 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
LLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems
Feb 19, 2025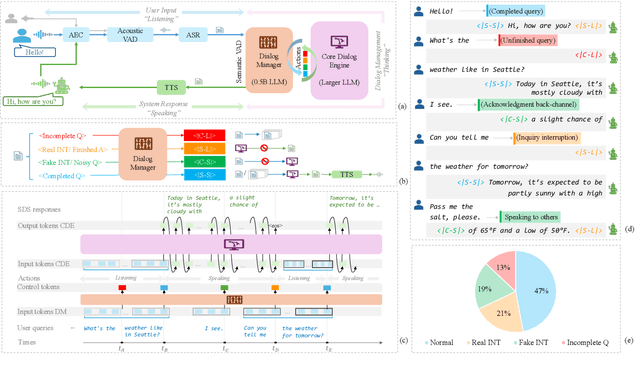
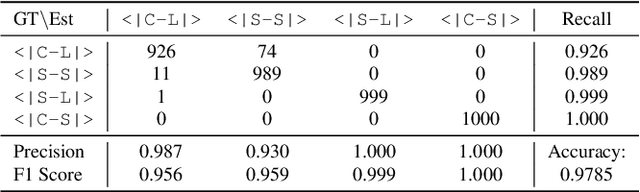
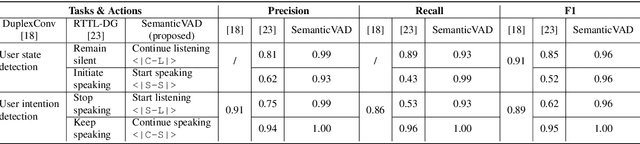

Achieving full-duplex communication in spoken dialogue systems (SDS) requires real-time coordination between listening, speaking, and thinking. This paper proposes a semantic voice activity detection (VAD) module as a dialogue manager (DM) to efficiently manage turn-taking in full-duplex SDS. Implemented as a lightweight (0.5B) LLM fine-tuned on full-duplex conversation data, the semantic VAD predicts four control tokens to regulate turn-switching and turn-keeping, distinguishing between intentional and unintentional barge-ins while detecting query completion for handling user pauses and hesitations. By processing input speech in short intervals, the semantic VAD enables real-time decision-making, while the core dialogue engine (CDE) is only activated for response generation, reducing computational overhead. This design allows independent DM optimization without retraining the CDE, balancing interaction accuracy and inference efficiency for scalable, next-generation full-duplex SDS.
STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Sep 13, 2024
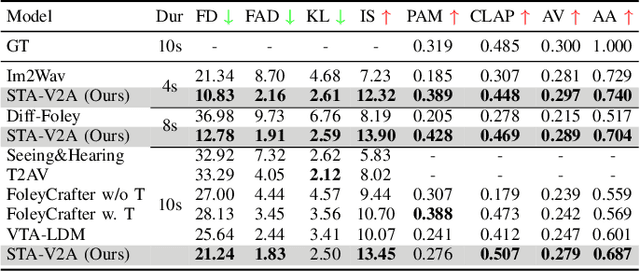


Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis
Sep 11, 2024



In this paper, we introduce SSR-Speech, a neural codec autoregressive model designed for stable, safe, and robust zero-shot text-based speech editing and text-to-speech synthesis. SSR-Speech is built on a Transformer decoder and incorporates classifier-free guidance to enhance the stability of the generation process. A watermark Encodec is proposed to embed frame-level watermarks into the edited regions of the speech so that which parts were edited can be detected. In addition, the waveform reconstruction leverages the original unedited speech segments, providing superior recovery compared to the Encodec model. Our approach achieves the state-of-the-art performance in the RealEdit speech editing task and the LibriTTS text-to-speech task, surpassing previous methods. Furthermore, SSR-Speech excels in multi-span speech editing and also demonstrates remarkable robustness to background sounds. Source code and demos are released.
LCM-SVC: Latent Diffusion Model Based Singing Voice Conversion with Inference Acceleration via Latent Consistency Distillation
Aug 22, 2024Any-to-any singing voice conversion (SVC) aims to transfer a target singer's timbre to other songs using a short voice sample. However many diffusion model based any-to-any SVC methods, which have achieved impressive results, usually suffered from low efficiency caused by a mass of inference steps. In this paper, we propose LCM-SVC, a latent consistency distillation (LCD) based latent diffusion model (LDM) to accelerate inference speed. We achieved one-step or few-step inference while maintaining the high performance by distilling a pre-trained LDM based SVC model, which had the advantages of timbre decoupling and sound quality. Experimental results show that our proposed method can significantly reduce the inference time and largely preserve the sound quality and timbre similarity comparing with other state-of-the-art SVC models. Audio samples are available at https://sounddemos.github.io/lcm-svc.
Video-to-Audio Generation with Hidden Alignment
Jul 10, 2024



Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
SMRU: Split-and-Merge Recurrent-based UNet for Acoustic Echo Cancellation and Noise Suppression
Jun 17, 2024The proliferation of deep neural networks has spawned the rapid development of acoustic echo cancellation and noise suppression, and plenty of prior arts have been proposed, which yield promising performance. Nevertheless, they rarely consider the deployment generality in different processing scenarios, such as edge devices, and cloud processing. To this end, this paper proposes a general model, termed SMRU, to cover different application scenarios. The novelty lies in two-fold. First, a multi-scale band split layer and band merge layer are proposed to effectively fuse local frequency bands for lower complexity modeling. Besides, by simulating the multi-resolution feature modeling characteristic of the classical UNet structure, a novel recurrent-dominated UNet is devised. It consists of multiple variable frame rate blocks, each of which involves the causal time down-/up-sampling layer with varying compression ratios and the dual-path structure for inter- and intra-band modeling. The model is configured from 50 M/s to 6.8 G/s in terms of MACs, and the experimental results show that the proposed approach yields competitive or even better performance over existing baselines, and has the full potential to adapt to more general scenarios with varying complexity requirements.
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Jun 08, 2024


Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Sep 04, 2023



Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contains noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HiFi-GAN, we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation FastSpeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav.