 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical LSTM with Adjusted Temporal Attention for Video Captioning
Paper and Code
Jun 05, 2017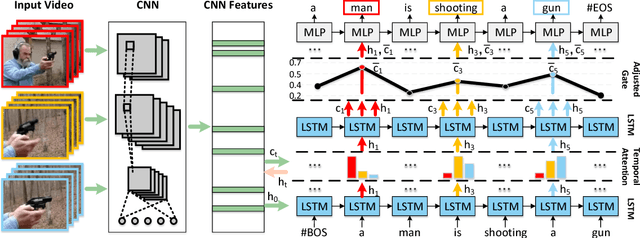



Recent progress has been made in using attention based encoder-decoder framework for video captioning. However, most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g. "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of video captioning. To address this issue, we propose a hierarchical LSTM with adjusted temporal attention (hLSTMat) approach for video captioning. Specifically, the proposed framework utilizes the temporal attention for selecting specific frames to predict the related words, while the adjusted temporal attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the video caption generation. To demonstrate the effectiveness of our proposed framework, we test our method on two prevalent datasets: MSVD and MSR-VTT, and experimental results show that our approach outperforms the state-of-the-art methods on both two datasets.