 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-GRPO: Unsupervised Speech Emotion Recognition based on Batched-Group Relative Policy Optimization
Feb 06, 2026Unsupervised speech emotion recognition (SER) focuses on addressing the problem of data sparsity and annotation bias of emotional speech. Reinforcement learning (RL) is a promising method which enhances the performance through rule-based or model-based verification functions rather than human annotations. We treat the sample selection during the learning process as a long-term procedure and whether to select a sample as the action to make policy, thus achieving the application of RL to measure sample quality in SER. We propose a modified Group Relative Policy Optimization (GRPO) to adapt it to classification problems, which takes the samples in a batch as a group and uses the average reward of these samples as the baseline to calculate the advantage. And rather than using a verifiable reward function as in GRPO, we put forward self-reward functions and teacher-reward functions to encourage the model to produce high-confidence outputs. Experiments indicate that the proposed method improves the performance of baseline without RL by 19.8%.
PolySpeech: Exploring Unified Multitask Speech Models for Competitiveness with Single-task Models
Jun 12, 2024Recently, there have been attempts to integrate various speech processing tasks into a unified model. However, few previous works directly demonstrated that joint optimization of diverse tasks in multitask speech models has positive influence on the performance of individual tasks. In this paper we present a multitask speech model -- PolySpeech, which supports speech recognition, speech synthesis, and two speech classification tasks. PolySpeech takes multi-modal language model as its core structure and uses semantic representations as speech inputs. We introduce semantic speech embedding tokenization and speech reconstruction methods to PolySpeech, enabling efficient generation of high-quality speech for any given speaker. PolySpeech shows competitiveness across various tasks compared to single-task models. In our experiments, multitask optimization achieves performance comparable to single-task optimization and is especially beneficial for specific tasks.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022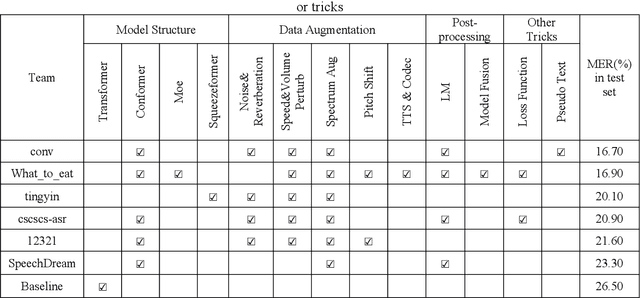
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022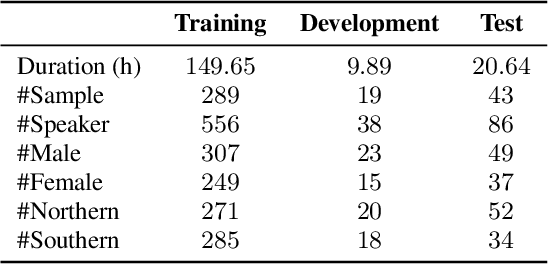

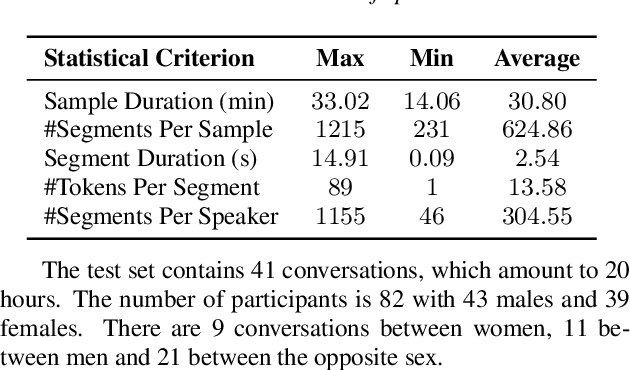
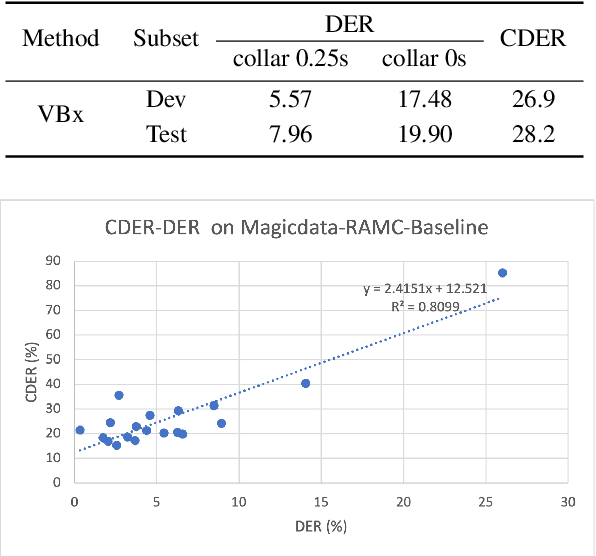
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational Speech Dataset
Mar 31, 2022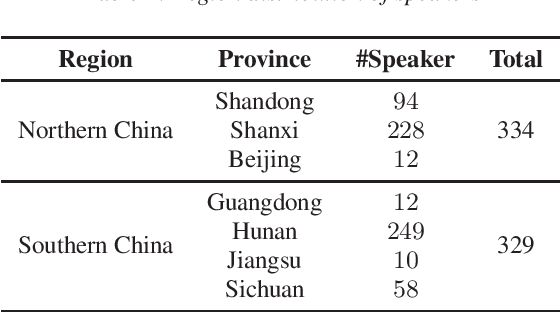
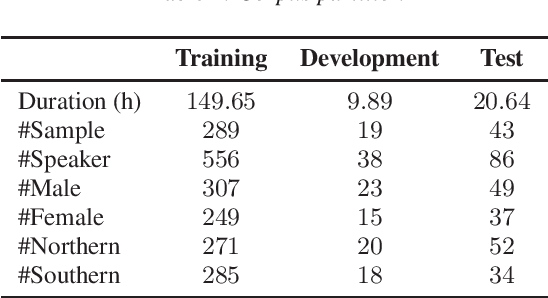
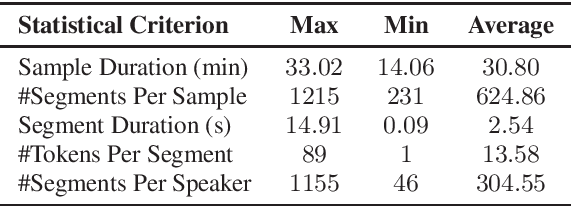
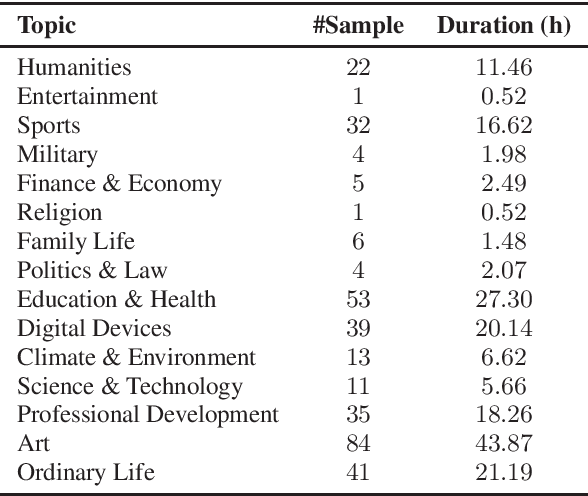
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.