 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiwu-PyTorch-Plugin: Bridging Deep Learning and Photonic Quantum Computing for Energy-Based Models and Active Sample Selection
Feb 22, 2026This paper introduces the Kaiwu-PyTorch-Plugin (KPP) to bridge Deep Learning and Photonic Quantum Computing across multiple dimensions. KPP integrates the Coherent Ising Machine into the PyTorch ecosystem, addressing classical inefficiencies in Energy-Based Models. The framework facilitates quantum integration in three key aspects: accelerating Boltzmann sampling, optimizing training data via Active Sampling, and constructing hybrid architectures like QBM-VAE and Q-Diffusion. Empirical results on single-cell and OpenWebText datasets demonstrate KPPs ability to achieve SOTA performance, validating a comprehensive quantum-classical paradigm.
AgentNoiseBench: Benchmarking Robustness of Tool-Using LLM Agents Under Noisy Condition
Feb 11, 2026Recent advances in large language models have enabled LLM-based agents to achieve strong performance on a variety of benchmarks. However, their performance in real-world deployments often that observed on benchmark settings, especially in complex and imperfect environments. This discrepancy largely arises because prevailing training and evaluation paradigms are typically built on idealized assumptions, overlooking the inherent stochasticity and noise present in real-world interactions. To bridge this gap, we introduce AgentNoiseBench, a framework for systematically evaluating the robustness of agentic models under noisy environments. We first conduct an in-depth analysis of biases and uncertainties in real-world scenarios and categorize environmental noise into two primary types: user-noise and tool-noise. Building on this analysis, we develop an automated pipeline that injects controllable noise into existing agent-centric benchmarks while preserving task solvability. Leveraging this pipeline, we perform extensive evaluations across a wide range of models with diverse architectures and parameter scales. Our results reveal consistent performance variations under different noise conditions, highlighting the sensitivity of current agentic models to realistic environmental perturbations.
Nipping the Drift in the Bud: Retrospective Rectification for Robust Vision-Language Navigation
Feb 06, 2026Vision-Language Navigation (VLN) requires embodied agents to interpret natural language instructions and navigate through complex continuous 3D environments. However, the dominant imitation learning paradigm suffers from exposure bias, where minor deviations during inference lead to compounding errors. While DAgger-style approaches attempt to mitigate this by correcting error states, we identify a critical limitation: Instruction-State Misalignment. Forcing an agent to learn recovery actions from off-track states often creates supervision signals that semantically conflict with the original instruction. In response to these challenges, we introduce BudVLN, an online framework that learns from on-policy rollouts by constructing supervision to match the current state distribution. BudVLN performs retrospective rectification via counterfactual re-anchoring and decision-conditioned supervision synthesis, using a geodesic oracle to synthesize corrective trajectories that originate from valid historical states, ensuring semantic consistency. Experiments on the standard R2R-CE and RxR-CE benchmarks demonstrate that BudVLN consistently mitigates distribution shift and achieves state-of-the-art performance in both Success Rate and SPL.
Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
May 16, 2025Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think'' paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
Statistical QoS Provision in Business-Centric Networks
Aug 28, 2024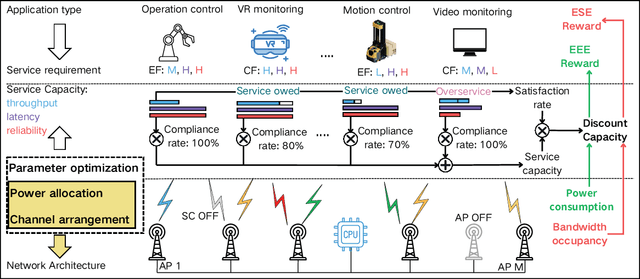
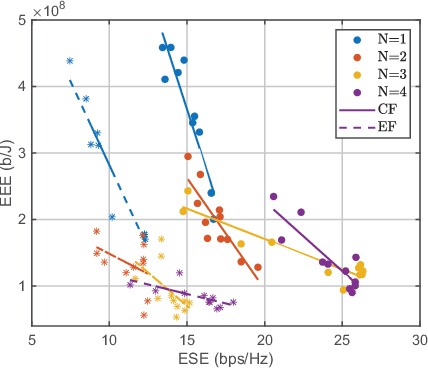
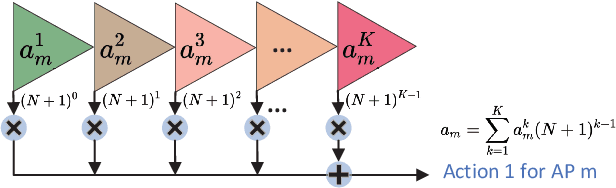
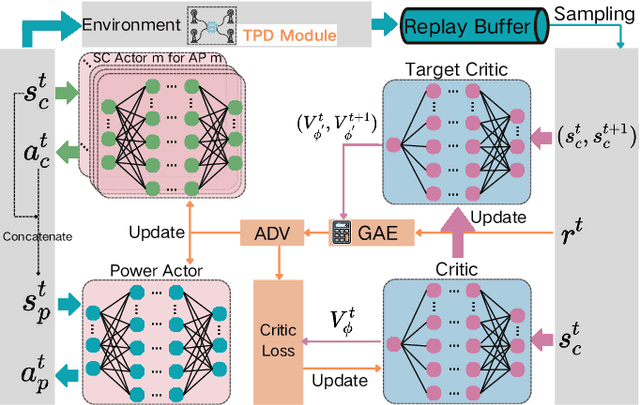
More refined resource management and Quality of Service (QoS) provisioning is a critical goal of wireless communication technologies. In this paper, we propose a novel Business-Centric Network (BCN) aimed at enabling scalable QoS provisioning, based on a cross-layer framework that captures the relationship between application, transport parameters, and channels. We investigate both continuous flow and event-driven flow models, presenting key QoS metrics such as throughput, delay, and reliability. By jointly considering power and bandwidth allocation, transmission parameters, and AP network topology across layers, we optimize weighted resource efficiency with statistical QoS provisioning. To address the coupling among parameters, we propose a novel deep reinforcement learning (DRL) framework, which is Collaborative Optimization among Heterogeneous Actors with Experience Sharing (COHA-ES). Power and sub-channel (SC) Actors representing multiple APs are jointly optimized under the unified guidance of a common critic. Additionally, we introduce a novel multithreaded experience-sharing mechanism to accelerate training and enhance rewards. Extensive comparative experiments validate the effectiveness of our DRL framework in terms of convergence and efficiency. Moreover, comparative analyses demonstrate the comprehensive advantages of the BCN structure in enhancing both spectral and energy efficiency.
MSSP : A Versatile Multi-Scenario Adaptable Intelligent Robot Simulation Platform Based on LIDAR-Inertial Fusion
Jul 19, 2024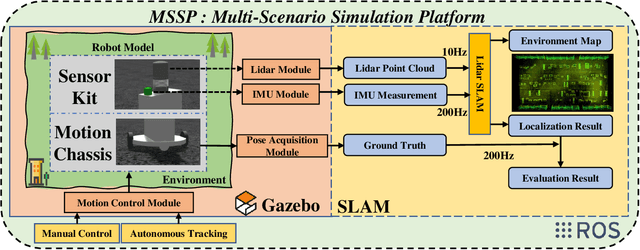
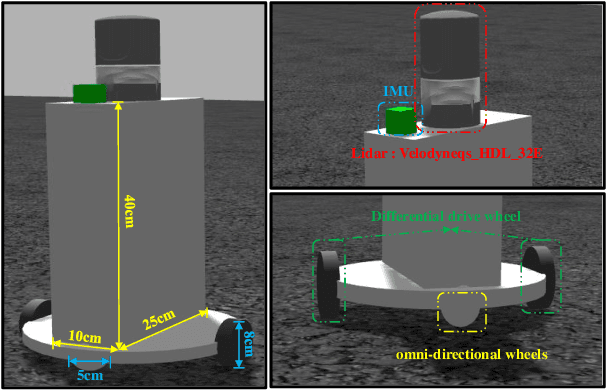
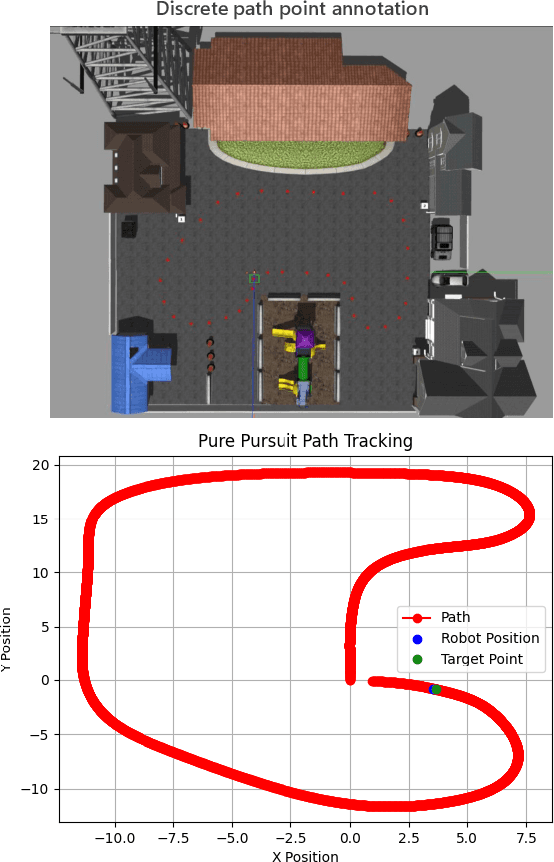

This letter presents a multi-scenario adaptable intelligent robot simulation platform based on LIDAR-inertial fusion, with three main features: (1 The platform includes an versatile robot model that can be freely controlled through manual control or autonomous tracking. This model is equipped with various types of LIDAR and Inertial Measurement Unit (IMU), providing ground truth information with absolute accuracy. (2 The platform provides a collection of simulation environments with diverse characteristic information and supports developers in customizing and modifying environments according to their needs. (3 The platform supports evaluation of localization performance for SLAM frameworks. Ground truth with absolute accuracy eliminates the inherent errors of global positioning sensors present in real experiments, facilitating detailed analysis and evaluation of the algorithms. By utilizing the simulation platform, developers can overcome the limitations of real environments and datasets, enabling fine-grained analysis and evaluation of mainstream SLAM algorithms in various environments. Experiments conducted in different environments and with different LIDARs demonstrate the wide applicability and practicality of our simulation platform. The implementation of the simulation platform is open-sourced on Github.
MolTC: Towards Molecular Relational Modeling In Language Models
Feb 14, 2024



Molecular Relational Learning (MRL), aiming to understand interactions between molecular pairs, plays a pivotal role in advancing biochemical research. Recently, the adoption of large language models (LLMs), known for their vast knowledge repositories and advanced logical inference capabilities, has emerged as a promising way for efficient and effective MRL. Despite their potential, these methods predominantly rely on the textual data, thus not fully harnessing the wealth of structural information inherent in molecular graphs. Moreover, the absence of a unified framework exacerbates the issue of information underutilization, as it hinders the sharing of interaction mechanism learned across diverse datasets. To address these challenges, this work proposes a novel LLM-based multi-modal framework for Molecular inTeraction prediction following Chain-of-Thought (CoT) theory, termed MolTC, which effectively integrate graphical information of two molecules in pair. For achieving a unified MRL, MolTC innovatively develops a dynamic parameter-sharing strategy for cross-dataset information sharing. Moreover, to train MolTC efficiently, we introduce a Multi-hierarchical CoT concept to refine its training paradigm, and conduct a comprehensive Molecular Interactive Instructions dataset for the development of biochemical LLMs involving MRL. Our experiments, conducted across various datasets involving over 4,000,000 molecular pairs, exhibit the superiority of our method over current GNN and LLM-based baselines. Code is available at https://github.com/MangoKiller/MolTC.
VoxelMap++: Mergeable Voxel Mapping Method for Online LiDAR(-inertial) Odometry
Aug 05, 2023



This paper presents VoxelMap++: a voxel mapping method with plane merging which can effectively improve the accuracy and efficiency of LiDAR(-inertial) based simultaneous localization and mapping (SLAM). This map is a collection of voxels that contains one plane feature with 3DOF representation and corresponding covariance estimation. Considering total map will contain a large number of coplanar features (kid planes), these kid planes' 3DOF estimation can be regarded as the measurements with covariance of a larger plane (father plane). Thus, we design a plane merging module based on union-find which can save resources and further improve the accuracy of plane fitting. This module can distinguish the kid planes in different voxels and merge these kid planes to estimate the father plane. After merging, the father plane 3DOF representation will be more accurate than the kids plane and the uncertainty will decrease significantly which can further improve the performance of LiDAR(-inertial) odometry. Experiments on challenging environments such as corridors and forests demonstrate the high accuracy and efficiency of our method compared to other state-of-the-art methods (see our attached video). By the way, our implementation VoxelMap++ is open-sourced on GitHub which is applicable for both non-repetitive scanning LiDARs and traditional scanning LiDAR.
Streaming 360-degree VR Video with Statistical QoS Provisioning in mmWave Networks from Delay and Rate Perspectives
May 13, 2023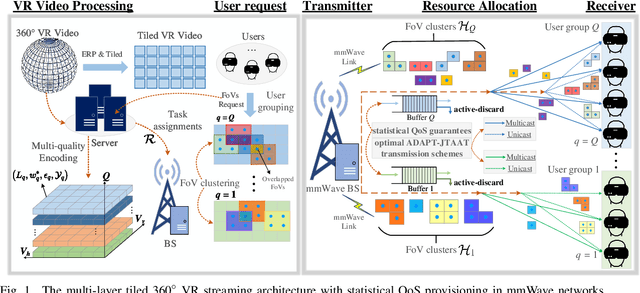
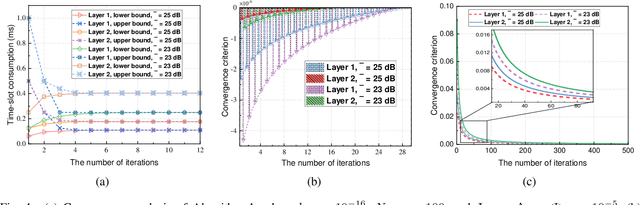
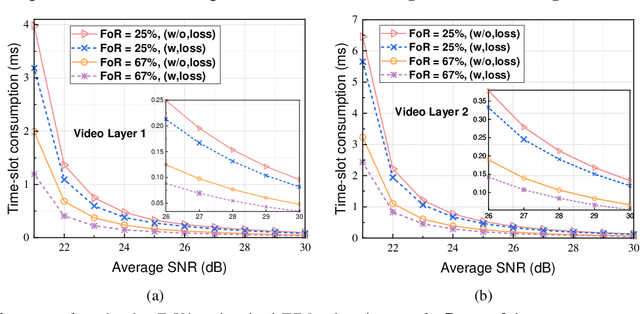
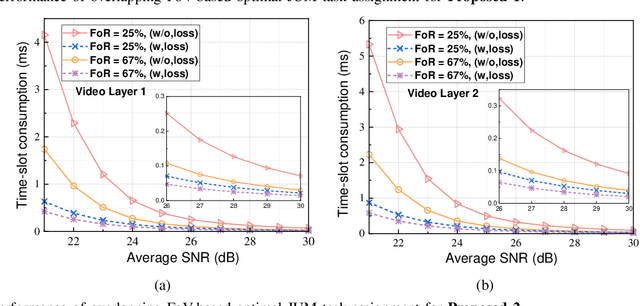
Millimeter-wave(mmWave) technology has emerged as a promising enabler for unleashing the full potential of 360-degree virtual reality (VR). However, the explosive growth of VR services, coupled with the reliability issues of mmWave communications, poses enormous challenges in terms of wireless resource and quality-of-service (QoS) provisioning for mmWave-enabled 360-degree VR. In this paper, we propose an innovative 360-degree VR streaming architecture that addresses three under-exploited issues: overlapping field-of-views (FoVs), statistical QoS provisioning (SQP), and loss-tolerant active data discarding. Specifically, an overlapping FoV-based optimal joint unicast and multicast (JUM) task assignment scheme is designed to implement the non-redundant task assignments, thereby conserving wireless resources remarkably. Furthermore, leveraging stochastic network calculus, we develop a comprehensive SQP theoretical framework that encompasses two SQP schemes from delay and rate perspectives. Additionally, a corresponding optimal adaptive joint time-slot allocation and active-discarding (ADAPT-JTAAT) transmission scheme is proposed to minimize resource consumption while guaranteeing diverse statistical QoS requirements under loss-intolerant and loss-tolerant scenarios from delay and rate perspectives, respectively. Extensive simulations demonstrate the effectiveness of the designed overlapping FoV-based JUM optimal task assignment scheme. Comparisons with six baseline schemes validate that the proposed optimal ADAPTJTAAT transmission scheme can achieve superior SQP performance in resource utilization, flexible rate control, and robust queue behaviors.
SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
Nov 04, 2022HDR(High Dynamic Range) video can reproduce realistic scenes more realistically, with a wider gamut and broader brightness range. HDR video resources are still scarce, and most videos are still stored in SDR (Standard Dynamic Range) format. Therefore, SDRTV-to-HDRTV Conversion (SDR video to HDR video) can significantly enhance the user's video viewing experience. Since the correlation between adjacent video frames is very high, the method utilizing the information of multiple frames can improve the quality of the converted HDRTV. Therefore, we propose a multi-frame fusion neural network \textbf{DSLNet} for SDRTV to HDRTV conversion. We first propose a dynamic spatial-temporal feature alignment module \textbf{DMFA}, which can align and fuse multi-frame. Then a novel spatial-temporal feature modulation module \textbf{STFM}, STFM extracts spatial-temporal information of adjacent frames for more accurate feature modulation. Finally, we design a quality enhancement module \textbf{LKQE} with large kernels, which can enhance the quality of generated HDR videos. To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods. The experimental results show that our method obtains state-of-the-art performance. The dataset and code will be released.