 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Jan 08, 2025Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06\% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41\% and 23.58\% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Dec 12, 2024



Singing Voice Synthesis (SVS) {aims} to generate singing voices {of high} fidelity and expressiveness. {Conventional SVS systems usually utilize} an acoustic model to transform a music score into acoustic features, {followed by a vocoder to reconstruct the} singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
LCM-SVC: Latent Diffusion Model Based Singing Voice Conversion with Inference Acceleration via Latent Consistency Distillation
Aug 22, 2024Any-to-any singing voice conversion (SVC) aims to transfer a target singer's timbre to other songs using a short voice sample. However many diffusion model based any-to-any SVC methods, which have achieved impressive results, usually suffered from low efficiency caused by a mass of inference steps. In this paper, we propose LCM-SVC, a latent consistency distillation (LCD) based latent diffusion model (LDM) to accelerate inference speed. We achieved one-step or few-step inference while maintaining the high performance by distilling a pre-trained LDM based SVC model, which had the advantages of timbre decoupling and sound quality. Experimental results show that our proposed method can significantly reduce the inference time and largely preserve the sound quality and timbre similarity comparing with other state-of-the-art SVC models. Audio samples are available at https://sounddemos.github.io/lcm-svc.
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Jun 08, 2024


Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Mar 07, 2024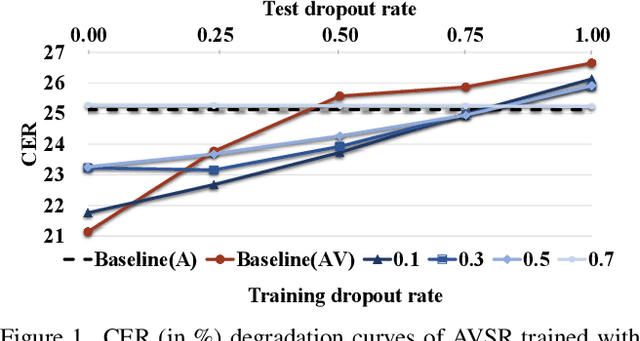

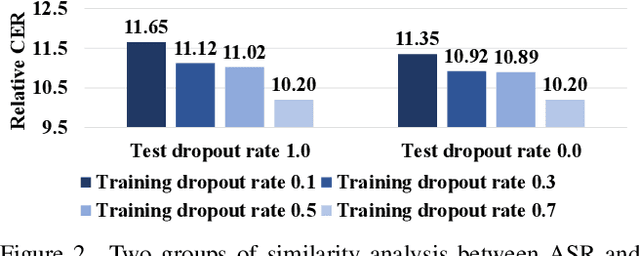
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR
Adversarial speech for voice privacy protection from Personalized Speech generation
Jan 22, 2024The rapid progress in personalized speech generation technology, including personalized text-to-speech (TTS) and voice conversion (VC), poses a challenge in distinguishing between generated and real speech for human listeners, resulting in an urgent demand in protecting speakers' voices from malicious misuse. In this regard, we propose a speaker protection method based on adversarial attacks. The proposed method perturbs speech signals by minimally altering the original speech while rendering downstream speech generation models unable to accurately generate the voice of the target speaker. For validation, we employ the open-source pre-trained YourTTS model for speech generation and protect the target speaker's speech in the white-box scenario. Automatic speaker verification (ASV) evaluations were carried out on the generated speech as the assessment of the voice protection capability. Our experimental results show that we successfully perturbed the speaker encoder of the YourTTS model using the gradient-based I-FGSM adversarial perturbation method. Furthermore, the adversarial perturbation is effective in preventing the YourTTS model from generating the speech of the target speaker. Audio samples can be found in https://voiceprivacy.github.io/Adeversarial-Speech-with-YourTTS.