 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarize-Exemplify-Reflect: Data-driven Insight Distillation Empowers LLMs for Few-shot Tabular Classification
Aug 29, 2025Recent studies show the promise of large language models (LLMs) for few-shot tabular classification but highlight challenges due to the variability in structured data. To address this, we propose distilling data into actionable insights to enable robust and effective classification by LLMs. Drawing inspiration from human learning processes, we introduce InsightTab, an insight distillation framework guided by principles of divide-and-conquer, easy-first, and reflective learning. Our approach integrates rule summarization, strategic exemplification, and insight reflection through deep collaboration between LLMs and data modeling techniques. The obtained insights enable LLMs to better align their general knowledge and capabilities with the particular requirements of specific tabular tasks. We extensively evaluate InsightTab on nine datasets. The results demonstrate consistent improvement over state-of-the-art methods. Ablation studies further validate the principle-guided distillation process, while analyses emphasize InsightTab's effectiveness in leveraging labeled data and managing bias.
RAVENEA: A Benchmark for Multimodal Retrieval-Augmented Visual Culture Understanding
May 20, 2025As vision-language models (VLMs) become increasingly integrated into daily life, the need for accurate visual culture understanding is becoming critical. Yet, these models frequently fall short in interpreting cultural nuances effectively. Prior work has demonstrated the effectiveness of retrieval-augmented generation (RAG) in enhancing cultural understanding in text-only settings, while its application in multimodal scenarios remains underexplored. To bridge this gap, we introduce RAVENEA (Retrieval-Augmented Visual culturE uNdErstAnding), a new benchmark designed to advance visual culture understanding through retrieval, focusing on two tasks: culture-focused visual question answering (cVQA) and culture-informed image captioning (cIC). RAVENEA extends existing datasets by integrating over 10,000 Wikipedia documents curated and ranked by human annotators. With RAVENEA, we train and evaluate seven multimodal retrievers for each image query, and measure the downstream impact of retrieval-augmented inputs across fourteen state-of-the-art VLMs. Our results show that lightweight VLMs, when augmented with culture-aware retrieval, outperform their non-augmented counterparts (by at least 3.2% absolute on cVQA and 6.2% absolute on cIC). This highlights the value of retrieval-augmented methods and culturally inclusive benchmarks for multimodal understanding.
Query Understanding in LLM-based Conversational Information Seeking
Apr 08, 2025Query understanding in Conversational Information Seeking (CIS) involves accurately interpreting user intent through context-aware interactions. This includes resolving ambiguities, refining queries, and adapting to evolving information needs. Large Language Models (LLMs) enhance this process by interpreting nuanced language and adapting dynamically, improving the relevance and precision of search results in real-time. In this tutorial, we explore advanced techniques to enhance query understanding in LLM-based CIS systems. We delve into LLM-driven methods for developing robust evaluation metrics to assess query understanding quality in multi-turn interactions, strategies for building more interactive systems, and applications like proactive query management and query reformulation. We also discuss key challenges in integrating LLMs for query understanding in conversational search systems and outline future research directions. Our goal is to deepen the audience's understanding of LLM-based conversational query understanding and inspire discussions to drive ongoing advancements in this field.
Revisiting the Othello World Model Hypothesis
Mar 06, 2025Li et al. (2023) used the Othello board game as a test case for the ability of GPT-2 to induce world models, and were followed up by Nanda et al. (2023b). We briefly discuss the original experiments, expanding them to include more language models with more comprehensive probing. Specifically, we analyze sequences of Othello board states and train the model to predict the next move based on previous moves. We evaluate seven language models (GPT-2, T5, Bart, Flan-T5, Mistral, LLaMA-2, and Qwen2.5) on the Othello task and conclude that these models not only learn to play Othello, but also induce the Othello board layout. We find that all models achieve up to 99% accuracy in unsupervised grounding and exhibit high similarity in the board features they learned. This provides considerably stronger evidence for the Othello World Model Hypothesis than previous works.
Multi-Turn Multi-Modal Question Clarification for Enhanced Conversational Understanding
Feb 17, 2025



Conversational query clarification enables users to refine their search queries through interactive dialogue, improving search effectiveness. Traditional approaches rely on text-based clarifying questions, which often fail to capture complex user preferences, particularly those involving visual attributes. While recent work has explored single-turn multi-modal clarification with images alongside text, such methods do not fully support the progressive nature of user intent refinement over multiple turns. Motivated by this, we introduce the Multi-turn Multi-modal Clarifying Questions (MMCQ) task, which combines text and visual modalities to refine user queries in a multi-turn conversation. To facilitate this task, we create a large-scale dataset named ClariMM comprising over 13k multi-turn interactions and 33k question-answer pairs containing multi-modal clarifying questions. We propose Mario, a retrieval framework that employs a two-phase ranking strategy: initial retrieval with BM25, followed by a multi-modal generative re-ranking model that integrates textual and visual information from conversational history. Our experiments show that multi-turn multi-modal clarification outperforms uni-modal and single-turn approaches, improving MRR by 12.88%. The gains are most significant in longer interactions, demonstrating the value of progressive refinement for complex queries.
Intelligent Reflecting Surfaces Aided Wireless Network: Deployment Architectures and Solutions
Jan 15, 2025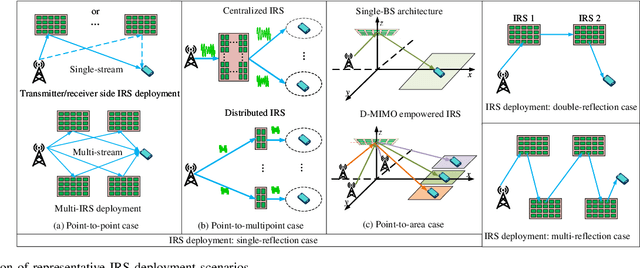
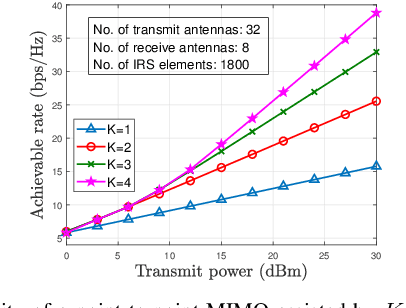
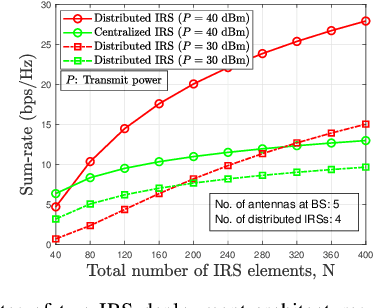
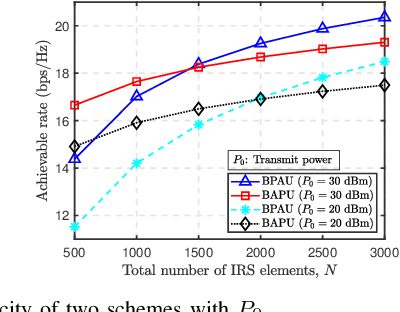
Intelligent reflecting surfaces (IRSs) have emerged as a transformative technology for wireless networks by improving coverage, capacity, and energy efficiency through intelligent manipulation of wireless propagation environments. This paper provides a comprehensive study on the deployment and coordination of IRSs for wireless networks. By addressing both single- and multi-reflection IRS architectures, we examine their deployment strategies across diverse scenarios, including point-to-point, point-to-multipoint, and point-to-area setups. For the single-reflection case, we highlight the trade-offs between passive and active IRS architectures in terms of beamforming gain, coverage extension, and spatial multiplexing. For the multi-reflection case, we discuss practical strategies to optimize IRS deployment and element allocation, balancing cooperative beamforming gains and path loss. The paper further discusses practical challenges in IRS implementation, including environmental conditions, system compatibility, and hardware limitations. Numerical results and field tests validate the effectiveness of IRS-aided wireless networks and demonstrate their capacity and coverage improvements. Lastly, promising research directions, including movable IRSs, near-field deployments, and network-level optimization, are outlined to guide future investigations.
AGENT-CQ: Automatic Generation and Evaluation of Clarifying Questions for Conversational Search with LLMs
Oct 25, 2024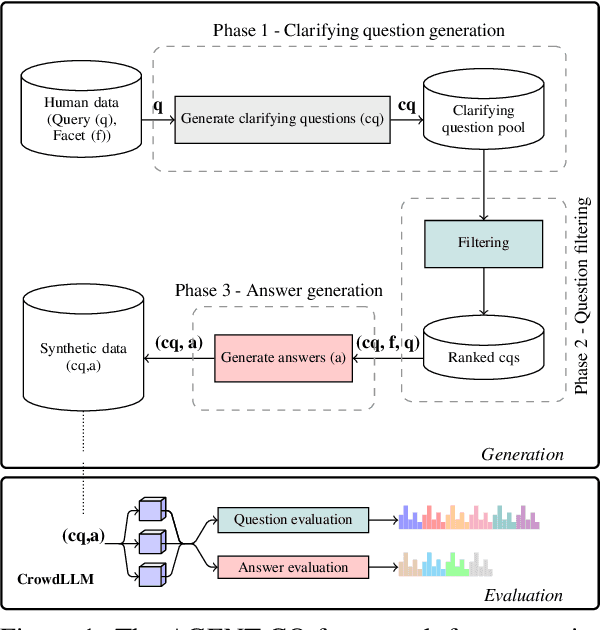



Generating diverse and effective clarifying questions is crucial for improving query understanding and retrieval performance in open-domain conversational search (CS) systems. We propose AGENT-CQ (Automatic GENeration, and evaluaTion of Clarifying Questions), an end-to-end LLM-based framework addressing the challenges of scalability and adaptability faced by existing methods that rely on manual curation or template-based approaches. AGENT-CQ consists of two stages: a generation stage employing LLM prompting strategies to generate clarifying questions, and an evaluation stage (CrowdLLM) that simulates human crowdsourcing judgments using multiple LLM instances to assess generated questions and answers based on comprehensive quality metrics. Extensive experiments on the ClariQ dataset demonstrate CrowdLLM's effectiveness in evaluating question and answer quality. Human evaluation and CrowdLLM show that the AGENT-CQ - generation stage, consistently outperforms baselines in various aspects of question and answer quality. In retrieval-based evaluation, LLM-generated questions significantly enhance retrieval effectiveness for both BM25 and cross-encoder models compared to human-generated questions.
Unlocking Markets: A Multilingual Benchmark to Cross-Market Question Answering
Sep 24, 2024



Users post numerous product-related questions on e-commerce platforms, affecting their purchase decisions. Product-related question answering (PQA) entails utilizing product-related resources to provide precise responses to users. We propose a novel task of Multilingual Cross-market Product-based Question Answering (MCPQA) and define the task as providing answers to product-related questions in a main marketplace by utilizing information from another resource-rich auxiliary marketplace in a multilingual context. We introduce a large-scale dataset comprising over 7 million questions from 17 marketplaces across 11 languages. We then perform automatic translation on the Electronics category of our dataset, naming it as McMarket. We focus on two subtasks: review-based answer generation and product-related question ranking. For each subtask, we label a subset of McMarket using an LLM and further evaluate the quality of the annotations via human assessment. We then conduct experiments to benchmark our dataset, using models ranging from traditional lexical models to LLMs in both single-market and cross-market scenarios across McMarket and the corresponding LLM subset. Results show that incorporating cross-market information significantly enhances performance in both tasks.
Rotatable Block-Controlled RIS: Bridging the Performance Gap to Element-Controlled Systems
Aug 22, 2024


The passive reconfigurable intelligent surface (RIS) requires numerous elements to achieve adequate array gain, which linearly increases power consumption (PC) with the number of reflection phases. To address this, this letter introduces a rotatable block-controlled RIS (BC-RIS) that preserves spectral efficiency (SE) while reducing power costs. Unlike the element-controlled RIS (EC-RIS), which necessitates independent phase control for each element, the BC-RIS uses a single phase control circuit for each block, substantially lowering power requirements. In the maximum ratio transmission, by customizing specular reflection channels through the rotation of blocks and coherently superimposing signals with optimized reflection phase of blocks, the BC-RIS achieves the same averaged SE as the EC-RIS. To counteract the added power demands from rotation, influenced by block size, we have developed a segmentation scheme to minimize overall PC. Furthermore, constraints for rotation power-related parameters have been established to enhance the energy efficiency of the BC-RIS compared to the EC-RIS. Numerical results confirm that this approach significantly improves energy efficiency while maintaining performance.
A Comparative Analysis of Faithfulness Metrics and Humans in Citation Evaluation
Aug 22, 2024



Large language models (LLMs) often generate content with unsupported or unverifiable content, known as "hallucinations." To address this, retrieval-augmented LLMs are employed to include citations in their content, grounding the content in verifiable sources. Despite such developments, manually assessing how well a citation supports the associated statement remains a major challenge. Previous studies tackle this challenge by leveraging faithfulness metrics to estimate citation support automatically. However, they limit this citation support estimation to a binary classification scenario, neglecting fine-grained citation support in practical scenarios. To investigate the effectiveness of faithfulness metrics in fine-grained scenarios, we propose a comparative evaluation framework that assesses the metric effectiveness in distinguishing citations between three-category support levels: full, partial, and no support. Our framework employs correlation analysis, classification evaluation, and retrieval evaluation to measure the alignment between metric scores and human judgments comprehensively. Our results indicate no single metric consistently excels across all evaluations, highlighting the complexity of accurately evaluating fine-grained support levels. Particularly, we find that the best-performing metrics struggle to distinguish partial support from full or no support. Based on these findings, we provide practical recommendations for developing more effective metrics.