 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Traceability for Transparent ML Pipelines
Jan 21, 2026Modern machine learning systems are increasingly realised as multistage pipelines, yet existing transparency mechanisms typically operate at a model level: they describe what a system is and why it behaves as it does, but not how individual data samples are operationally recorded, tracked, and verified as they traverse the pipeline. This absence of verifiable, sample-level traceability leaves practitioners and users unable to determine whether a specific sample was used, when it was processed, or whether the corresponding records remain intact over time. We introduce FG-Trac, a model-agnostic framework that establishes verifiable, fine-grained sample-level traceability throughout machine learning pipelines. FG-Trac defines an explicit mechanism for capturing and verifying sample lifecycle events across preprocessing and training, computes contribution scores explicitly grounded in training checkpoints, and anchors these traces to tamper-evident cryptographic commitments. The framework integrates without modifying model architectures or training objectives, reconstructing complete and auditable data-usage histories with practical computational overhead. Experiments on a canonical convolutional neural network and a multimodal graph learning pipeline demonstrate that FG-Trac preserves predictive performance while enabling machine learning systems to furnish verifiable evidence of how individual samples were used and propagated during model execution.
IDMap: A Pseudo-Speaker Generator Framework Based on Speaker Identity Index to Vector Mapping
Nov 09, 2025Facilitated by the speech generation framework that disentangles speech into content, speaker, and prosody, voice anonymization is accomplished by substituting the original speaker embedding vector with that of a pseudo-speaker. In this framework, the pseudo-speaker generation forms a fundamental challenge. Current pseudo-speaker generation methods demonstrate limitations in the uniqueness of pseudo-speakers, consequently restricting their effectiveness in voice privacy protection. Besides, existing model-based methods suffer from heavy computation costs. Especially, in the large-scale scenario where a huge number of pseudo-speakers are generated, the limitations of uniqueness and computational inefficiency become more significant. To this end, this paper proposes a framework for pseudo-speaker generation, which establishes a mapping from speaker identity index to speaker vector in the feedforward architecture, termed IDMap. Specifically, the framework is specified into two models: IDMap-MLP and IDMap-Diff. Experiments were conducted on both small- and large-scale evaluation datasets. Small-scale evaluations on the LibriSpeech dataset validated the effectiveness of the proposed IDMap framework in enhancing the uniqueness of pseudo-speakers, thereby improving voice privacy protection, while at a reduced computational cost. Large-scale evaluations on the MLS and Common Voice datasets further justified the superiority of the IDMap framework regarding the stability of the voice privacy protection capability as the number of pseudo-speakers increased. Audio samples and open-source code can be found in https://github.com/VoicePrivacy/IDMap.
A Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025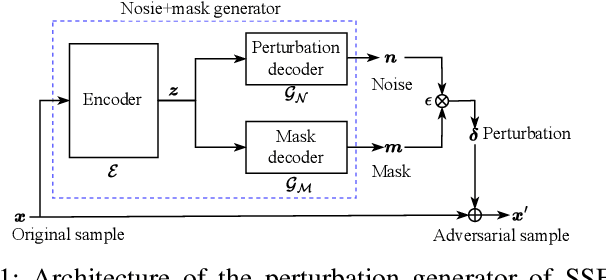
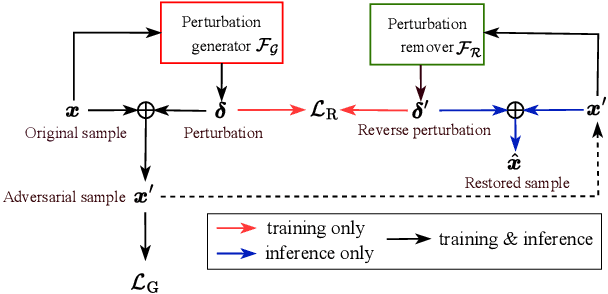
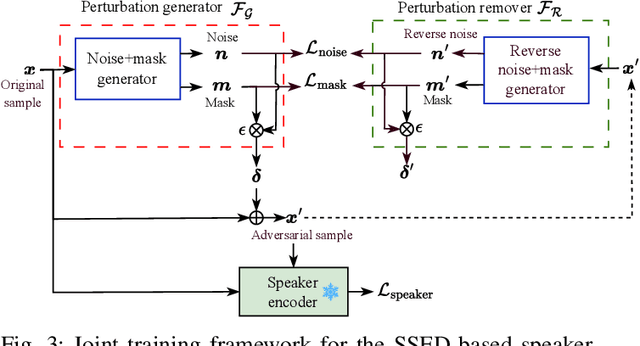

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.
Pinhole Effect on Linkability and Dispersion in Speaker Anonymization
Aug 23, 2025Speaker anonymization aims to conceal speaker-specific attributes in speech signals, making the anonymized speech unlinkable to the original speaker identity. Recent approaches achieve this by disentangling speech into content and speaker components, replacing the latter with pseudo speakers. The anonymized speech can be mapped either to a common pseudo speaker shared across utterances or to distinct pseudo speakers unique to each utterance. This paper investigates the impact of these mapping strategies on three key dimensions: speaker linkability, dispersion in the anonymized speaker space, and de-identification from the original identity. Our findings show that using distinct pseudo speakers increases speaker dispersion and reduces linkability compared to common pseudo-speaker mapping, thereby enhancing privacy preservation. These observations are interpreted through the proposed pinhole effect, a conceptual framework introduced to explain the relationship between mapping strategies and anonymization performance. The hypothesis is validated through empirical evaluation.
Introducing voice timbre attribute detection
May 14, 2025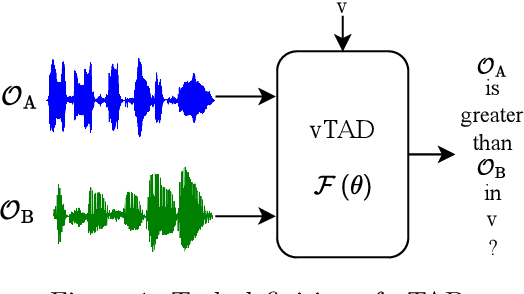
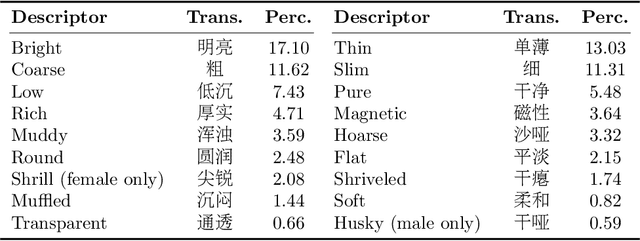
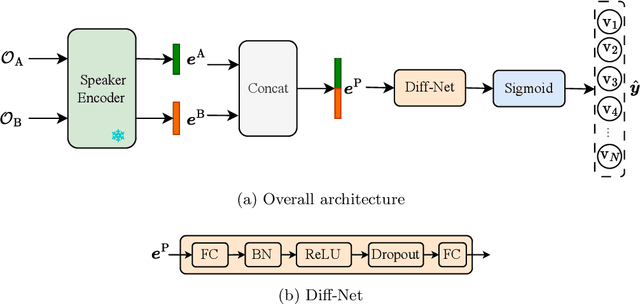
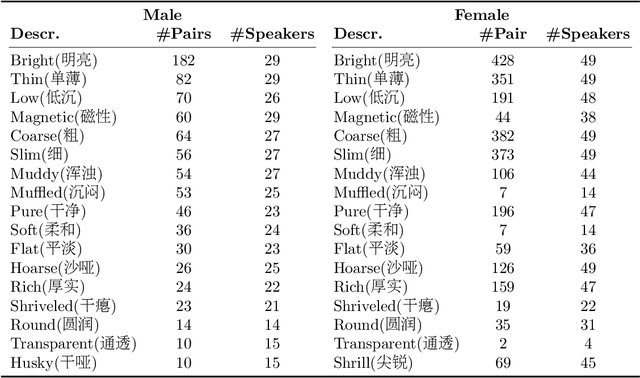
This paper focuses on explaining the timbre conveyed by speech signals and introduces a task termed voice timbre attribute detection (vTAD). In this task, voice timbre is explained with a set of sensory attributes describing its human perception. A pair of speech utterances is processed, and their intensity is compared in a designated timbre descriptor. Moreover, a framework is proposed, which is built upon the speaker embeddings extracted from the speech utterances. The investigation is conducted on the VCTK-RVA dataset. Experimental examinations on the ECAPA-TDNN and FACodec speaker encoders demonstrated that: 1) the ECAPA-TDNN speaker encoder was more capable in the seen scenario, where the testing speakers were included in the training set; 2) the FACodec speaker encoder was superior in the unseen scenario, where the testing speakers were not part of the training, indicating enhanced generalization capability. The VCTK-RVA dataset and open-source code are available on the website https://github.com/vTAD2025-Challenge/vTAD.
The Voice Timbre Attribute Detection 2025 Challenge Evaluation Plan
May 14, 2025Voice timbre refers to the unique quality or character of a person's voice that distinguishes it from others as perceived by human hearing. The Voice Timbre Attribute Detection (VtaD) 2025 challenge focuses on explaining the voice timbre attribute in a comparative manner. In this challenge, the human impression of voice timbre is verbalized with a set of sensory descriptors, including bright, coarse, soft, magnetic, and so on. The timbre is explained from the comparison between two voices in their intensity within a specific descriptor dimension. The VtaD 2025 challenge starts in May and culminates in a special proposal at the NCMMSC2025 conference in October 2025 in Zhenjiang, China.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025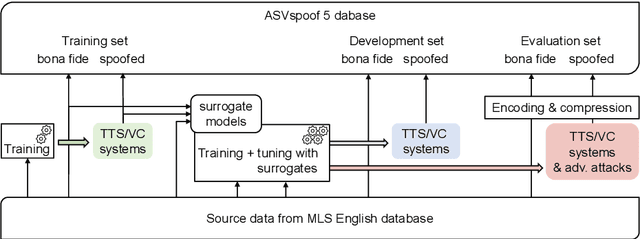

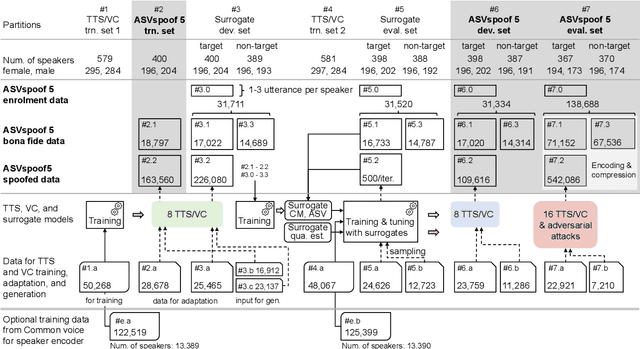
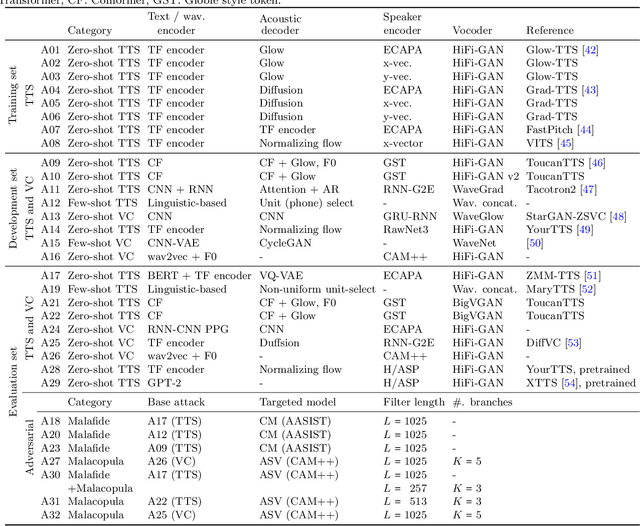
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Dec 12, 2024



Singing Voice Synthesis (SVS) {aims} to generate singing voices {of high} fidelity and expressiveness. {Conventional SVS systems usually utilize} an acoustic model to transform a music score into acoustic features, {followed by a vocoder to reconstruct the} singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
On the Generation and Removal of Speaker Adversarial Perturbation for Voice-Privacy Protection
Dec 12, 2024


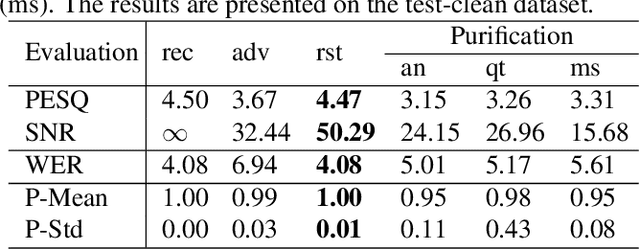
Neural networks are commonly known to be vulnerable to adversarial attacks mounted through subtle perturbation on the input data. Recent development in voice-privacy protection has shown the positive use cases of the same technique to conceal speaker's voice attribute with additive perturbation signal generated by an adversarial network. This paper examines the reversibility property where an entity generating the adversarial perturbations is authorized to remove them and restore original speech (e.g., the speaker him/herself). A similar technique could also be used by an investigator to deanonymize a voice-protected speech to restore criminals' identities in security and forensic analysis. In this setting, the perturbation generative module is assumed to be known in the removal process. To this end, a joint training of perturbation generation and removal modules is proposed. Experimental results on the LibriSpeech dataset demonstrated that the subtle perturbations added to the original speech can be predicted from the anonymized speech while achieving the goal of privacy protection. By removing these perturbations from the anonymized sample, the original speech can be restored. Audio samples can be found in \url{https://voiceprivacy.github.io/Perturbation-Generation-Removal/}.
* 6 pages, 3 figures, published to IEEE SLT Workshop 2024
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-filter Model
Oct 16, 2024



This paper presents an advanced end-to-end singing voice synthesis (SVS) system based on the source-filter mechanism that directly translates lyrical and melodic cues into expressive and high-fidelity human-like singing. Similarly to VISinger 2, the proposed system also utilizes training paradigms evolved from VITS and incorporates elements like the fundamental pitch (F0) predictor and waveform generation decoder. To address the issue that the coupling of mel-spectrogram features with F0 information may introduce errors during F0 prediction, we consider two strategies. Firstly, we leverage mel-cepstrum (mcep) features to decouple the intertwined mel-spectrogram and F0 characteristics. Secondly, inspired by the neural source-filter models, we introduce source excitation signals as the representation of F0 in the SVS system, aiming to capture pitch nuances more accurately. Meanwhile, differentiable mcep and F0 losses are employed as the waveform decoder supervision to fortify the prediction accuracy of speech envelope and pitch in the generated speech. Experiments on the Opencpop dataset demonstrate efficacy of the proposed model in synthesis quality and intonation accuracy.