 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezeComposer: Temporal Speed-up is A Simple Trick for Long-form Music Composing
Mar 22, 2026Composing coherent long-form music remains a significant challenge due to the complexity of modeling long-range dependencies and the prohibitive memory and computational requirements associated with lengthy audio representations. In this work, we propose a simple yet powerful trick: we assume that AI models can understand and generate time-accelerated (speeded-up) audio at rates such as 2x, 4x, or even 8x. By first generating a high-speed version of the music, we greatly reduce the temporal length and resource requirements, making it feasible to handle long-form music that would otherwise exceed memory or computational limits. The generated audio is then restored to its original speed, recovering the full temporal structure. This temporal speed-up and slow-down strategy naturally follows the principle of hierarchical generation from abstract to detailed content, and can be conveniently applied to existing music generation models to enable long-form music generation. We instantiate this idea in SqueezeComposer, a framework that employs diffusion models for generation in the accelerated domain and refinement in the restored domain. We validate the effectiveness of this approach on two tasks: long-form music generation, which evaluates temporal-wise control (including continuation, completion, and generation from scratch), and whole-song singing accompaniment generation, which evaluates track-wise control. Experimental results demonstrate that our simple temporal speed-up trick enables efficient, scalable, and high-quality long-form music generation. Audio samples are available at https://SqueezeComposer.github.io/.
B-GRPO: Unsupervised Speech Emotion Recognition based on Batched-Group Relative Policy Optimization
Feb 06, 2026Unsupervised speech emotion recognition (SER) focuses on addressing the problem of data sparsity and annotation bias of emotional speech. Reinforcement learning (RL) is a promising method which enhances the performance through rule-based or model-based verification functions rather than human annotations. We treat the sample selection during the learning process as a long-term procedure and whether to select a sample as the action to make policy, thus achieving the application of RL to measure sample quality in SER. We propose a modified Group Relative Policy Optimization (GRPO) to adapt it to classification problems, which takes the samples in a batch as a group and uses the average reward of these samples as the baseline to calculate the advantage. And rather than using a verifiable reward function as in GRPO, we put forward self-reward functions and teacher-reward functions to encourage the model to produce high-confidence outputs. Experiments indicate that the proposed method improves the performance of baseline without RL by 19.8%.
OneVoice: One Model, Triple Scenarios-Towards Unified Zero-shot Voice Conversion
Jan 26, 2026Recent progress of voice conversion~(VC) has achieved a new milestone in speaker cloning and linguistic preservation. But the field remains fragmented, relying on specialized models for linguistic-preserving, expressive, and singing scenarios. We propose OneVoice, a unified zero-shot framework capable of handling all three scenarios within a single model. OneVoice is built upon a continuous language model trained with VAE-free next-patch diffusion, ensuring high fidelity and efficient sequence modeling. Its core design for unification lies in a Mixture-of-Experts (MoE) designed to explicitly model shared conversion knowledge and scenario-specific expressivity. Expert selection is coordinated by a dual-path routing mechanism, including shared expert isolation and scenario-aware domain expert assignment with global-local cues. For precise conditioning, scenario-specific prosodic features are fused into each layer via a gated mechanism, allowing adaptive usage of prosody information. Furthermore, to enable the core idea and alleviate the imbalanced issue (abundant speech vs. scarce singing), we adopt a two-stage progressive training that includes foundational pre-training and scenario enhancement with LoRA-based domain experts. Experiments show that OneVoice matches or surpasses specialized models across all three scenarios, while verifying flexible control over scenarios and offering a fast decoding version as few as 2 steps. Code and model will be released soon.
DiffStyleTTS: Diffusion-based Hierarchical Prosody Modeling for Text-to-Speech with Diverse and Controllable Styles
Dec 04, 2024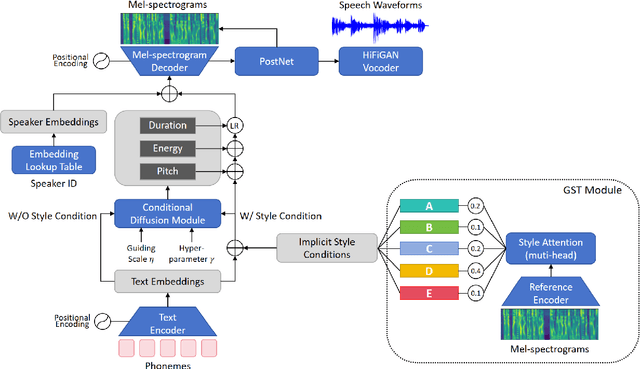
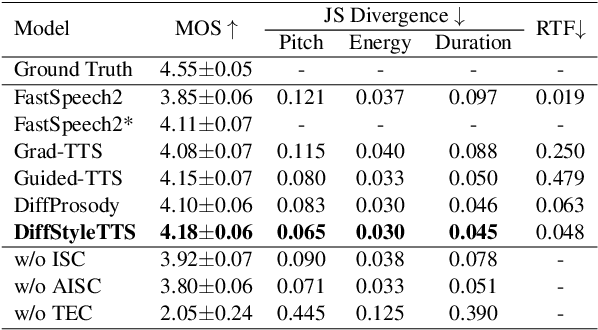
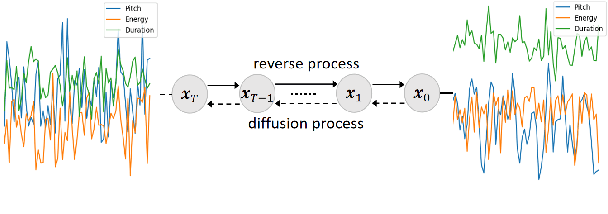
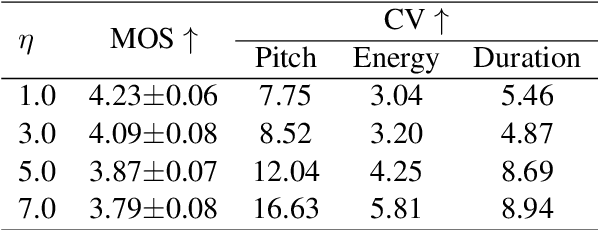
Human speech exhibits rich and flexible prosodic variations. To address the one-to-many mapping problem from text to prosody in a reasonable and flexible manner, we propose DiffStyleTTS, a multi-speaker acoustic model based on a conditional diffusion module and an improved classifier-free guidance, which hierarchically models speech prosodic features, and controls different prosodic styles to guide prosody prediction. Experiments show that our method outperforms all baselines in naturalness and achieves superior synthesis speed compared to three diffusion-based baselines. Additionally, by adjusting the guiding scale, DiffStyleTTS effectively controls the guidance intensity of the synthetic prosody.
VoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark
Jul 16, 2024In this paper, we provide a large audio-visual speaker recognition dataset, VoxBlink2, which includes approximately 10M utterances with videos from 110K+ speakers in the wild. This dataset represents a significant expansion over the VoxBlink dataset, encompassing a broader diversity of speakers and scenarios by the grace of an optimized data collection pipeline. Afterward, we explore the impact of training strategies, data scale, and model complexity on speaker verification and finally establish a new single-model state-of-the-art EER at 0.170% and minDCF at 0.006% on the VoxCeleb1-O test set. Such remarkable results motivate us to explore speaker recognition from a new challenging perspective. We raise the Open-Set Speaker-Identification task, which is designed to either match a probe utterance with a known gallery speaker or categorize it as an unknown query. Associated with this task, we design concrete benchmark and evaluation protocols. The data and model resources can be found in http://voxblink2.github.io.
On Calibration of Speech Classification Models: Insights from Energy-Based Model Investigations
Jun 26, 2024



For speech classification tasks, deep learning models often achieve high accuracy but exhibit shortcomings in calibration, manifesting as classifiers exhibiting overconfidence. The significance of calibration lies in its critical role in guaranteeing the reliability of decision-making within deep learning systems. This study explores the effectiveness of Energy-Based Models in calibrating confidence for speech classification tasks by training a joint EBM integrating a discriminative and a generative model, thereby enhancing the classifiers calibration and mitigating overconfidence. Experimental evaluations conducted on three speech classification tasks specifically: age, emotion, and language recognition. Our findings highlight the competitive performance of EBMs in calibrating the speech classification models. This research emphasizes the potential of EBMs in speech classification tasks, demonstrating their ability to enhance calibration without sacrificing accuracy.
Exploring Energy-Based Models for Out-of-Distribution Detection in Dialect Identification
Jun 26, 2024



The diverse nature of dialects presents challenges for models trained on specific linguistic patterns, rendering them susceptible to errors when confronted with unseen or out-of-distribution (OOD) data. This study introduces a novel margin-enhanced joint energy model (MEJEM) tailored specifically for OOD detection in dialects. By integrating a generative model and the energy margin loss, our approach aims to enhance the robustness of dialect identification systems. Furthermore, we explore two OOD scores for OOD dialect detection, and our findings conclusively demonstrate that the energy score outperforms the softmax score. Leveraging Sharpness-Aware Minimization to optimize the training process of the joint model, we enhance model generalization by minimizing both loss and sharpness. Experiments conducted on dialect identification tasks validate the efficacy of Energy-Based Models and provide valuable insights into their performance.
CEC: A Noisy Label Detection Method for Speaker Recognition
Jun 19, 2024



Noisy labels are inevitable, even in well-annotated datasets. The detection of noisy labels is of significant importance to enhance the robustness of speaker recognition models. In this paper, we propose a novel noisy label detection approach based on two new statistical metrics: Continuous Inconsistent Counting (CIC) and Total Inconsistent Counting (TIC). These metrics are calculated through Cross-Epoch Counting (CEC) and correspond to the early and late stages of training, respectively. Additionally, we categorize samples based on their prediction results into three categories: inconsistent samples, hard samples, and easy samples. During training, we gradually increase the difficulty of hard samples to update model parameters, preventing noisy labels from being overfitted. Compared to contrastive schemes, our approach not only achieves the best performance in speaker verification but also excels in noisy label detection.
PolySpeech: Exploring Unified Multitask Speech Models for Competitiveness with Single-task Models
Jun 12, 2024Recently, there have been attempts to integrate various speech processing tasks into a unified model. However, few previous works directly demonstrated that joint optimization of diverse tasks in multitask speech models has positive influence on the performance of individual tasks. In this paper we present a multitask speech model -- PolySpeech, which supports speech recognition, speech synthesis, and two speech classification tasks. PolySpeech takes multi-modal language model as its core structure and uses semantic representations as speech inputs. We introduce semantic speech embedding tokenization and speech reconstruction methods to PolySpeech, enabling efficient generation of high-quality speech for any given speaker. PolySpeech shows competitiveness across various tasks compared to single-task models. In our experiments, multitask optimization achieves performance comparable to single-task optimization and is especially beneficial for specific tasks.
Plugin Speech Enhancement: A Universal Speech Enhancement Framework Inspired by Dynamic Neural Network
Feb 20, 2024The expectation to deploy a universal neural network for speech enhancement, with the aim of improving noise robustness across diverse speech processing tasks, faces challenges due to the existing lack of awareness within static speech enhancement frameworks regarding the expected speech in downstream modules. These limitations impede the effectiveness of static speech enhancement approaches in achieving optimal performance for a range of speech processing tasks, thereby challenging the notion of universal applicability. The fundamental issue in achieving universal speech enhancement lies in effectively informing the speech enhancement module about the features of downstream modules. In this study, we present a novel weighting prediction approach, which explicitly learns the task relationships from downstream training information to address the core challenge of universal speech enhancement. We found the role of deciding whether to employ data augmentation techniques as crucial downstream training information. This decision significantly impacts the expected speech and the performance of the speech enhancement module. Moreover, we introduce a novel speech enhancement network, the Plugin Speech Enhancement (Plugin-SE). The Plugin-SE is a dynamic neural network that includes the speech enhancement module, gate module, and weight prediction module. Experimental results demonstrate that the proposed Plugin-SE approach is competitive or superior to other joint training methods across various downstream tasks.