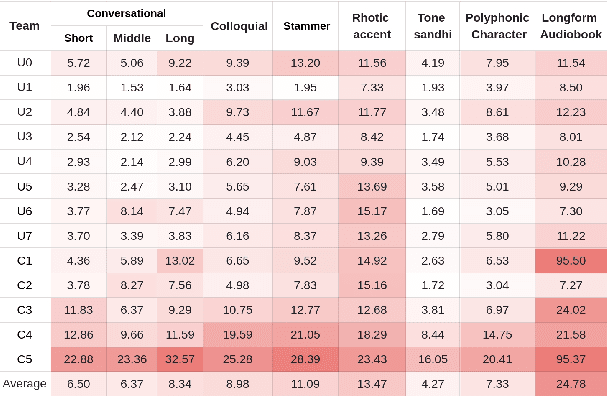
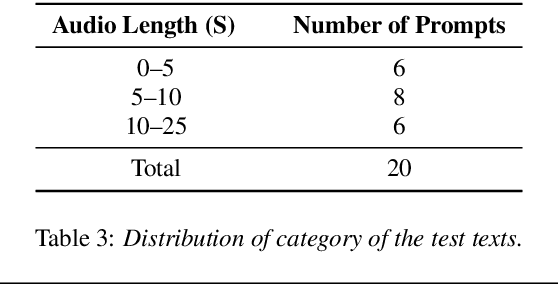
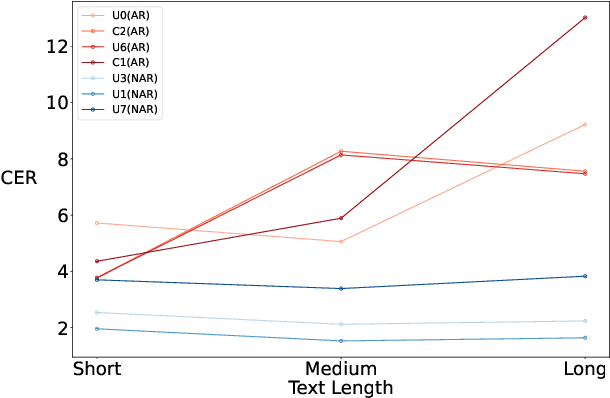
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
Open-Structure: a Structural Benchmark Dataset for SLAM Algorithms
Oct 17, 2023



This paper introduces a new benchmark dataset, Open-Structure, for evaluating visual odometry and SLAM methods, which directly equips point and line measurements, correspondences, structural associations, and co-visibility factor graphs instead of providing raw images. Based on the proposed benchmark dataset, these 2D or 3D data can be directly input to different stages of SLAM pipelines to avoid the impact of the data preprocessing modules in ablation experiments. First, we propose a dataset generator for real-world and simulated scenarios. In real-world scenes, it maintains the same observations and occlusions as actual feature extraction results. Those generated simulation sequences enhance the dataset's diversity by introducing various carefully designed trajectories and observations. Second, a SLAM baseline is proposed using our dataset to evaluate widely used modules in camera pose tracking, parametrization, and optimization modules. By evaluating these state-of-the-art algorithms across different scenarios, we discern each module's strengths and weaknesses within the camera tracking and optimization process. Our dataset and baseline are available at \url{https://github.com/yanyan-li/Open-Structure}.
A Bioinspired Bidirectional Stiffening Soft Actuator for Multimodal, Compliant, and Robust Grasping
Nov 22, 2022The stiffness modulation mechanism for soft robotics has gained considerable attention to improve deformability, controllability, and stability. However, for the existing stiffness soft actuator, high lateral stiffness and a wide range of bending stiffness are hard to be provided at the same time. This paper presents a bioinspired bidirectional stiffening soft actuator (BISA) combining the air-tendon hybrid actuation (ATA) and a bone-like structure (BLS). The ATA is the main actuation of the BISA, and the bending stiffness can be modulated with a maximum stiffness of about 0.7 N/mm and a maximum magnification of 3 times when the bending angle is 45 deg. Inspired by the morphological structure of the phalanx, the lateral stiffness can be modulated by changing the pulling force of the BLS. The lateral stiffness can be modulated by changing the pulling force to it. The actuator with BLSs can improve the lateral stiffness about 3.9 times compared to the one without BLSs. The maximum lateral stiffness can reach 0.46 N/mm. And the lateral stiffness can be modulated decoupling about 1.3 times (e.g., from 0.35 N/mm to 0.46 when the bending angle is 45 deg). The test results show the influence of the rigid structures on bending is small with about 1.5 mm maximum position errors of the distal point of actuator bending in different pulling forces. The advantages brought by the proposed method enable a soft four-finger gripper to operate in three modes: normal grasping, inverse grasping, and horizontal lifting. The performance of this gripper is further characterized and versatile grasping on various objects is conducted, proving the robust performance and potential application of the proposed design method.
A Soft-rigid Hybrid Actuator with Multi-direction Tunable Stiffness Property
May 15, 2022

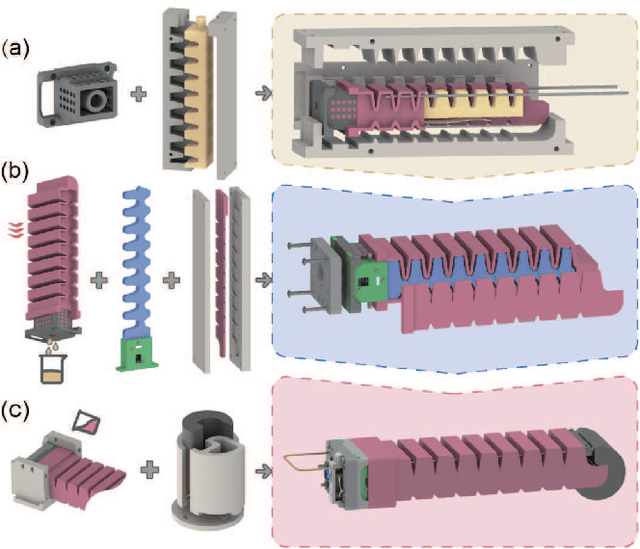
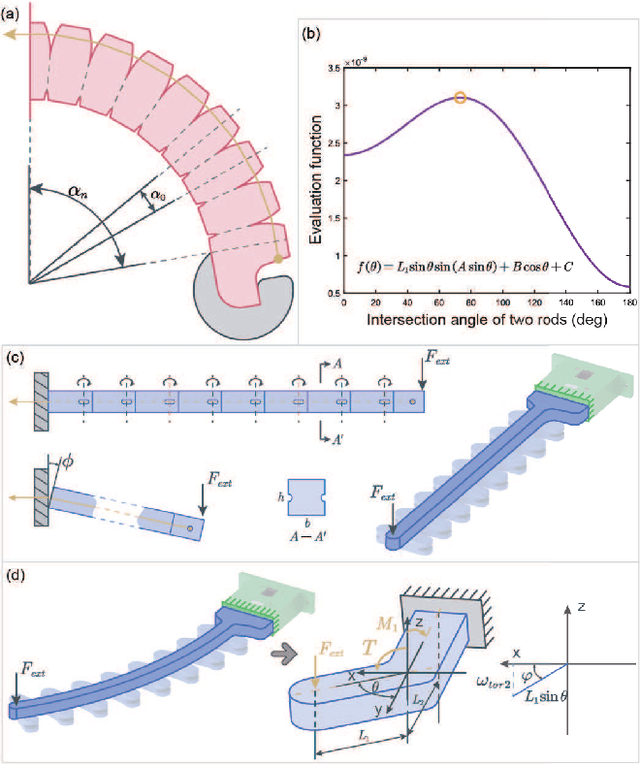
The ability to maintain compliance during interaction with the human or environments while avoiding the undesired destabilization could be extremely important for further application in practicality for soft actuators. In this paper, a soft-rigid hybrid actuator with multi-direction tunable stiffness property was proposed. The multi-direction tunable stiffness property, which means that the stiffness of multiple directions can be decoupled for modulation, was achieved in two orthogonal directions, the bending direction (B direction) and the direction perpendicular to bending (PB direction). In the B direction, the stiffness was modulated through the antagonistic effect of the tendon-air hybrid driven; In the PB direction, the jamming effect brought by a novel structure, the bone-like structure (BLS), reinforces the PB-direction stiffness. Meanwhile, in this paper, the corresponding fabrication method to ensure airtightness was designed, and the working principle for the two mechanisms of the actuator was evaluated. Finally, a series of experiments have been conducted to characterize the performance of the actuator and analyze the stiffness variation in two orthogonal directions. According to the tests, the maximum fingertip force reached 7.83N. And the experiments showed that stiffness in two directions can be tuned respectively. The B-direction stiffness can be tuned 1.5-4 times with a maximum stiffness of 1.24 N/mm. The PB-direction stiffness was enhanced about 4 times compared with the actuator without the mechanism, and it can be tuned decoupling with a range of 1.5 times.
Hierarchical LSTM with Adjusted Temporal Attention for Video Captioning
Jun 05, 2017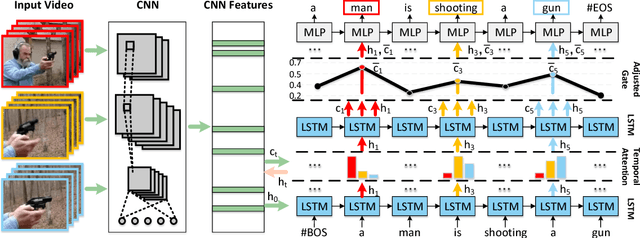



Recent progress has been made in using attention based encoder-decoder framework for video captioning. However, most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g. "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of video captioning. To address this issue, we propose a hierarchical LSTM with adjusted temporal attention (hLSTMat) approach for video captioning. Specifically, the proposed framework utilizes the temporal attention for selecting specific frames to predict the related words, while the adjusted temporal attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the video caption generation. To demonstrate the effectiveness of our proposed framework, we test our method on two prevalent datasets: MSVD and MSR-VTT, and experimental results show that our approach outperforms the state-of-the-art methods on both two datasets.