 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNR-Progressive Model with Harmonic Compensation for Low-SNR Speech Enhancement
Jun 24, 2024
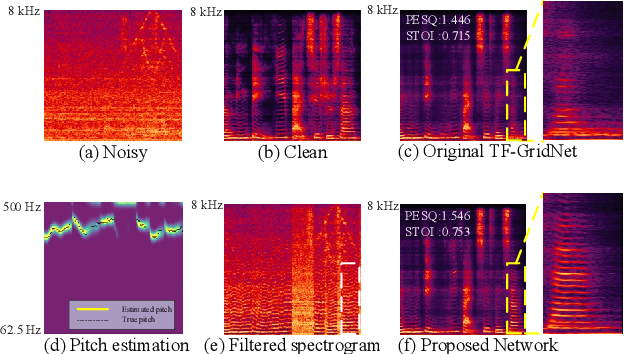
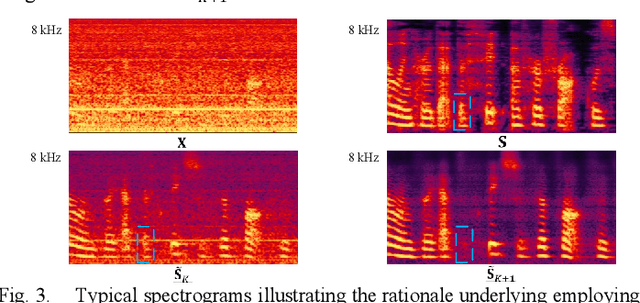
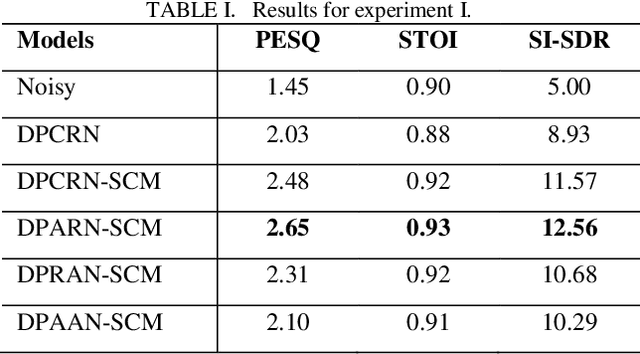
Despite significant progress made in the last decade, deep neural network (DNN) based speech enhancement (SE) still faces the challenge of notable degradation in the quality of recovered speech under low signal-to-noise ratio (SNR) conditions. In this letter, we propose an SNR-progressive speech enhancement model with harmonic compensation for low-SNR SE. Reliable pitch estimation is obtained from the intermediate output, which has the benefit of retaining more speech components than the coarse estimate while possessing a significant higher SNR than the input noisy speech. An effective harmonic compensation mechanism is introduced for better harmonic recovery. Extensive ex-periments demonstrate the advantage of our proposed model. A multi-modal speech extraction system based on the proposed backbone model ranks first in the ICASSP 2024 MISP Challenge: https://mispchallenge.github.io/mispchallenge2023/index.html.
Personalized speech enhancement combining band-split RNN and speaker attentive module
Feb 20, 2023
Target speaker information can be utilized in speech enhancement (SE) models to more effectively extract the desired speech. Previous works introduce the speaker embedding into speech enhancement models by means of concatenation or affine transformation. In this paper, we propose a speaker attentive module to calculate the attention scores between the speaker embedding and the intermediate features, which are used to rescale the features. By merging this module in the state-of-the-art SE model, we construct the personalized SE model for ICASSP Signal Processing Grand Challenge: DNS Challenge 5 (2023). Our system achieves a final score of 0.529 on the blind test set of track1 and 0.549 on track2.
Local spectral attention for full-band speech enhancement
Feb 11, 2023Attention mechanism has been widely utilized in speech enhancement (SE) because theoretically it can effectively model the inherent connection of signal both in time domain and spectrum domain. Usually, the span of attention is limited in time domain while the attention in frequency domain spans the whole frequency range. In this paper, we notice that the attention over the whole frequency range hampers the inference for full-band SE and possibly leads to excessive residual noise. To alleviate this problem, we introduce local spectral attention (LSA) into full-band SE model by limiting the span of attention. The ablation test on the state-of-the-art (SOTA) full-band SE model reveals that the local frequency attention can effectively improve overall performance. The improved model achieves the best objective score on the full-band VoiceBank+DEMAND set.
Attention does not guarantee best performance in speech enhancement
Feb 11, 2023Attention mechanism has been widely utilized in speech enhancement (SE) because theoretically it can effectively model the long-term inherent connection of signal both in time domain and spectrum domain. However, the generally used global attention mechanism might not be the best choice since the adjacent information naturally imposes more influence than the far-apart information in speech enhancement. In this paper, we validate this conjecture by replacing attention with RNN in two typical state-of-the-art (SOTA) models, multi-scale temporal frequency convolutional network (MTFAA) with axial attention and conformer-based metric-GAN network (CMGAN).
A light-weight full-band speech enhancement model
Jul 03, 2022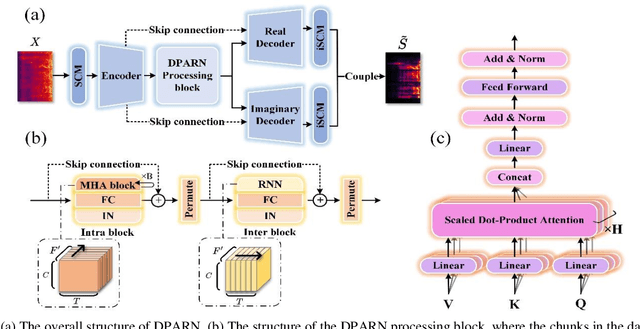
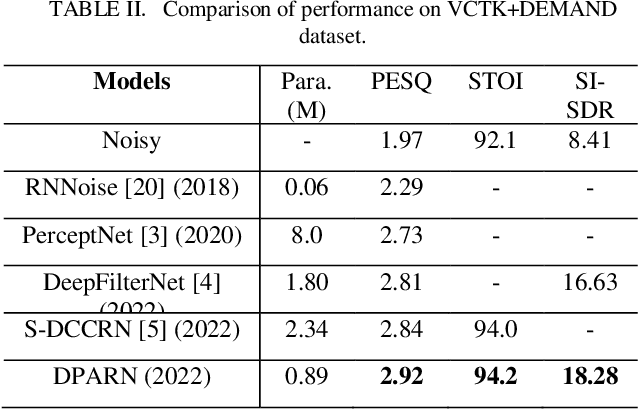
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
A two-stage full-band speech enhancement model with effective spectral compression mapping
Jun 27, 2022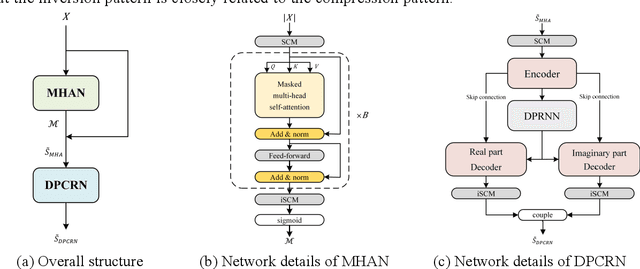
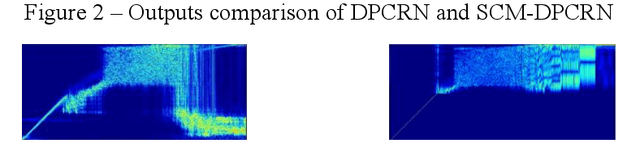


The direct expansion of deep neural network (DNN) based wide-band speech enhancement (SE) to full-band processing faces the challenge of low frequency resolution in low frequency range, which would highly likely lead to deteriorated performance of the model. In this paper, we propose a learnable spectral compression mapping (SCM) to effectively compress the high frequency components so that they can be processed in a more efficient manner. By doing so, the model can pay more attention to low and middle frequency range, where most of the speech power is concentrated. Instead of suppressing noise in a single network structure, we first estimate a spectral magnitude mask, converting the speech to a high signal-to-ratio (SNR) state, and then utilize a subsequent model to further optimize the real and imaginary mask of the pre-enhanced signal. We conduct comprehensive experiments to validate the efficacy of the proposed method.