 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNER-BERT: A Pre-trained Model for Low-Resource Entity Tagging
Paper and Code

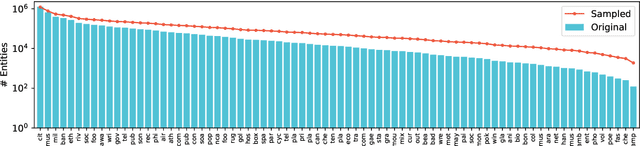
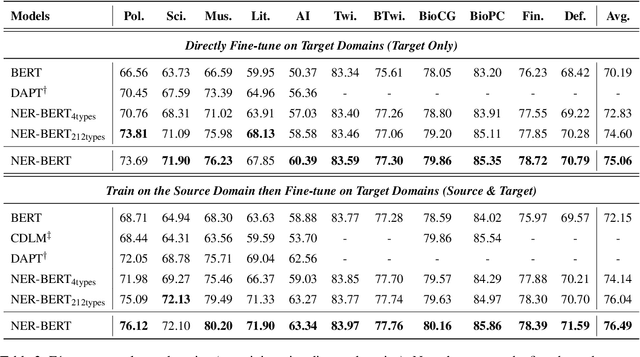
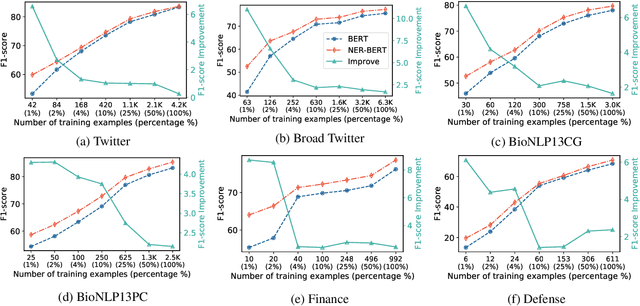
Named entity recognition (NER) models generally perform poorly when large training datasets are unavailable for low-resource domains. Recently, pre-training a large-scale language model has become a promising direction for coping with the data scarcity issue. However, the underlying discrepancies between the language modeling and NER task could limit the models' performance, and pre-training for the NER task has rarely been studied since the collected NER datasets are generally small or large but with low quality. In this paper, we construct a massive NER corpus with a relatively high quality, and we pre-train a NER-BERT model based on the created dataset. Experimental results show that our pre-trained model can significantly outperform BERT as well as other strong baselines in low-resource scenarios across nine diverse domains. Moreover, a visualization of entity representations further indicates the effectiveness of NER-BERT for categorizing a variety of entities.