 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional hydro-cluttered locomotion by an undulatory robot
Jun 05, 2026Aquatic robots have expanded human access to underwater environments, yet many underwater spaces contain obstacles that can disrupt open-water locomotion. In "hydro-cluttered" environments, water is interspersed with rigid and flexible clutter, making body-obstacle contact unavoidable. Operating in these spaces requires robots that can regulate and exploit contact, but this regime remains difficult to model or simulate. Building on recent advances in mechanical intelligence in terradynamically capable limbless robotics, we develop principles for 3D aquatic locomotion using AquaMILR, an elongate limbless robot that combines bilateral cable-driven actuation, programmable body compliance, distributed depth regulation, corrosion-resistant enclosures, and onboard power and electronics for untethered field operation. Systematic robophysical experiments reveal that programmable body compliance regulates body deformation and converts body-environment interactions into fast, robust, forward progression across increasing hydro-clutter constraint strength. Depth regulation provides three-dimensional access, allowing the robot to bypass clutter, recover from obstruction, and continue through otherwise inaccessible routes. In potential jamming scenarios, emergent inertia-induced rolling acts as a spontaneous recovery mechanism, freeing the robot from clutter that would otherwise lead to failure and allowing locomotion to continue without additional control. Tests of the robot in an aquatic mangrove field demonstrate that these principles transfer to practical operation, enabling navigation and onboard visual inspection of inaccessible root zones. These results establish principles for hydro-cluttered locomotion and a design paradigm in which aquatic robots exploit environmental complexity as a locomotor resource.
A Robust Antenna Provides Tactile Feedback in a Multi-legged Robot
Mar 08, 2026Multi-legged elongate robots hold promise for maneuvering through complex environments. Prior work has demonstrated that reliable locomotion can be achieved using open-loop body undulation and foot placement on rugose terrain. However, robust navigation through confined spaces remains challenging when body-environment contact is extensive and terrain rheology varies rapidly. To address this challenge, we develop a pair of tactile antennae for multi-legged robots that enable real-time sensing of surrounding geometry, modeling the morphology and function of biological centipede antennae. Each antenna features gradient compliance, with a stiff base and soft tip, allowing repeated deformation and elastic recovery. Robophysical experiments reveal a relationship between continuous antenna curvature and contact force, leading to a simplified mapping from antenna deformation to inferred discrete collision states. We incorporate this mapping into a controller that selects among a set of locomotor maneuvers based on the inferred collision state. Experiments in obstacle-rich and confined environments demonstrate that tactile feedback enables reliable steering and allows the robot to recover from near-stuck conditions without requiring global environmental information or real-time vision. These results highlight how mechanically tuned tactile appendages can simplify sensing and enhance autonomy in elongate multi-legged robots operating in constrained spaces.
Probabilistic approach to feedback control enhances multi-legged locomotion on rugged landscapes
Nov 11, 2024



Achieving robust legged locomotion on complex terrains poses challenges due to the high uncertainty in robot-environment interactions. Recent advances in bipedal and quadrupedal robots demonstrate good mobility on rugged terrains but rely heavily on sensors for stability due to low static stability from a high center of mass and a narrow base of support. We hypothesize that a multi-legged robotic system can leverage morphological redundancy from additional legs to minimize sensing requirements when traversing challenging terrains. Studies suggest that a multi-legged system with sufficient legs can reliably navigate noisy landscapes without sensing and control, albeit at a low speed of up to 0.1 body lengths per cycle (BLC). However, the control framework to enhance speed on challenging terrains remains underexplored due to the complex environmental interactions, making it difficult to identify the key parameters to control in these high-degree-of-freedom systems. Here, we present a bio-inspired vertical body undulation wave as a novel approach to mitigate environmental disturbances affecting robot speed, supported by experiments and probabilistic models. Finally, we introduce a control framework which monitors foot-ground contact patterns on rugose landscapes using binary foot-ground contact sensors to estimate terrain rugosity. The controller adjusts the vertical body wave based on the deviation of the limb's averaged actual-to-ideal foot-ground contact ratio, achieving a significant enhancement of up to 0.235 BLC on rugose laboratory terrain. We observed a $\sim$ 50\% increase in speed and a $\sim$ 40\% reduction in speed variance compared to the open-loop controller. Additionally, the controller operates in complex terrains outside the lab, including pine straw, robot-sized rocks, mud, and leaves.
Addition of a peristaltic wave improves multi-legged locomotion performance on complex terrains
Oct 01, 2024



Characterized by their elongate bodies and relatively simple legs, multi-legged robots have the potential to locomote through complex terrains for applications such as search-and-rescue and terrain inspection. Prior work has developed effective and reliable locomotion strategies for multi-legged robots by propagating the two waves of lateral body undulation and leg stepping, which we will refer to as the two-wave template. However, these robots have limited capability to climb over obstacles with sizes comparable to their heights. We hypothesize that such limitations stem from the two-wave template that we used to prescribe the multi-legged locomotion. Seeking effective alternative waves for obstacle-climbing, we designed a five-segment robot with static (non-actuated) legs, where each cable-driven joint has a rotational degree-of-freedom (DoF) in the sagittal plane (vertical wave) and a linear DoF (peristaltic wave). We tested robot locomotion performance on a flat terrain and a rugose terrain. While the benefit of peristalsis on flat-ground locomotion is marginal, the inclusion of a peristaltic wave substantially improves the locomotion performance in rugose terrains: it not only enables obstacle-climbing capabilities with obstacles having a similar height as the robot, but it also significantly improves the traversing capabilities of the robot in such terrains. Our results demonstrate an alternative actuation mechanism for multi-legged robots, paving the way towards all-terrain multi-legged robots.
A Progressive Framework of Vision-language Knowledge Distillation and Alignment for Multilingual Scene
Apr 17, 2024



Pre-trained vision-language (V-L) models such as CLIP have shown excellent performance in many downstream cross-modal tasks. However, most of them are only applicable to the English context. Subsequent research has focused on this problem and proposed improved models, such as CN-CLIP and AltCLIP, to facilitate their applicability to Chinese and even other languages. Nevertheless, these models suffer from high latency and a large memory footprint in inference, which limits their further deployment on resource-constrained edge devices. In this work, we propose a conceptually simple yet effective multilingual CLIP Compression framework and train a lightweight multilingual vision-language model, called DC-CLIP, for both Chinese and English context. In this framework, we collect high-quality Chinese and English text-image pairs and design two training stages, including multilingual vision-language feature distillation and alignment. During the first stage, lightweight image/text student models are designed to learn robust visual/multilingual textual feature representation ability from corresponding teacher models, respectively. Subsequently, the multilingual vision-language alignment stage enables effective alignment of visual and multilingual textual features to further improve the model's multilingual performance. Comprehensive experiments in zero-shot image classification, conducted based on the ELEVATER benchmark, showcase that DC-CLIP achieves superior performance in the English context and competitive performance in the Chinese context, even with less training data, when compared to existing models of similar parameter magnitude. The evaluation demonstrates the effectiveness of our designed training mechanism.
Beyond Text: Unveiling Multimodal Proficiency of Large Language Models with MultiAPI Benchmark
Nov 21, 2023The proliferation of Large Language Models like ChatGPT has significantly advanced language understanding and generation, impacting a broad spectrum of applications. However, these models predominantly excel in text-based tasks, overlooking the complexity of real-world multimodal information. This study introduces MultiAPI, a pioneering comprehensive large-scale API benchmark dataset aimed at expanding LLMs' proficiency in multimodal contexts. Developed collaboratively through ChatGPT, MultiAPI consists of 235 diverse API calls and 2,038 contextual prompts, offering a unique platform evaluation of tool-augmented LLMs handling multimodal tasks. Through comprehensive experiments, our findings reveal that while LLMs demonstrate proficiency in API call decision-making, they face challenges in domain identification, function selection, and argument generation. What's more, we surprisingly notice that auxiliary context can actually impair the performance. An in-depth error analysis paves the way for a new paradigm to address these challenges, suggesting a potential direction for future LLM research.
A Bioinspired Bidirectional Stiffening Soft Actuator for Multimodal, Compliant, and Robust Grasping
Nov 22, 2022The stiffness modulation mechanism for soft robotics has gained considerable attention to improve deformability, controllability, and stability. However, for the existing stiffness soft actuator, high lateral stiffness and a wide range of bending stiffness are hard to be provided at the same time. This paper presents a bioinspired bidirectional stiffening soft actuator (BISA) combining the air-tendon hybrid actuation (ATA) and a bone-like structure (BLS). The ATA is the main actuation of the BISA, and the bending stiffness can be modulated with a maximum stiffness of about 0.7 N/mm and a maximum magnification of 3 times when the bending angle is 45 deg. Inspired by the morphological structure of the phalanx, the lateral stiffness can be modulated by changing the pulling force of the BLS. The lateral stiffness can be modulated by changing the pulling force to it. The actuator with BLSs can improve the lateral stiffness about 3.9 times compared to the one without BLSs. The maximum lateral stiffness can reach 0.46 N/mm. And the lateral stiffness can be modulated decoupling about 1.3 times (e.g., from 0.35 N/mm to 0.46 when the bending angle is 45 deg). The test results show the influence of the rigid structures on bending is small with about 1.5 mm maximum position errors of the distal point of actuator bending in different pulling forces. The advantages brought by the proposed method enable a soft four-finger gripper to operate in three modes: normal grasping, inverse grasping, and horizontal lifting. The performance of this gripper is further characterized and versatile grasping on various objects is conducted, proving the robust performance and potential application of the proposed design method.
A Soft-rigid Hybrid Actuator with Multi-direction Tunable Stiffness Property
May 15, 2022

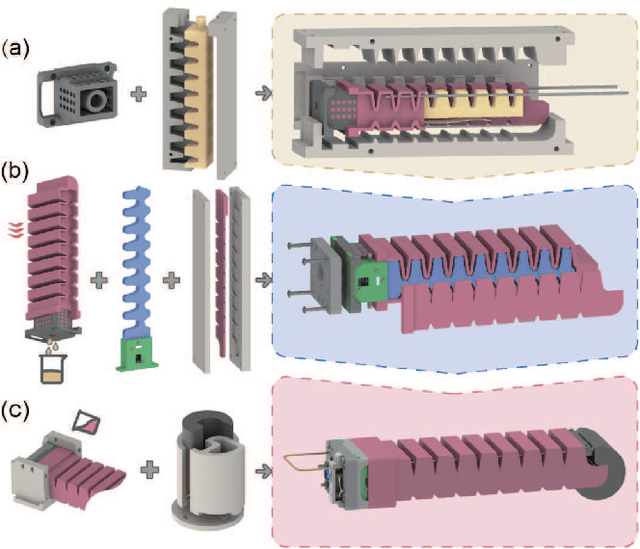
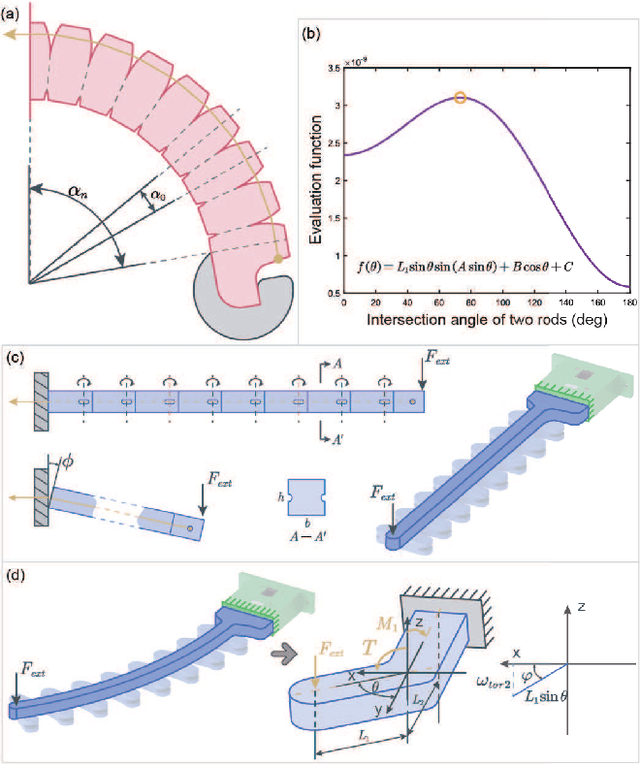
The ability to maintain compliance during interaction with the human or environments while avoiding the undesired destabilization could be extremely important for further application in practicality for soft actuators. In this paper, a soft-rigid hybrid actuator with multi-direction tunable stiffness property was proposed. The multi-direction tunable stiffness property, which means that the stiffness of multiple directions can be decoupled for modulation, was achieved in two orthogonal directions, the bending direction (B direction) and the direction perpendicular to bending (PB direction). In the B direction, the stiffness was modulated through the antagonistic effect of the tendon-air hybrid driven; In the PB direction, the jamming effect brought by a novel structure, the bone-like structure (BLS), reinforces the PB-direction stiffness. Meanwhile, in this paper, the corresponding fabrication method to ensure airtightness was designed, and the working principle for the two mechanisms of the actuator was evaluated. Finally, a series of experiments have been conducted to characterize the performance of the actuator and analyze the stiffness variation in two orthogonal directions. According to the tests, the maximum fingertip force reached 7.83N. And the experiments showed that stiffness in two directions can be tuned respectively. The B-direction stiffness can be tuned 1.5-4 times with a maximum stiffness of 1.24 N/mm. The PB-direction stiffness was enhanced about 4 times compared with the actuator without the mechanism, and it can be tuned decoupling with a range of 1.5 times.