 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-GRPO: Unsupervised Speech Emotion Recognition based on Batched-Group Relative Policy Optimization
Feb 06, 2026Unsupervised speech emotion recognition (SER) focuses on addressing the problem of data sparsity and annotation bias of emotional speech. Reinforcement learning (RL) is a promising method which enhances the performance through rule-based or model-based verification functions rather than human annotations. We treat the sample selection during the learning process as a long-term procedure and whether to select a sample as the action to make policy, thus achieving the application of RL to measure sample quality in SER. We propose a modified Group Relative Policy Optimization (GRPO) to adapt it to classification problems, which takes the samples in a batch as a group and uses the average reward of these samples as the baseline to calculate the advantage. And rather than using a verifiable reward function as in GRPO, we put forward self-reward functions and teacher-reward functions to encourage the model to produce high-confidence outputs. Experiments indicate that the proposed method improves the performance of baseline without RL by 19.8%.
CoCo-MILP: Inter-Variable Contrastive and Intra-Constraint Competitive MILP Solution Prediction
Nov 12, 2025Mixed-Integer Linear Programming (MILP) is a cornerstone of combinatorial optimization, yet solving large-scale instances remains a significant computational challenge. Recently, Graph Neural Networks (GNNs) have shown promise in accelerating MILP solvers by predicting high-quality solutions. However, we identify that existing methods misalign with the intrinsic structure of MILP problems at two levels. At the leaning objective level, the Binary Cross-Entropy (BCE) loss treats variables independently, neglecting their relative priority and yielding plausible logits. At the model architecture level, standard GNN message passing inherently smooths the representations across variables, missing the natural competitive relationships within constraints. To address these challenges, we propose CoCo-MILP, which explicitly models inter-variable Contrast and intra-constraint Competition for advanced MILP solution prediction. At the objective level, CoCo-MILP introduces the Inter-Variable Contrastive Loss (VCL), which explicitly maximizes the embedding margin between variables assigned one versus zero. At the architectural level, we design an Intra-Constraint Competitive GNN layer that, instead of homogenizing features, learns to differentiate representations of competing variables within a constraint, capturing their exclusionary nature. Experimental results on standard benchmarks demonstrate that CoCo-MILP significantly outperforms existing learning-based approaches, reducing the solution gap by up to 68.12% compared to traditional solvers. Our code is available at https://github.com/happypu326/CoCo-MILP.
DiffStyleTTS: Diffusion-based Hierarchical Prosody Modeling for Text-to-Speech with Diverse and Controllable Styles
Dec 04, 2024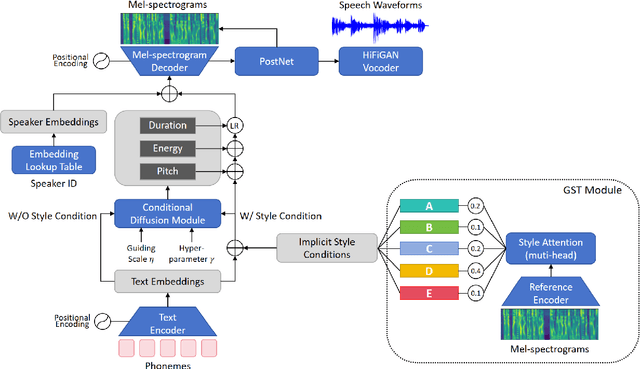
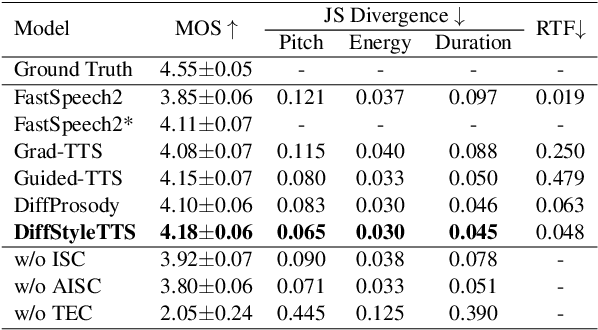
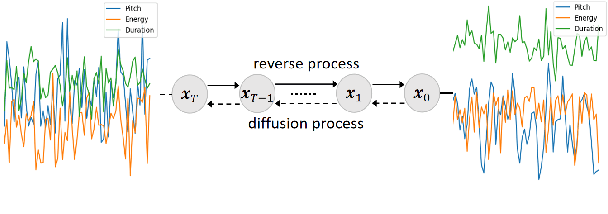
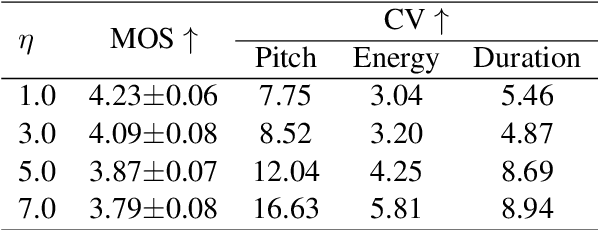
Human speech exhibits rich and flexible prosodic variations. To address the one-to-many mapping problem from text to prosody in a reasonable and flexible manner, we propose DiffStyleTTS, a multi-speaker acoustic model based on a conditional diffusion module and an improved classifier-free guidance, which hierarchically models speech prosodic features, and controls different prosodic styles to guide prosody prediction. Experiments show that our method outperforms all baselines in naturalness and achieves superior synthesis speed compared to three diffusion-based baselines. Additionally, by adjusting the guiding scale, DiffStyleTTS effectively controls the guidance intensity of the synthetic prosody.
VoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark
Jul 16, 2024In this paper, we provide a large audio-visual speaker recognition dataset, VoxBlink2, which includes approximately 10M utterances with videos from 110K+ speakers in the wild. This dataset represents a significant expansion over the VoxBlink dataset, encompassing a broader diversity of speakers and scenarios by the grace of an optimized data collection pipeline. Afterward, we explore the impact of training strategies, data scale, and model complexity on speaker verification and finally establish a new single-model state-of-the-art EER at 0.170% and minDCF at 0.006% on the VoxCeleb1-O test set. Such remarkable results motivate us to explore speaker recognition from a new challenging perspective. We raise the Open-Set Speaker-Identification task, which is designed to either match a probe utterance with a known gallery speaker or categorize it as an unknown query. Associated with this task, we design concrete benchmark and evaluation protocols. The data and model resources can be found in http://voxblink2.github.io.
On Calibration of Speech Classification Models: Insights from Energy-Based Model Investigations
Jun 26, 2024



For speech classification tasks, deep learning models often achieve high accuracy but exhibit shortcomings in calibration, manifesting as classifiers exhibiting overconfidence. The significance of calibration lies in its critical role in guaranteeing the reliability of decision-making within deep learning systems. This study explores the effectiveness of Energy-Based Models in calibrating confidence for speech classification tasks by training a joint EBM integrating a discriminative and a generative model, thereby enhancing the classifiers calibration and mitigating overconfidence. Experimental evaluations conducted on three speech classification tasks specifically: age, emotion, and language recognition. Our findings highlight the competitive performance of EBMs in calibrating the speech classification models. This research emphasizes the potential of EBMs in speech classification tasks, demonstrating their ability to enhance calibration without sacrificing accuracy.
Exploring Energy-Based Models for Out-of-Distribution Detection in Dialect Identification
Jun 26, 2024



The diverse nature of dialects presents challenges for models trained on specific linguistic patterns, rendering them susceptible to errors when confronted with unseen or out-of-distribution (OOD) data. This study introduces a novel margin-enhanced joint energy model (MEJEM) tailored specifically for OOD detection in dialects. By integrating a generative model and the energy margin loss, our approach aims to enhance the robustness of dialect identification systems. Furthermore, we explore two OOD scores for OOD dialect detection, and our findings conclusively demonstrate that the energy score outperforms the softmax score. Leveraging Sharpness-Aware Minimization to optimize the training process of the joint model, we enhance model generalization by minimizing both loss and sharpness. Experiments conducted on dialect identification tasks validate the efficacy of Energy-Based Models and provide valuable insights into their performance.
CEC: A Noisy Label Detection Method for Speaker Recognition
Jun 19, 2024



Noisy labels are inevitable, even in well-annotated datasets. The detection of noisy labels is of significant importance to enhance the robustness of speaker recognition models. In this paper, we propose a novel noisy label detection approach based on two new statistical metrics: Continuous Inconsistent Counting (CIC) and Total Inconsistent Counting (TIC). These metrics are calculated through Cross-Epoch Counting (CEC) and correspond to the early and late stages of training, respectively. Additionally, we categorize samples based on their prediction results into three categories: inconsistent samples, hard samples, and easy samples. During training, we gradually increase the difficulty of hard samples to update model parameters, preventing noisy labels from being overfitted. Compared to contrastive schemes, our approach not only achieves the best performance in speaker verification but also excels in noisy label detection.
PolySpeech: Exploring Unified Multitask Speech Models for Competitiveness with Single-task Models
Jun 12, 2024Recently, there have been attempts to integrate various speech processing tasks into a unified model. However, few previous works directly demonstrated that joint optimization of diverse tasks in multitask speech models has positive influence on the performance of individual tasks. In this paper we present a multitask speech model -- PolySpeech, which supports speech recognition, speech synthesis, and two speech classification tasks. PolySpeech takes multi-modal language model as its core structure and uses semantic representations as speech inputs. We introduce semantic speech embedding tokenization and speech reconstruction methods to PolySpeech, enabling efficient generation of high-quality speech for any given speaker. PolySpeech shows competitiveness across various tasks compared to single-task models. In our experiments, multitask optimization achieves performance comparable to single-task optimization and is especially beneficial for specific tasks.
Plugin Speech Enhancement: A Universal Speech Enhancement Framework Inspired by Dynamic Neural Network
Feb 20, 2024The expectation to deploy a universal neural network for speech enhancement, with the aim of improving noise robustness across diverse speech processing tasks, faces challenges due to the existing lack of awareness within static speech enhancement frameworks regarding the expected speech in downstream modules. These limitations impede the effectiveness of static speech enhancement approaches in achieving optimal performance for a range of speech processing tasks, thereby challenging the notion of universal applicability. The fundamental issue in achieving universal speech enhancement lies in effectively informing the speech enhancement module about the features of downstream modules. In this study, we present a novel weighting prediction approach, which explicitly learns the task relationships from downstream training information to address the core challenge of universal speech enhancement. We found the role of deciding whether to employ data augmentation techniques as crucial downstream training information. This decision significantly impacts the expected speech and the performance of the speech enhancement module. Moreover, we introduce a novel speech enhancement network, the Plugin Speech Enhancement (Plugin-SE). The Plugin-SE is a dynamic neural network that includes the speech enhancement module, gate module, and weight prediction module. Experimental results demonstrate that the proposed Plugin-SE approach is competitive or superior to other joint training methods across various downstream tasks.
Cascaded Multi-task Adaptive Learning Based on Neural Architecture Search
Oct 23, 2023Cascading multiple pre-trained models is an effective way to compose an end-to-end system. However, fine-tuning the full cascaded model is parameter and memory inefficient and our observations reveal that only applying adapter modules on cascaded model can not achieve considerable performance as fine-tuning. We propose an automatic and effective adaptive learning method to optimize end-to-end cascaded multi-task models based on Neural Architecture Search (NAS) framework. The candidate adaptive operations on each specific module consist of frozen, inserting an adapter and fine-tuning. We further add a penalty item on the loss to limit the learned structure which takes the amount of trainable parameters into account. The penalty item successfully restrict the searched architecture and the proposed approach is able to search similar tuning scheme with hand-craft, compressing the optimizing parameters to 8.7% corresponding to full fine-tuning on SLURP with an even better performance.