 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-URGENet: A Three-stage Universal Robust and Generalizable Speech Enhancement Network
May 24, 2025Universal speech enhancement aims to handle input speech with different distortions and input formats. To tackle this challenge, we present TS-URGENet, a Three-Stage Universal, Robust, and Generalizable speech Enhancement Network. To address various distortions, the proposed system employs a novel three-stage architecture consisting of a filling stage, a separation stage, and a restoration stage. The filling stage mitigates packet loss by preliminarily filling lost regions under noise interference, ensuring signal continuity. The separation stage suppresses noise, reverberation, and clipping distortion to improve speech clarity. Finally, the restoration stage compensates for bandwidth limitation, codec artifacts, and residual packet loss distortion, refining the overall speech quality. Our proposed TS-URGENet achieved outstanding performance in the Interspeech 2025 URGENT Challenge, ranking 2nd in Track 1.
Adaptive Convolution for CNN-based Speech Enhancement Models
Feb 20, 2025Deep learning-based speech enhancement methods have significantly improved speech quality and intelligibility. Convolutional neural networks (CNNs) have been proven to be essential components of many high-performance models. In this paper, we introduce adaptive convolution, an efficient and versatile convolutional module that enhances the model's capability to adaptively represent speech signals. Adaptive convolution performs frame-wise causal dynamic convolution, generating time-varying kernels for each frame by assembling multiple parallel candidate kernels. A Lightweight attention mechanism leverages both current and historical information to assign adaptive weights to each candidate kernel, guiding their aggregation. This enables the convolution operation to adapt to frame-level speech spectral features, leading to more efficient extraction and reconstruction. Experimental results on various CNN-based models demonstrate that adaptive convolution significantly improves the performance with negligible increases in computational complexity, especially for lightweight models. Furthermore, we propose the adaptive convolutional recurrent network (AdaptCRN), an ultra-lightweight model that incorporates adaptive convolution and an efficient encoder-decoder design, achieving superior performance compared to models with similar or even higher computational costs.
Adversarial Neural Networks in Medical Imaging Advancements and Challenges in Semantic Segmentation
Oct 17, 2024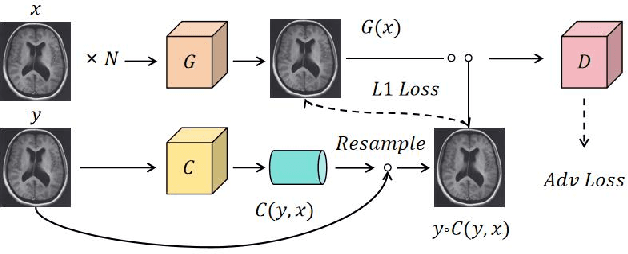
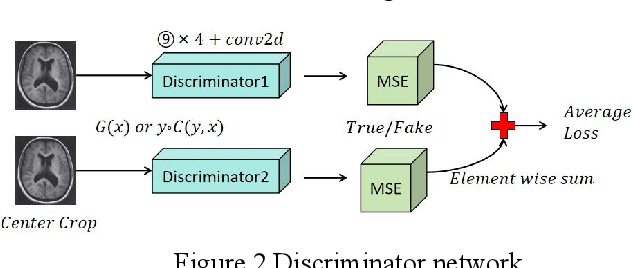
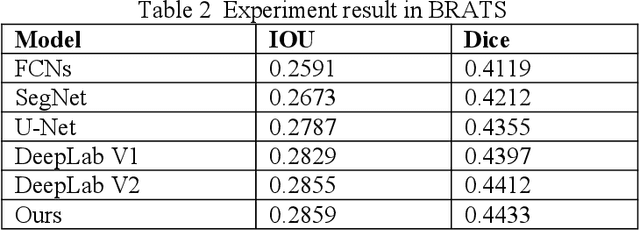
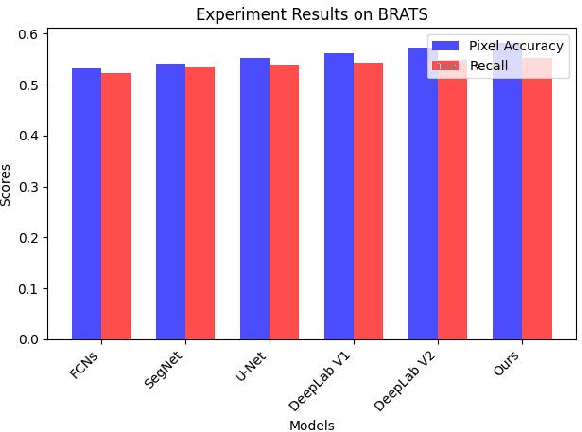
Recent advancements in artificial intelligence (AI) have precipitated a paradigm shift in medical imaging, particularly revolutionizing the domain of brain imaging. This paper systematically investigates the integration of deep learning -- a principal branch of AI -- into the semantic segmentation of brain images. Semantic segmentation serves as an indispensable technique for the delineation of discrete anatomical structures and the identification of pathological markers, essential for the diagnosis of complex neurological disorders. Historically, the reliance on manual interpretation by radiologists, while noteworthy for its accuracy, is plagued by inherent subjectivity and inter-observer variability. This limitation becomes more pronounced with the exponential increase in imaging data, which traditional methods struggle to process efficiently and effectively. In response to these challenges, this study introduces the application of adversarial neural networks, a novel AI approach that not only automates but also refines the semantic segmentation process. By leveraging these advanced neural networks, our approach enhances the precision of diagnostic outputs, reducing human error and increasing the throughput of imaging data analysis. The paper provides a detailed discussion on how adversarial neural networks facilitate a more robust, objective, and scalable solution, thereby significantly improving diagnostic accuracies in neurological evaluations. This exploration highlights the transformative impact of AI on medical imaging, setting a new benchmark for future research and clinical practice in neurology.
Optimizing YOLOv5s Object Detection through Knowledge Distillation algorithm
Oct 16, 2024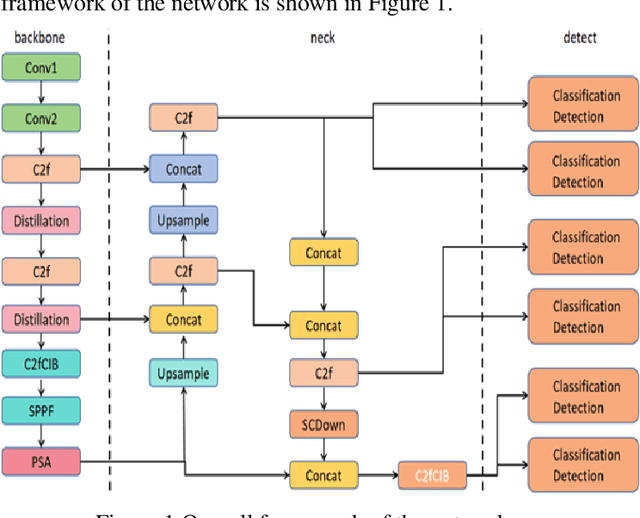
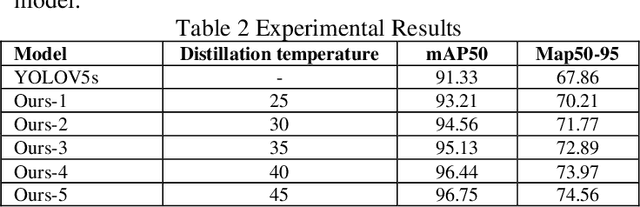
This paper explores the application of knowledge distillation technology in target detection tasks, especially the impact of different distillation temperatures on the performance of student models. By using YOLOv5l as the teacher network and a smaller YOLOv5s as the student network, we found that with the increase of distillation temperature, the student's detection accuracy gradually improved, and finally achieved mAP50 and mAP50-95 indicators that were better than the original YOLOv5s model at a specific temperature. Experimental results show that appropriate knowledge distillation strategies can not only improve the accuracy of the model but also help improve the reliability and stability of the model in practical applications. This paper also records in detail the accuracy curve and loss function descent curve during the model training process and shows that the model converges to a stable state after 150 training cycles. These findings provide a theoretical basis and technical reference for further optimizing target detection algorithms.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Research on Early Warning Model of Cardiovascular Disease Based on Computer Deep Learning
Jun 13, 2024This project intends to study a cardiovascular disease risk early warning model based on one-dimensional convolutional neural networks. First, the missing values of 13 physiological and symptom indicators such as patient age, blood glucose, cholesterol, and chest pain were filled and Z-score was standardized. The convolutional neural network is converted into a 2D matrix, the convolution function of 1,3, and 5 is used for the first-order convolution operation, and the Max Pooling algorithm is adopted for dimension reduction. Set the learning rate and output rate. It is optimized by the Adam algorithm. The result of classification is output by a soft classifier. This study was conducted based on Statlog in the UCI database and heart disease database respectively. The empirical data indicate that the forecasting precision of this technique has been enhanced by 11.2%, relative to conventional approaches, while there is a significant improvement in the logarithmic curve fitting. The efficacy and applicability of the novel approach are corroborated through the examination employing a one-dimensional convolutional neural network.
Semi-blind source separation using convolutive transfer function for nonlinear acoustic echo cancellation
Jul 04, 2022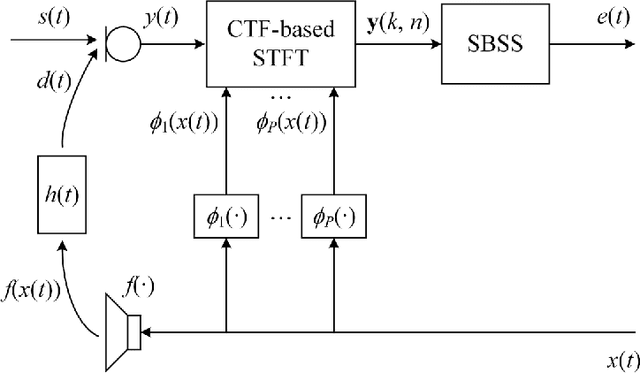
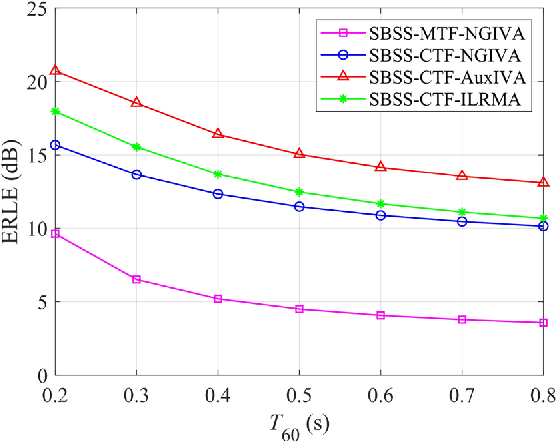
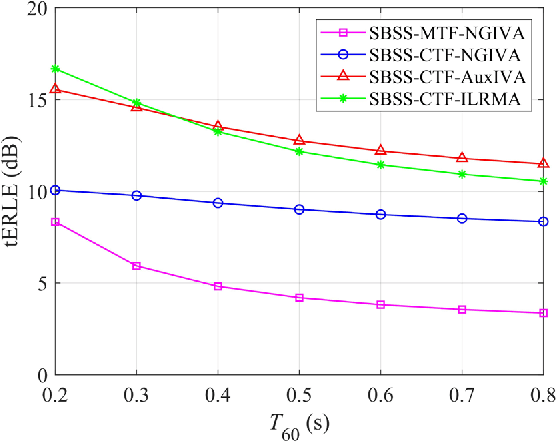
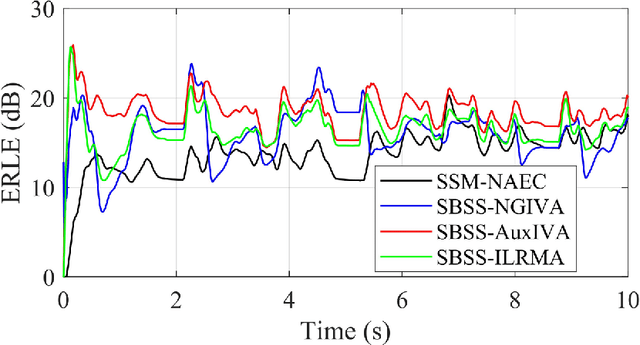
The recently proposed semi-blind source separation (SBSS) method for nonlinear acoustic echo cancellation (NAEC) outperforms adaptive NAEC in attenuating the nonlinear acoustic echo. However, the multiplicative transfer function (MTF) approximation makes it unsuitable for real-time applications especially in highly reverberant environments, and the natural gradient makes it hard to balance well between fast convergence speed and stability. In this paper, we propose two more effective SBSS methods based on auxiliary-function-based independent vector analysis (AuxIVA) and independent low-rank matrix analysis (ILRMA). The convolutive transfer function (CTF) approximation is used instead of MTF so that a long impulse response can be modeled with a short latency. The optimization schemes used in AuxIVA and ILRMA are carefully regularized according to the constrained demixing matrix of NAEC. Experimental results validate significantly better echo cancellation performance of the proposed methods.
NER-BERT: A Pre-trained Model for Low-Resource Entity Tagging
Dec 01, 2021
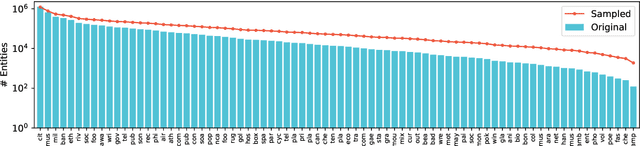
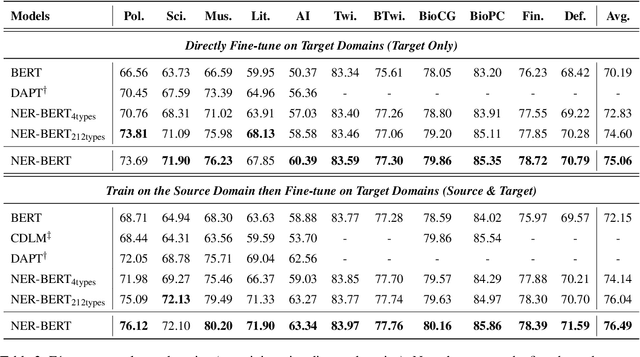
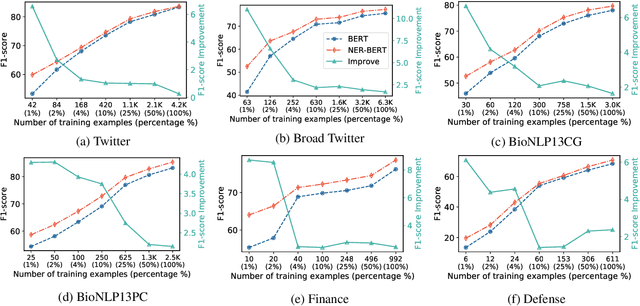
Named entity recognition (NER) models generally perform poorly when large training datasets are unavailable for low-resource domains. Recently, pre-training a large-scale language model has become a promising direction for coping with the data scarcity issue. However, the underlying discrepancies between the language modeling and NER task could limit the models' performance, and pre-training for the NER task has rarely been studied since the collected NER datasets are generally small or large but with low quality. In this paper, we construct a massive NER corpus with a relatively high quality, and we pre-train a NER-BERT model based on the created dataset. Experimental results show that our pre-trained model can significantly outperform BERT as well as other strong baselines in low-resource scenarios across nine diverse domains. Moreover, a visualization of entity representations further indicates the effectiveness of NER-BERT for categorizing a variety of entities.
BiToD: A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling
Jun 05, 2021



Task-oriented dialogue (ToD) benchmarks provide an important avenue to measure progress and develop better conversational agents. However, existing datasets for end-to-end ToD modeling are limited to a single language, hindering the development of robust end-to-end ToD systems for multilingual countries and regions. Here we introduce BiToD, the first bilingual multi-domain dataset for end-to-end task-oriented dialogue modeling. BiToD contains over 7k multi-domain dialogues (144k utterances) with a large and realistic bilingual knowledge base. It serves as an effective benchmark for evaluating bilingual ToD systems and cross-lingual transfer learning approaches. We provide state-of-the-art baselines under three evaluation settings (monolingual, bilingual, and cross-lingual). The analysis of our baselines in different settings highlights 1) the effectiveness of training a bilingual ToD system compared to two independent monolingual ToD systems, and 2) the potential of leveraging a bilingual knowledge base and cross-lingual transfer learning to improve the system performance under low resource condition.