 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSC-Net: Integrating Fast Fourier Convolutions and Progressive Learning for Speech Bandwidth Extension
Jun 05, 2026Speech bandwidth extension (BWE) aims to reconstruct high-fidelity wideband audio from narrowband inputs. While recent approaches have made significant progress, they often struggle to reconstruct realistic high-frequency phase and harmonic structures, leading to perceptual artifacts. In this paper, we propose FSC-Net (Full-Spectrum Context Network), a parameter-efficient architecture designed to explicitly model cross-band harmonic dependencies. By integrating Fast Fourier Convolutions (FFCs) into a complex spectral mapping framework, FSC-Net expands its receptive field to the entire spectrum, capturing long-range frequency interactions effectively. To address the ill-posed nature of high-frequency generation, our novel frequency-progressive learning curriculum guides the network to reconstruct spectral details from coarse to fine. Experimental results on the VCTK and unseen EARS datasets demonstrate that FSC-Net delivers consistently strong reconstruction quality and generalization, particularly in the challenging VCTK 4 kHz-to-48 kHz task. Compared to scaled-up baselines, our model attains leading LSD and PESQ scores while maintaining a highly compact parameter footprint (1.54 M).
PASE: Leveraging the Phonological Prior of WavLM for Low-Hallucination Generative Speech Enhancement
Nov 17, 2025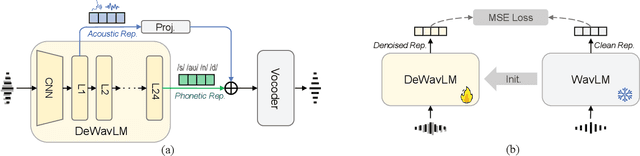
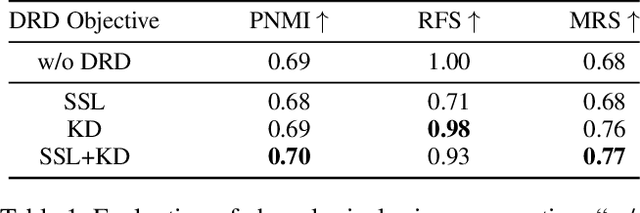
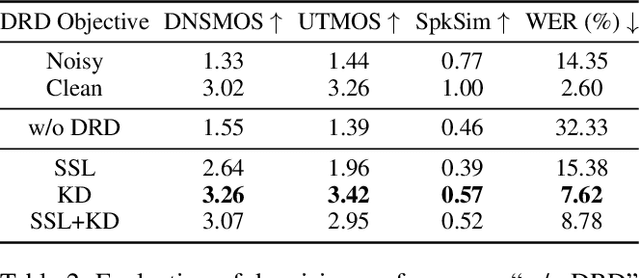
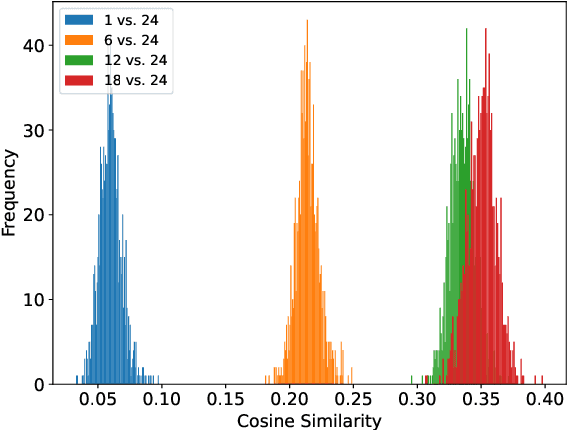
Generative models have shown remarkable performance in speech enhancement (SE), achieving superior perceptual quality over traditional discriminative approaches. However, existing generative SE approaches often overlook the risk of hallucination under severe noise, leading to incorrect spoken content or inconsistent speaker characteristics, which we term linguistic and acoustic hallucinations, respectively. We argue that linguistic hallucination stems from models' failure to constrain valid phonological structures and it is a more fundamental challenge. While language models (LMs) are well-suited for capturing the underlying speech structure through modeling the distribution of discrete tokens, existing approaches are limited in learning from noise-corrupted representations, which can lead to contaminated priors and hallucinations. To overcome these limitations, we propose the Phonologically Anchored Speech Enhancer (PASE), a generative SE framework that leverages the robust phonological prior embedded in the pre-trained WavLM model to mitigate hallucinations. First, we adapt WavLM into a denoising expert via representation distillation to clean its final-layer features. Guided by the model's intrinsic phonological prior, this process enables robust denoising while minimizing linguistic hallucinations. To further reduce acoustic hallucinations, we train the vocoder with a dual-stream representation: the high-level phonetic representation provides clean linguistic content, while a low-level acoustic representation retains speaker identity and prosody. Experimental results demonstrate that PASE not only surpasses state-of-the-art discriminative models in perceptual quality, but also significantly outperforms prior generative models with substantially lower linguistic and acoustic hallucinations.
TS-URGENet: A Three-stage Universal Robust and Generalizable Speech Enhancement Network
May 24, 2025Universal speech enhancement aims to handle input speech with different distortions and input formats. To tackle this challenge, we present TS-URGENet, a Three-Stage Universal, Robust, and Generalizable speech Enhancement Network. To address various distortions, the proposed system employs a novel three-stage architecture consisting of a filling stage, a separation stage, and a restoration stage. The filling stage mitigates packet loss by preliminarily filling lost regions under noise interference, ensuring signal continuity. The separation stage suppresses noise, reverberation, and clipping distortion to improve speech clarity. Finally, the restoration stage compensates for bandwidth limitation, codec artifacts, and residual packet loss distortion, refining the overall speech quality. Our proposed TS-URGENet achieved outstanding performance in the Interspeech 2025 URGENT Challenge, ranking 2nd in Track 1.
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
SNR-Progressive Model with Harmonic Compensation for Low-SNR Speech Enhancement
Jun 24, 2024
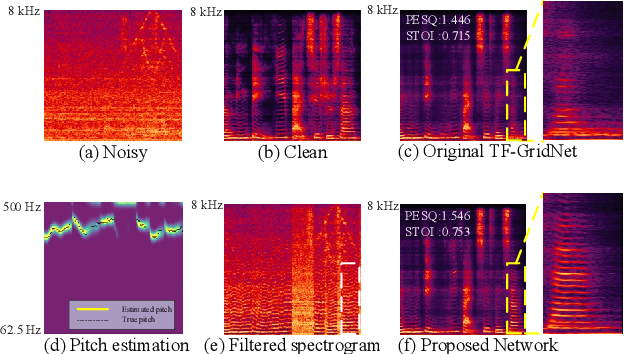
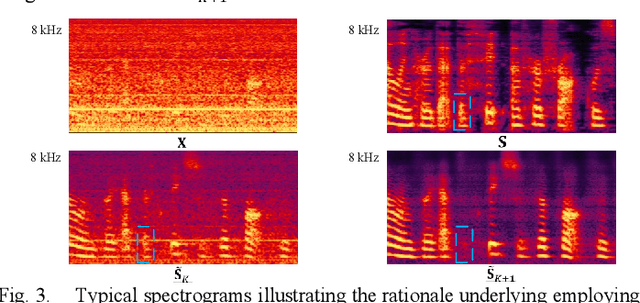
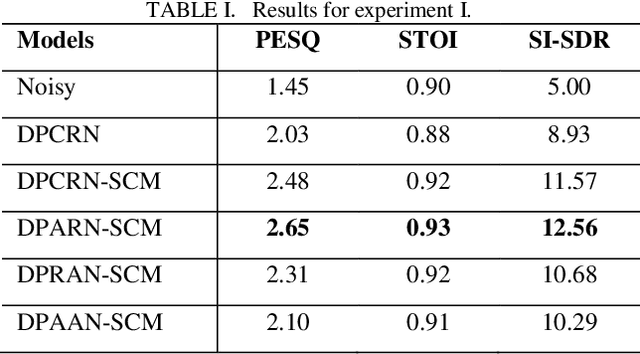
Despite significant progress made in the last decade, deep neural network (DNN) based speech enhancement (SE) still faces the challenge of notable degradation in the quality of recovered speech under low signal-to-noise ratio (SNR) conditions. In this letter, we propose an SNR-progressive speech enhancement model with harmonic compensation for low-SNR SE. Reliable pitch estimation is obtained from the intermediate output, which has the benefit of retaining more speech components than the coarse estimate while possessing a significant higher SNR than the input noisy speech. An effective harmonic compensation mechanism is introduced for better harmonic recovery. Extensive ex-periments demonstrate the advantage of our proposed model. A multi-modal speech extraction system based on the proposed backbone model ranks first in the ICASSP 2024 MISP Challenge: https://mispchallenge.github.io/mispchallenge2023/index.html.
Attention does not guarantee best performance in speech enhancement
Feb 11, 2023Attention mechanism has been widely utilized in speech enhancement (SE) because theoretically it can effectively model the long-term inherent connection of signal both in time domain and spectrum domain. However, the generally used global attention mechanism might not be the best choice since the adjacent information naturally imposes more influence than the far-apart information in speech enhancement. In this paper, we validate this conjecture by replacing attention with RNN in two typical state-of-the-art (SOTA) models, multi-scale temporal frequency convolutional network (MTFAA) with axial attention and conformer-based metric-GAN network (CMGAN).
Local spectral attention for full-band speech enhancement
Feb 11, 2023Attention mechanism has been widely utilized in speech enhancement (SE) because theoretically it can effectively model the inherent connection of signal both in time domain and spectrum domain. Usually, the span of attention is limited in time domain while the attention in frequency domain spans the whole frequency range. In this paper, we notice that the attention over the whole frequency range hampers the inference for full-band SE and possibly leads to excessive residual noise. To alleviate this problem, we introduce local spectral attention (LSA) into full-band SE model by limiting the span of attention. The ablation test on the state-of-the-art (SOTA) full-band SE model reveals that the local frequency attention can effectively improve overall performance. The improved model achieves the best objective score on the full-band VoiceBank+DEMAND set.
A light-weight full-band speech enhancement model
Jul 03, 2022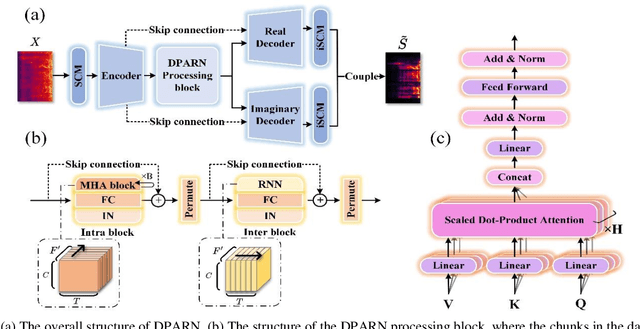
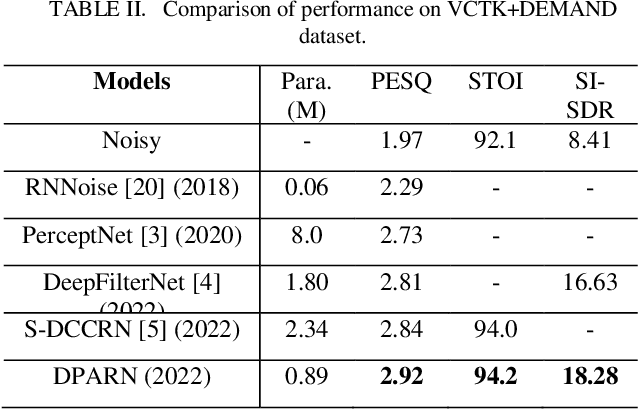
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
A two-stage full-band speech enhancement model with effective spectral compression mapping
Jun 27, 2022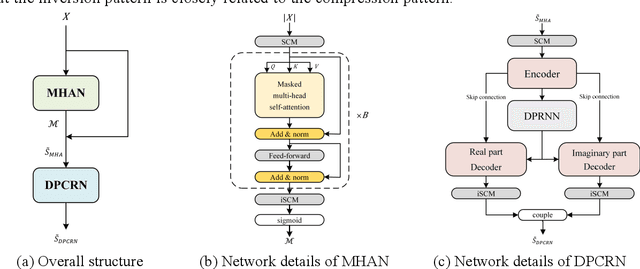
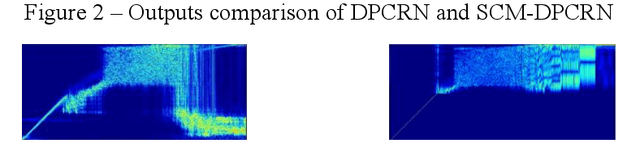


The direct expansion of deep neural network (DNN) based wide-band speech enhancement (SE) to full-band processing faces the challenge of low frequency resolution in low frequency range, which would highly likely lead to deteriorated performance of the model. In this paper, we propose a learnable spectral compression mapping (SCM) to effectively compress the high frequency components so that they can be processed in a more efficient manner. By doing so, the model can pay more attention to low and middle frequency range, where most of the speech power is concentrated. Instead of suppressing noise in a single network structure, we first estimate a spectral magnitude mask, converting the speech to a high signal-to-ratio (SNR) state, and then utilize a subsequent model to further optimize the real and imaginary mask of the pre-enhanced signal. We conduct comprehensive experiments to validate the efficacy of the proposed method.