 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStyleTTS: Diffusion-based Hierarchical Prosody Modeling for Text-to-Speech with Diverse and Controllable Styles
Dec 04, 2024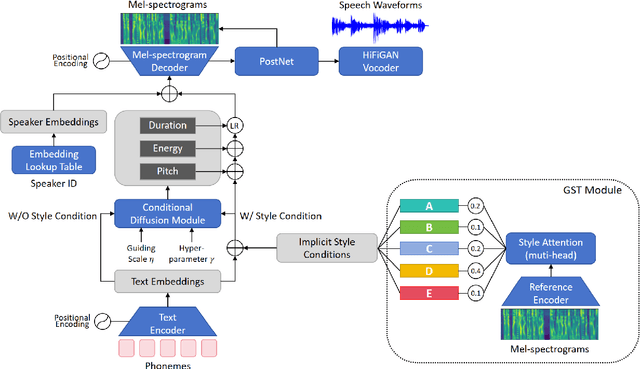
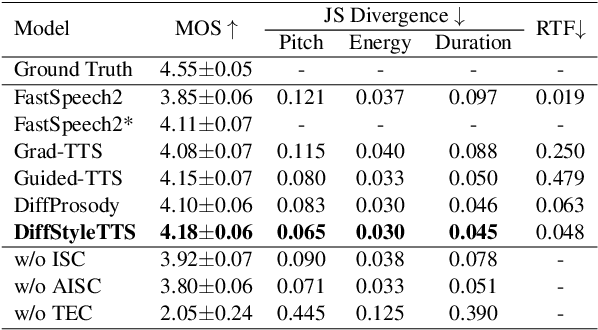
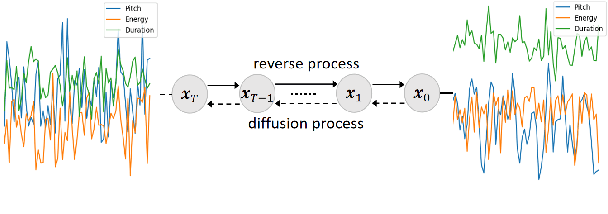
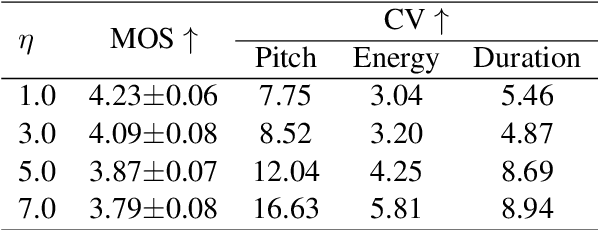
Human speech exhibits rich and flexible prosodic variations. To address the one-to-many mapping problem from text to prosody in a reasonable and flexible manner, we propose DiffStyleTTS, a multi-speaker acoustic model based on a conditional diffusion module and an improved classifier-free guidance, which hierarchically models speech prosodic features, and controls different prosodic styles to guide prosody prediction. Experiments show that our method outperforms all baselines in naturalness and achieves superior synthesis speed compared to three diffusion-based baselines. Additionally, by adjusting the guiding scale, DiffStyleTTS effectively controls the guidance intensity of the synthetic prosody.
Refining Self-Supervised Learnt Speech Representation using Brain Activations
Jun 12, 2024



It was shown in literature that speech representations extracted by self-supervised pre-trained models exhibit similarities with brain activations of human for speech perception and fine-tuning speech representation models on downstream tasks can further improve the similarity. However, it still remains unclear if this similarity can be used to optimize the pre-trained speech models. In this work, we therefore propose to use the brain activations recorded by fMRI to refine the often-used wav2vec2.0 model by aligning model representations toward human neural responses. Experimental results on SUPERB reveal that this operation is beneficial for several downstream tasks, e.g., speaker verification, automatic speech recognition, intent classification.One can then consider the proposed method as a new alternative to improve self-supervised speech models.