 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Tells When to Replan: Denoising-Variance Adaptive Chunking for Flow-Based Robot Policies
Jun 02, 2026Action chunking has become a common inference strategy for flow-based robot policies, improving action coherence by modeling multi-step temporal dependencies in demonstrations. However, the execution horizon is still typically set as an empirical fixed value, overlooking that predictable free-space motions and precision-critical interaction phases often require different replanning frequencies. In this work, we first show that the denoising process of flow-based policies contains an intrinsic signal of task phases: clean-action estimates remain stable during predictable motion phases, but fluctuate more strongly around contact-rich or precision-sensitive operations. Motivated by this observation, we propose DVAC (Denoising-Variance Adaptive Chunking), a test-time method that adaptively determines how many actions to execute from each predicted chunk. DVAC measures the variance of clean-action estimates over the final denoising steps, executes the stable low-variance prefix, and replans before high-variance future actions are committed. To transfer across tasks and rollouts, DVAC further calibrates the threshold with a rolling estimate of the local variance scale. Experiments on LIBERO, RoboTwin, CALVIN, and real-world manipulation show that DVAC improves task success while reducing replanning frequency. With a $π_{0.5}$-based policy, DVAC improves LIBERO success from 94.75% to 98.00% and reduces replanning by 43.0%, while also yielding aggregate gains on RoboTwin and CALVIN and improving real-world execution efficiency.
DriveWAM: Video Generative Priors Enable Scalable World-Action Modeling for Autonomous Driving
May 27, 2026Pretrained foundation models have become an important basis for end-to-end autonomous driving. In contrast to vision-language models pretrained primarily on static image-text pairs, video generative models capture temporal dynamics and motion priors that are naturally suited for driving. We present DriveWAM, a driving world-action model that adapts a pretrained video diffusion transformer into an autoregressive video-action policy. DriveWAM organizes video and action streams into a unified temporal token sequence and trains them under a joint flow-matching objective, preserving the pretrained video-generation architecture while adapting its large-scale video priors to action generation. To incorporate high-level scene understanding, we introduce scene-evolving driving guidance, where a frozen VLM produces chunk-specific semantic intent to guide video-action generation. To keep long-horizon rollout bounded, we further introduce selective KV memory, which maintains bounded modality-aware video and action memory pools through relevance-redundancy cache selection at inference time. Experiments on NAVSIM and the PhysicalAI-Autonomous-Vehicles benchmark show that DriveWAM achieves strong planning performance, and a data-scaling study from 4k to 100k driving clips further confirms the scaling potential of world-action modeling for end-to-end autonomous driving.
ESCAPE: Episodic Spatial Memory and Adaptive Execution Policy for Long-Horizon Mobile Manipulation
Apr 15, 2026Coordinating navigation and manipulation with robust performance is essential for embodied AI in complex indoor environments. However, as tasks extend over long horizons, existing methods often struggle due to catastrophic forgetting, spatial inconsistency, and rigid execution. To address these issues, we propose ESCAPE (Episodic Spatial Memory Coupled with an Adaptive Policy for Execution), operating through a tightly coupled perception-grounding-execution workflow. For robust perception, ESCAPE features a Spatio-Temporal Fusion Mapping module to autoregressively construct a depth-free, persistent 3D spatial memory, alongside a Memory-Driven Target Grounding module for precise interaction mask generation. To achieve flexible action, our Adaptive Execution Policy dynamically orchestrates proactive global navigation and reactive local manipulation to seize opportunistic targets. ESCAPE achieves state-of-the-art performance on the ALFRED benchmark, reaching 65.09% and 60.79% success rates in test seen and unseen environments with step-by-step instructions. By reducing redundant exploration, our ESCAPE attains substantial improvements in path-length-weighted metrics and maintains robust performance (61.24% / 56.04%) even without detailed guidance for long-horizon tasks.
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Dec 18, 2025Vision-Language-Action (VLA) models achieve strong generalization in robotic manipulation but remain largely reactive and 2D-centric, making them unreliable in tasks that require precise 3D reasoning. We propose GeoPredict, a geometry-aware VLA framework that augments a continuous-action policy with predictive kinematic and geometric priors. GeoPredict introduces a trajectory-level module that encodes motion history and predicts multi-step 3D keypoint trajectories of robot arms, and a predictive 3D Gaussian geometry module that forecasts workspace geometry with track-guided refinement along future keypoint trajectories. These predictive modules serve exclusively as training-time supervision through depth-based rendering, while inference requires only lightweight additional query tokens without invoking any 3D decoding. Experiments on RoboCasa Human-50, LIBERO, and real-world manipulation tasks show that GeoPredict consistently outperforms strong VLA baselines, especially in geometry-intensive and spatially demanding scenarios.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
Action Unit Enhance Dynamic Facial Expression Recognition
Jul 10, 2025Dynamic Facial Expression Recognition(DFER) is a rapidly evolving field of research that focuses on the recognition of time-series facial expressions. While previous research on DFER has concentrated on feature learning from a deep learning perspective, we put forward an AU-enhanced Dynamic Facial Expression Recognition architecture, namely AU-DFER, that incorporates AU-expression knowledge to enhance the effectiveness of deep learning modeling. In particular, the contribution of the Action Units(AUs) to different expressions is quantified, and a weight matrix is designed to incorporate a priori knowledge. Subsequently, the knowledge is integrated with the learning outcomes of a conventional deep learning network through the introduction of AU loss. The design is incorporated into the existing optimal model for dynamic expression recognition for the purpose of validation. Experiments are conducted on three recent mainstream open-source approaches to DFER on the principal datasets in this field. The results demonstrate that the proposed architecture outperforms the state-of-the-art(SOTA) methods without the need for additional arithmetic and generally produces improved results. Furthermore, we investigate the potential of AU loss function redesign to address data label imbalance issues in established dynamic expression datasets. To the best of our knowledge, this is the first attempt to integrate quantified AU-expression knowledge into various DFER models. We also devise strategies to tackle label imbalance, or minor class problems. Our findings suggest that employing a diverse strategy of loss function design can enhance the effectiveness of DFER. This underscores the criticality of addressing data imbalance challenges in mainstream datasets within this domain. The source code is available at https://github.com/Cross-Innovation-Lab/AU-DFER.
DriveX: Omni Scene Modeling for Learning Generalizable World Knowledge in Autonomous Driving
May 25, 2025Data-driven learning has advanced autonomous driving, yet task-specific models struggle with out-of-distribution scenarios due to their narrow optimization objectives and reliance on costly annotated data. We present DriveX, a self-supervised world model that learns generalizable scene dynamics and holistic representations (geometric, semantic, and motion) from large-scale driving videos. DriveX introduces Omni Scene Modeling (OSM), a module that unifies multimodal supervision-3D point cloud forecasting, 2D semantic representation, and image generation-to capture comprehensive scene evolution. To simplify learning complex dynamics, we propose a decoupled latent world modeling strategy that separates world representation learning from future state decoding, augmented by dynamic-aware ray sampling to enhance motion modeling. For downstream adaptation, we design Future Spatial Attention (FSA), a unified paradigm that dynamically aggregates spatiotemporal features from DriveX's predictions to enhance task-specific inference. Extensive experiments demonstrate DriveX's effectiveness: it achieves significant improvements in 3D future point cloud prediction over prior work, while attaining state-of-the-art results on diverse tasks including occupancy prediction, flow estimation, and end-to-end driving. These results validate DriveX's capability as a general-purpose world model, paving the way for robust and unified autonomous driving frameworks.
AlphaFin: Benchmarking Financial Analysis with Retrieval-Augmented Stock-Chain Framework
Mar 19, 2024
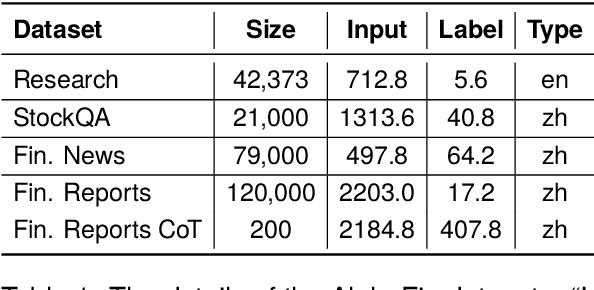
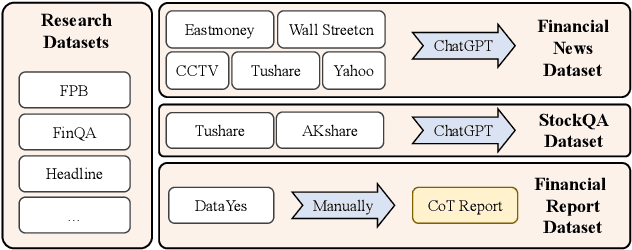
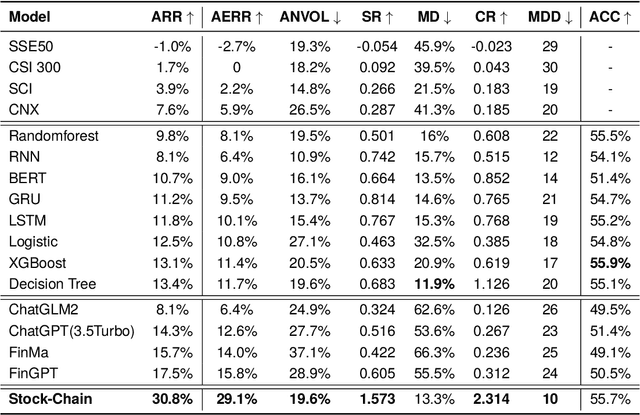
The task of financial analysis primarily encompasses two key areas: stock trend prediction and the corresponding financial question answering. Currently, machine learning and deep learning algorithms (ML&DL) have been widely applied for stock trend predictions, leading to significant progress. However, these methods fail to provide reasons for predictions, lacking interpretability and reasoning processes. Also, they can not integrate textual information such as financial news or reports. Meanwhile, large language models (LLMs) have remarkable textual understanding and generation ability. But due to the scarcity of financial training datasets and limited integration with real-time knowledge, LLMs still suffer from hallucinations and are unable to keep up with the latest information. To tackle these challenges, we first release AlphaFin datasets, combining traditional research datasets, real-time financial data, and handwritten chain-of-thought (CoT) data. It has a positive impact on training LLMs for completing financial analysis. We then use AlphaFin datasets to benchmark a state-of-the-art method, called Stock-Chain, for effectively tackling the financial analysis task, which integrates retrieval-augmented generation (RAG) techniques. Extensive experiments are conducted to demonstrate the effectiveness of our framework on financial analysis.
CO3: Low-resource Contrastive Co-training for Generative Conversational Query Rewrite
Mar 18, 2024Generative query rewrite generates reconstructed query rewrites using the conversation history while rely heavily on gold rewrite pairs that are expensive to obtain. Recently, few-shot learning is gaining increasing popularity for this task, whereas these methods are sensitive to the inherent noise due to limited data size. Besides, both attempts face performance degradation when there exists language style shift between training and testing cases. To this end, we study low-resource generative conversational query rewrite that is robust to both noise and language style shift. The core idea is to utilize massive unlabeled data to make further improvements via a contrastive co-training paradigm. Specifically, we co-train two dual models (namely Rewriter and Simplifier) such that each of them provides extra guidance through pseudo-labeling for enhancing the other in an iterative manner. We also leverage contrastive learning with data augmentation, which enables our model pay more attention on the truly valuable information than the noise. Extensive experiments demonstrate the superiority of our model under both few-shot and zero-shot scenarios. We also verify the better generalization ability of our model when encountering language style shift.
AACP: Aesthetics assessment of children's paintings based on self-supervised learning
Mar 12, 2024
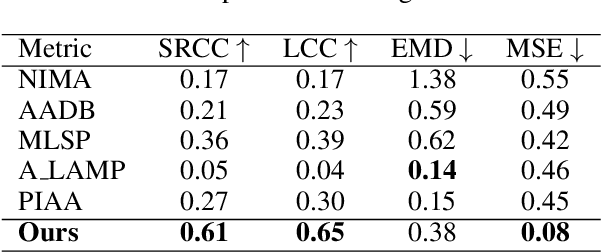
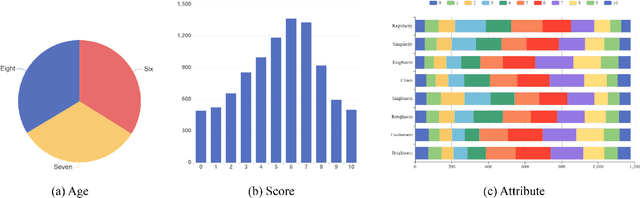
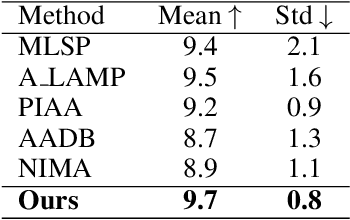
The Aesthetics Assessment of Children's Paintings (AACP) is an important branch of the image aesthetics assessment (IAA), playing a significant role in children's education. This task presents unique challenges, such as limited available data and the requirement for evaluation metrics from multiple perspectives. However, previous approaches have relied on training large datasets and subsequently providing an aesthetics score to the image, which is not applicable to AACP. To solve this problem, we construct an aesthetics assessment dataset of children's paintings and a model based on self-supervised learning. 1) We build a novel dataset composed of two parts: the first part contains more than 20k unlabeled images of children's paintings; the second part contains 1.2k images of children's paintings, and each image contains eight attributes labeled by multiple design experts. 2) We design a pipeline that includes a feature extraction module, perception modules and a disentangled evaluation module. 3) We conduct both qualitative and quantitative experiments to compare our model's performance with five other methods using the AACP dataset. Our experiments reveal that our method can accurately capture aesthetic features and achieve state-of-the-art performance.