Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStyleTTS: Diffusion-based Hierarchical Prosody Modeling for Text-to-Speech with Diverse and Controllable Styles
Dec 04, 2024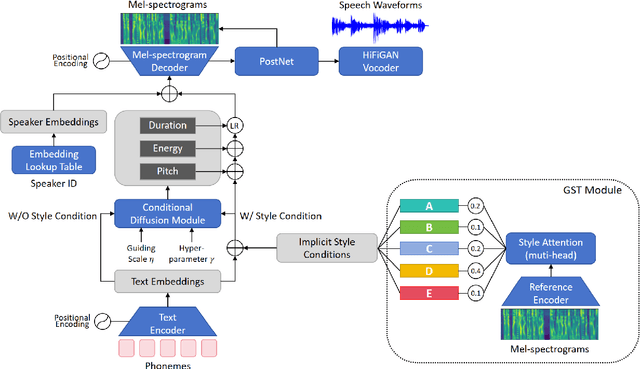
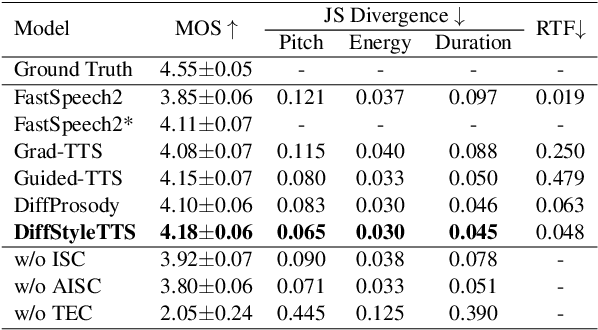
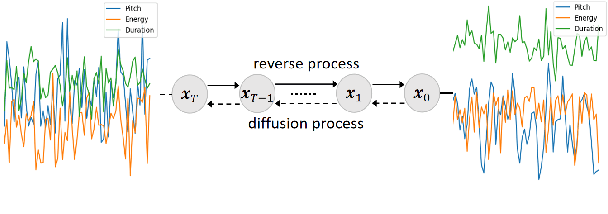
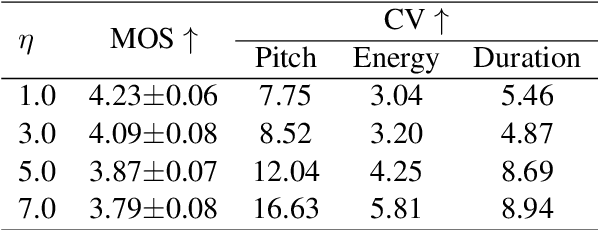
Human speech exhibits rich and flexible prosodic variations. To address the one-to-many mapping problem from text to prosody in a reasonable and flexible manner, we propose DiffStyleTTS, a multi-speaker acoustic model based on a conditional diffusion module and an improved classifier-free guidance, which hierarchically models speech prosodic features, and controls different prosodic styles to guide prosody prediction. Experiments show that our method outperforms all baselines in naturalness and achieves superior synthesis speed compared to three diffusion-based baselines. Additionally, by adjusting the guiding scale, DiffStyleTTS effectively controls the guidance intensity of the synthetic prosody.
* COLING 2025
Via