 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile and Risk-Sensitive Cardiac Diagnosis via Graph-Based ECG Signal Representation
Nov 11, 2025Despite the rapid advancements of electrocardiogram (ECG) signal diagnosis and analysis methods through deep learning, two major hurdles still limit their clinical adoption: the lack of versatility in processing ECG signals with diverse configurations, and the inadequate detection of risk signals due to sample imbalances. Addressing these challenges, we introduce VersAtile and Risk-Sensitive cardiac diagnosis (VARS), an innovative approach that employs a graph-based representation to uniformly model heterogeneous ECG signals. VARS stands out by transforming ECG signals into versatile graph structures that capture critical diagnostic features, irrespective of signal diversity in the lead count, sampling frequency, and duration. This graph-centric formulation also enhances diagnostic sensitivity, enabling precise localization and identification of abnormal ECG patterns that often elude standard analysis methods. To facilitate representation transformation, our approach integrates denoising reconstruction with contrastive learning to preserve raw ECG information while highlighting pathognomonic patterns. We rigorously evaluate the efficacy of VARS on three distinct ECG datasets, encompassing a range of structural variations. The results demonstrate that VARS not only consistently surpasses existing state-of-the-art models across all these datasets but also exhibits substantial improvement in identifying risk signals. Additionally, VARS offers interpretability by pinpointing the exact waveforms that lead to specific model outputs, thereby assisting clinicians in making informed decisions. These findings suggest that our VARS will likely emerge as an invaluable tool for comprehensive cardiac health assessment.
Summarize-Exemplify-Reflect: Data-driven Insight Distillation Empowers LLMs for Few-shot Tabular Classification
Aug 29, 2025Recent studies show the promise of large language models (LLMs) for few-shot tabular classification but highlight challenges due to the variability in structured data. To address this, we propose distilling data into actionable insights to enable robust and effective classification by LLMs. Drawing inspiration from human learning processes, we introduce InsightTab, an insight distillation framework guided by principles of divide-and-conquer, easy-first, and reflective learning. Our approach integrates rule summarization, strategic exemplification, and insight reflection through deep collaboration between LLMs and data modeling techniques. The obtained insights enable LLMs to better align their general knowledge and capabilities with the particular requirements of specific tabular tasks. We extensively evaluate InsightTab on nine datasets. The results demonstrate consistent improvement over state-of-the-art methods. Ablation studies further validate the principle-guided distillation process, while analyses emphasize InsightTab's effectiveness in leveraging labeled data and managing bias.
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
Large language models could be rote learners
Apr 15, 2025
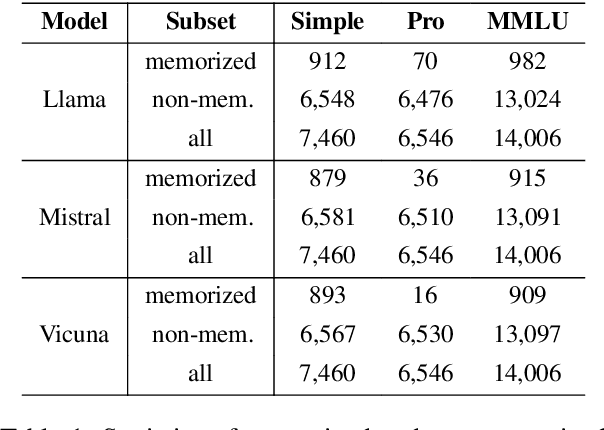
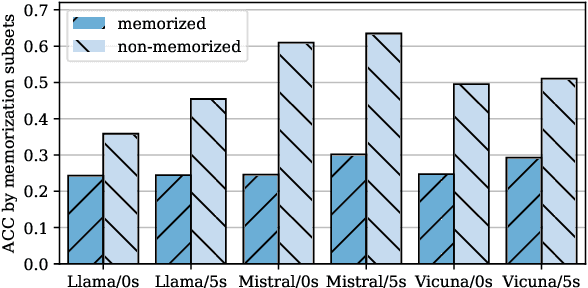

Multiple-choice question (MCQ) benchmarks are widely used for evaluating Large Language Models (LLMs), yet their reliability is undermined by benchmark contamination. In this study, we reframe contamination as an inherent aspect of learning and seek to disentangle genuine capability acquisition from superficial memorization in LLM evaluation. First, by analyzing model performance under different memorization conditions, we uncover a counterintuitive trend: LLMs perform worse on memorized MCQs than on non-memorized ones, indicating the coexistence of two distinct learning phenomena, i.e., rote memorization and genuine capability learning. To disentangle them, we propose TrinEval, a novel evaluation framework that reformulates MCQs into an alternative trinity format, reducing memorization while preserving knowledge assessment. Experiments validate TrinEval's effectiveness in reformulation, and its evaluation reveals that common LLMs may memorize by rote 20.5% of knowledge points (in MMLU on average).
Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons
Feb 05, 2025The rapid advancement of large language models (LLMs) has opened new possibilities for their adoption as evaluative judges. This paper introduces Themis, a fine-tuned LLM judge that delivers sophisticated context-aware evaluations. We provide a comprehensive overview of the development pipeline for Themis, highlighting its scenario-dependent evaluation prompts and two novel methods for controlled instruction generation. These designs enable Themis to effectively distill evaluative skills from teacher models, while retaining flexibility for continuous development. We introduce two human-labeled benchmarks for meta-evaluation, demonstrating that Themis can achieve high alignment with human preferences in an economical manner. Additionally, we explore insights into the LLM-as-a-judge paradigm, revealing nuances in performance and the varied effects of reference answers. Notably, we observe that pure knowledge distillation from strong LLMs, though common, does not guarantee performance improvement through scaling. We propose a mitigation strategy based on instruction-following difficulty. Furthermore, we provide practical guidelines covering data balancing, prompt customization, multi-objective training, and metric aggregation. We aim for our method and findings, along with the fine-tuning data, benchmarks, and model checkpoints, to support future research and development in this area.
LLMs Can Simulate Standardized Patients via Agent Coevolution
Dec 16, 2024Training medical personnel using standardized patients (SPs) remains a complex challenge, requiring extensive domain expertise and role-specific practice. Most research on Large Language Model (LLM)-based simulated patients focuses on improving data retrieval accuracy or adjusting prompts through human feedback. However, this focus has overlooked the critical need for patient agents to learn a standardized presentation pattern that transforms data into human-like patient responses through unsupervised simulations. To address this gap, we propose EvoPatient, a novel simulated patient framework in which a patient agent and doctor agents simulate the diagnostic process through multi-turn dialogues, simultaneously gathering experience to improve the quality of both questions and answers, ultimately enabling human doctor training. Extensive experiments on various cases demonstrate that, by providing only overall SP requirements, our framework improves over existing reasoning methods by more than 10% in requirement alignment and better human preference, while achieving an optimal balance of resource consumption after evolving over 200 cases for 10 hours, with excellent generalizability. The code will be available at https://github.com/ZJUMAI/EvoPatient.
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
May 30, 2024
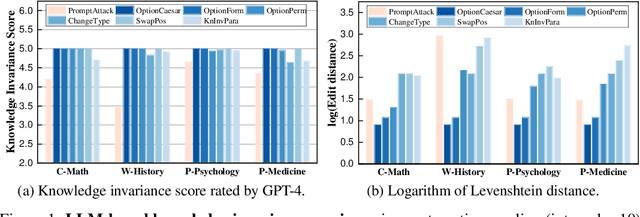

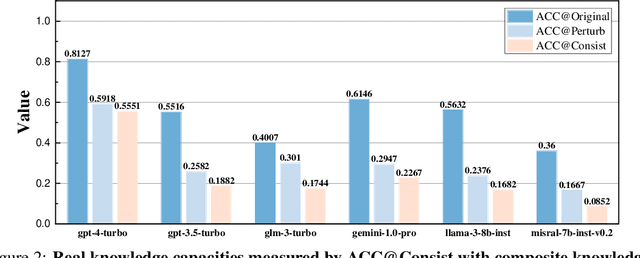
Expert-designed close-ended benchmarks serve as vital tools in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through knowledge-invariant perturbations. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of transition analyses that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six state-of-the-art LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 21% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, potentially being resolved through rote memorization and leading to inflated performance. We also find that the detailed transition analyses by PertEval could illuminate weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Given these insights, we posit that PertEval can act as an essential tool that, when applied alongside any close-ended benchmark, unveils the true knowledge capacity of LLMs, marking a significant step toward more trustworthy LLM evaluation.
CO3: Low-resource Contrastive Co-training for Generative Conversational Query Rewrite
Mar 18, 2024Generative query rewrite generates reconstructed query rewrites using the conversation history while rely heavily on gold rewrite pairs that are expensive to obtain. Recently, few-shot learning is gaining increasing popularity for this task, whereas these methods are sensitive to the inherent noise due to limited data size. Besides, both attempts face performance degradation when there exists language style shift between training and testing cases. To this end, we study low-resource generative conversational query rewrite that is robust to both noise and language style shift. The core idea is to utilize massive unlabeled data to make further improvements via a contrastive co-training paradigm. Specifically, we co-train two dual models (namely Rewriter and Simplifier) such that each of them provides extra guidance through pseudo-labeling for enhancing the other in an iterative manner. We also leverage contrastive learning with data augmentation, which enables our model pay more attention on the truly valuable information than the noise. Extensive experiments demonstrate the superiority of our model under both few-shot and zero-shot scenarios. We also verify the better generalization ability of our model when encountering language style shift.
Arithmetic Feature Interaction Is Necessary for Deep Tabular Learning
Feb 04, 2024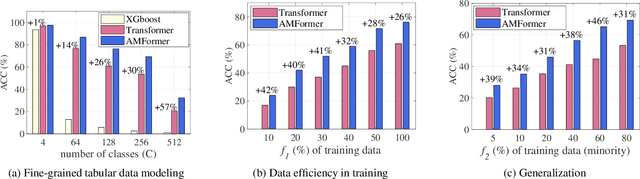

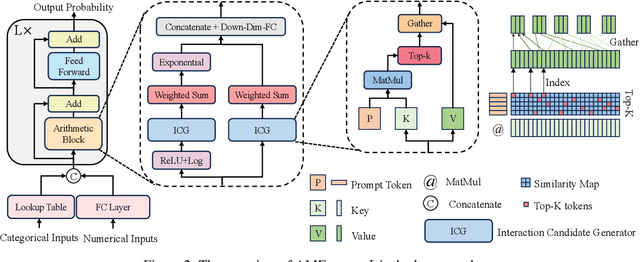

Until recently, the question of the effective inductive bias of deep models on tabular data has remained unanswered. This paper investigates the hypothesis that arithmetic feature interaction is necessary for deep tabular learning. To test this point, we create a synthetic tabular dataset with a mild feature interaction assumption and examine a modified transformer architecture enabling arithmetical feature interactions, referred to as AMFormer. Results show that AMFormer outperforms strong counterparts in fine-grained tabular data modeling, data efficiency in training, and generalization. This is attributed to its parallel additive and multiplicative attention operators and prompt-based optimization, which facilitate the separation of tabular samples in an extended space with arithmetically-engineered features. Our extensive experiments on real-world data also validate the consistent effectiveness, efficiency, and rationale of AMFormer, suggesting it has established a strong inductive bias for deep learning on tabular data. Code is available at https://github.com/aigc-apps/AMFormer.
Robust Image Ordinal Regression with Controllable Image Generation
May 10, 2023



Image ordinal regression has been mainly studied along the line of exploiting the order of categories. However, the issues of class imbalance and category overlap that are very common in ordinal regression were largely overlooked. As a result, the performance on minority categories is often unsatisfactory. In this paper, we propose a novel framework called CIG based on controllable image generation to directly tackle these two issues. Our main idea is to generate extra training samples with specific labels near category boundaries, and the sample generation is biased toward the less-represented categories. To achieve controllable image generation, we seek to separate structural and categorical information of images based on structural similarity, categorical similarity, and reconstruction constraints. We evaluate the effectiveness of our new CIG approach in three different image ordinal regression scenarios. The results demonstrate that CIG can be flexibly integrated with off-the-shelf image encoders or ordinal regression models to achieve improvement, and further, the improvement is more significant for minority categories.