 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
The NPU-HWC System for the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge
Oct 31, 2024This paper presents the NPU-HWC system submitted to the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge 2024 (ICAGC). Our system consists of two modules: a speech generator for Track 1 and a background audio generator for Track 2. In Track 1, we employ Single-Codec to tokenize the speech into discrete tokens and use a language-model-based approach to achieve zero-shot speaking style cloning. The Single-Codec effectively decouples timbre and speaking style at the token level, reducing the acoustic modeling burden on the autoregressive language model. Additionally, we use DSPGAN to upsample 16 kHz mel-spectrograms to high-fidelity 48 kHz waveforms. In Track 2, we propose a background audio generator based on large language models (LLMs). This system produces scene-appropriate accompaniment descriptions, synthesizes background audio with Tango 2, and integrates it with the speech generated by our Track 1 system. Our submission achieves the second place and the first place in Track 1 and Track 2 respectively.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024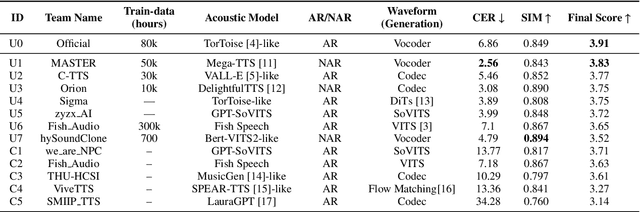
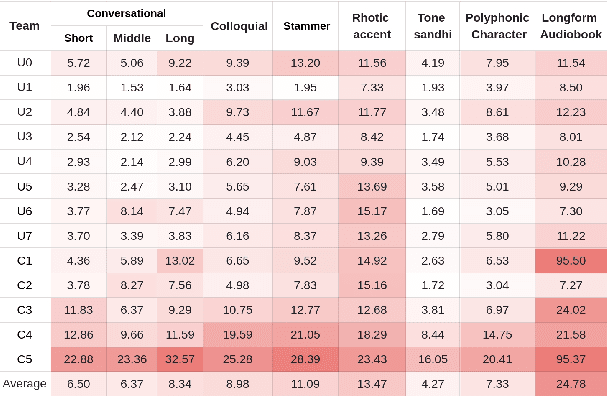
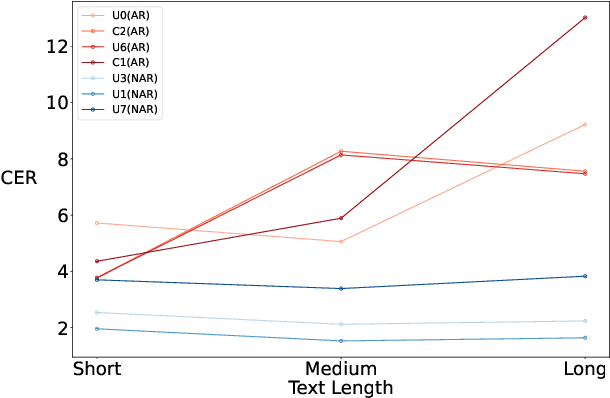
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.