 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Image Super-resolution with Rich Texture-Aware Codebooks
Oct 26, 2023Blind super-resolution (BSR) methods based on high-resolution (HR) reconstruction codebooks have achieved promising results in recent years. However, we find that a codebook based on HR reconstruction may not effectively capture the complex correlations between low-resolution (LR) and HR images. In detail, multiple HR images may produce similar LR versions due to complex blind degradations, causing the HR-dependent only codebooks having limited texture diversity when faced with confusing LR inputs. To alleviate this problem, we propose the Rich Texture-aware Codebook-based Network (RTCNet), which consists of the Degradation-robust Texture Prior Module (DTPM) and the Patch-aware Texture Prior Module (PTPM). DTPM effectively mines the cross-resolution correlation of textures between LR and HR images by exploiting the cross-resolution correspondence of textures. PTPM uses patch-wise semantic pre-training to correct the misperception of texture similarity in the high-level semantic regularization. By taking advantage of this, RTCNet effectively gets rid of the misalignment of confusing textures between HR and LR in the BSR scenarios. Experiments show that RTCNet outperforms state-of-the-art methods on various benchmarks by up to 0.16 ~ 0.46dB.
Ada-DQA: Adaptive Diverse Quality-aware Feature Acquisition for Video Quality Assessment
Aug 01, 2023Video quality assessment (VQA) has attracted growing attention in recent years. While the great expense of annotating large-scale VQA datasets has become the main obstacle for current deep-learning methods. To surmount the constraint of insufficient training data, in this paper, we first consider the complete range of video distribution diversity (\ie content, distortion, motion) and employ diverse pretrained models (\eg architecture, pretext task, pre-training dataset) to benefit quality representation. An Adaptive Diverse Quality-aware feature Acquisition (Ada-DQA) framework is proposed to capture desired quality-related features generated by these frozen pretrained models. By leveraging the Quality-aware Acquisition Module (QAM), the framework is able to extract more essential and relevant features to represent quality. Finally, the learned quality representation is utilized as supplementary supervisory information, along with the supervision of the labeled quality score, to guide the training of a relatively lightweight VQA model in a knowledge distillation manner, which largely reduces the computational cost during inference. Experimental results on three mainstream no-reference VQA benchmarks clearly show the superior performance of Ada-DQA in comparison with current state-of-the-art approaches without using extra training data of VQA.
Capturing Co-existing Distortions in User-Generated Content for No-reference Video Quality Assessment
Jul 31, 2023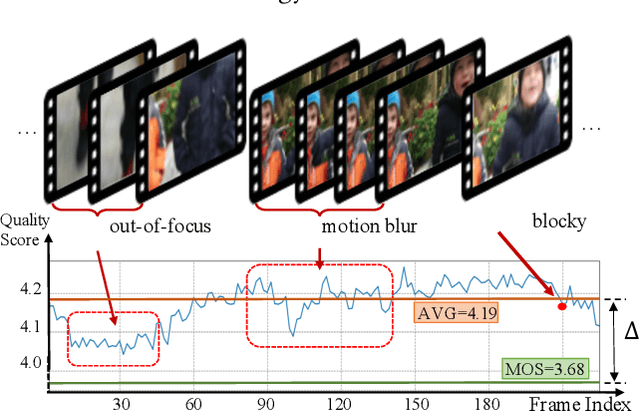
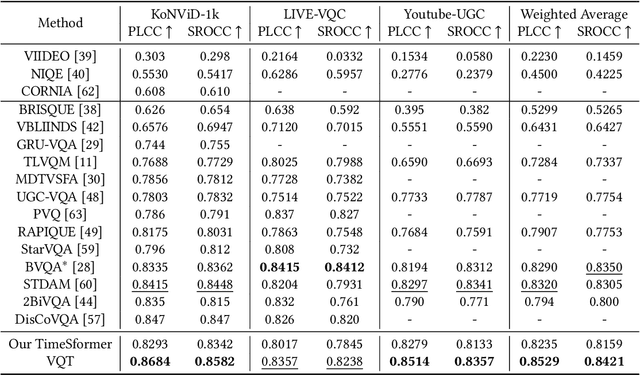
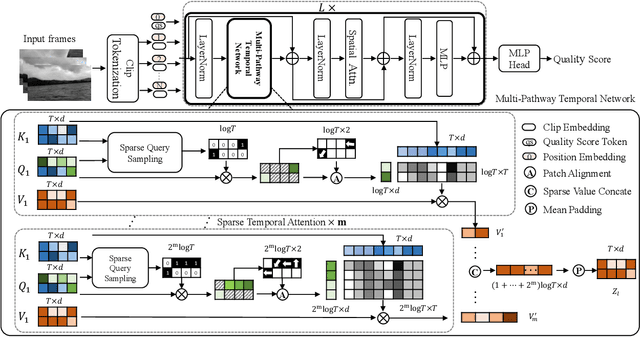
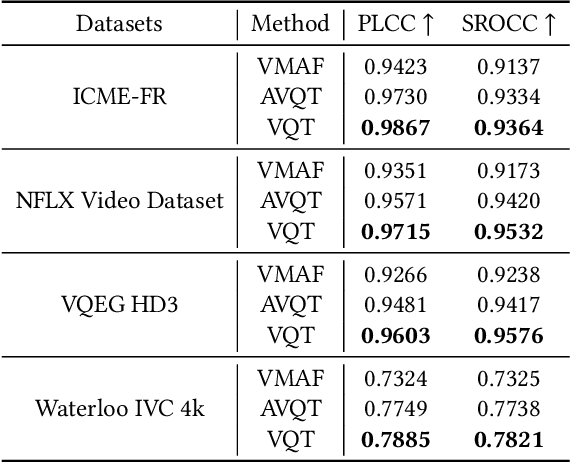
Video Quality Assessment (VQA), which aims to predict the perceptual quality of a video, has attracted raising attention with the rapid development of streaming media technology, such as Facebook, TikTok, Kwai, and so on. Compared with other sequence-based visual tasks (\textit{e.g.,} action recognition), VQA faces two under-estimated challenges unresolved in User Generated Content (UGC) videos. \textit{First}, it is not rare that several frames containing serious distortions (\textit{e.g.,}blocking, blurriness), can determine the perceptual quality of the whole video, while other sequence-based tasks require more frames of equal importance for representations. \textit{Second}, the perceptual quality of a video exhibits a multi-distortion distribution, due to the differences in the duration and probability of occurrence for various distortions. In order to solve the above challenges, we propose \textit{Visual Quality Transformer (VQT)} to extract quality-related sparse features more efficiently. Methodologically, a Sparse Temporal Attention (STA) is proposed to sample keyframes by analyzing the temporal correlation between frames, which reduces the computational complexity from $O(T^2)$ to $O(T \log T)$. Structurally, a Multi-Pathway Temporal Network (MPTN) utilizes multiple STA modules with different degrees of sparsity in parallel, capturing co-existing distortions in a video. Experimentally, VQT demonstrates superior performance than many \textit{state-of-the-art} methods in three public no-reference VQA datasets. Furthermore, VQT shows better performance in four full-reference VQA datasets against widely-adopted industrial algorithms (\textit{i.e.,} VMAF and AVQT).
Reconstructed Convolution Module Based Look-Up Tables for Efficient Image Super-Resolution
Jul 17, 2023Look-up table(LUT)-based methods have shown the great efficacy in single image super-resolution (SR) task. However, previous methods ignore the essential reason of restricted receptive field (RF) size in LUT, which is caused by the interaction of space and channel features in vanilla convolution. They can only increase the RF at the cost of linearly increasing LUT size. To enlarge RF with contained LUT sizes, we propose a novel Reconstructed Convolution(RC) module, which decouples channel-wise and spatial calculation. It can be formulated as $n^2$ 1D LUTs to maintain $n\times n$ receptive field, which is obviously smaller than $n\times n$D LUT formulated before. The LUT generated by our RC module reaches less than 1/10000 storage compared with SR-LUT baseline. The proposed Reconstructed Convolution module based LUT method, termed as RCLUT, can enlarge the RF size by 9 times than the state-of-the-art LUT-based SR method and achieve superior performance on five popular benchmark dataset. Moreover, the efficient and robust RC module can be used as a plugin to improve other LUT-based SR methods. The code is available at https://github.com/liuguandu/RC-LUT.
Towards Robust SDRTV-to-HDRTV via Dual Inverse Degradation Network
Jul 07, 2023



Recently, the transformation of standard dynamic range TV (SDRTV) to high dynamic range TV (HDRTV) is in high demand due to the scarcity of HDRTV content. However, the conversion of SDRTV to HDRTV often amplifies the existing coding artifacts in SDRTV which deteriorate the visual quality of the output. In this study, we propose a dual inverse degradation SDRTV-to-HDRTV network DIDNet to address the issue of coding artifact restoration in converted HDRTV, which has not been previously studied. Specifically, we propose a temporal-spatial feature alignment module and dual modulation convolution to remove coding artifacts and enhance color restoration ability. Furthermore, a wavelet attention module is proposed to improve SDRTV features in the frequency domain. An auxiliary loss is introduced to decouple the learning process for effectively restoring from dual degradation. The proposed method outperforms the current state-of-the-art method in terms of quantitative results, visual quality, and inference times, thus enhancing the performance of the SDRTV-to-HDRTV method in real-world scenarios.
Zoom-VQA: Patches, Frames and Clips Integration for Video Quality Assessment
Apr 13, 2023



Video quality assessment (VQA) aims to simulate the human perception of video quality, which is influenced by factors ranging from low-level color and texture details to high-level semantic content. To effectively model these complicated quality-related factors, in this paper, we decompose video into three levels (\ie, patch level, frame level, and clip level), and propose a novel Zoom-VQA architecture to perceive spatio-temporal features at different levels. It integrates three components: patch attention module, frame pyramid alignment, and clip ensemble strategy, respectively for capturing region-of-interest in the spatial dimension, multi-level information at different feature levels, and distortions distributed over the temporal dimension. Owing to the comprehensive design, Zoom-VQA obtains state-of-the-art results on four VQA benchmarks and achieves 2nd place in the NTIRE 2023 VQA challenge. Notably, Zoom-VQA has outperformed the previous best results on two subsets of LSVQ, achieving 0.8860 (+1.0%) and 0.7985 (+1.9%) of SRCC on the respective subsets. Adequate ablation studies further verify the effectiveness of each component. Codes and models are released in https://github.com/k-zha14/Zoom-VQA.
Quality-aware Pre-trained Models for Blind Image Quality Assessment
Mar 01, 2023



Blind image quality assessment (BIQA) aims to automatically evaluate the perceived quality of a single image, whose performance has been improved by deep learning-based methods in recent years. However, the paucity of labeled data somewhat restrains deep learning-based BIQA methods from unleashing their full potential. In this paper, we propose to solve the problem by a pretext task customized for BIQA in a self-supervised learning manner, which enables learning representations from orders of magnitude more data. To constrain the learning process, we propose a quality-aware contrastive loss based on a simple assumption: the quality of patches from a distorted image should be similar, but vary from patches from the same image with different degradations and patches from different images. Further, we improve the existing degradation process and form a degradation space with the size of roughly $2\times10^7$. After pre-trained on ImageNet using our method, models are more sensitive to image quality and perform significantly better on downstream BIQA tasks. Experimental results show that our method obtains remarkable improvements on popular BIQA datasets.
Global Priors Guided Modulation Network for Joint Super-Resolution and Inverse Tone-Mapping
Aug 14, 2022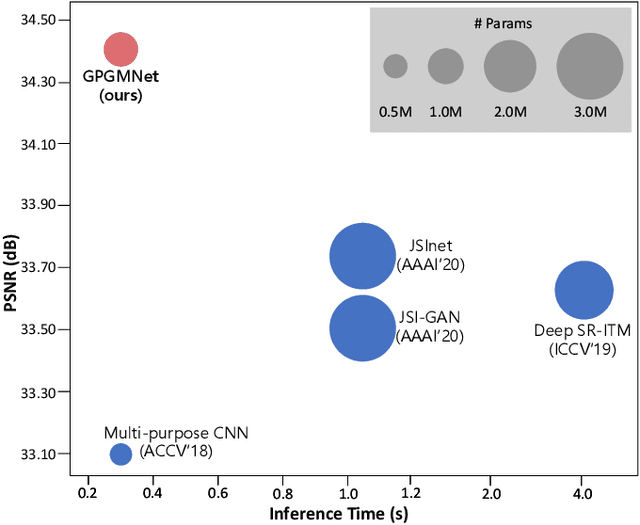
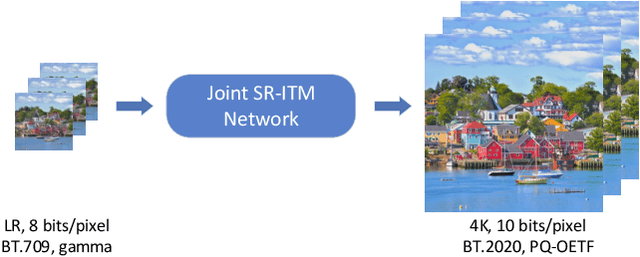
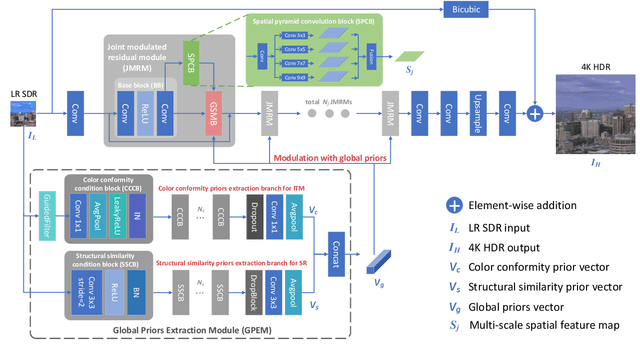
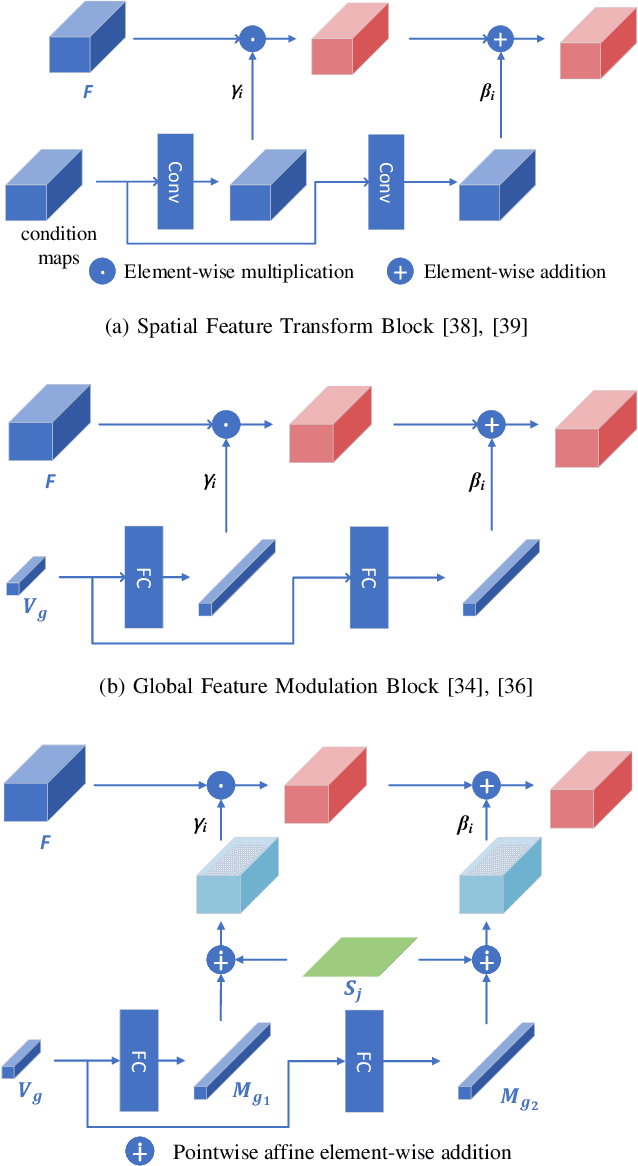
Joint super-resolution and inverse tone-mapping (SR-ITM) aims to enhance the visual quality of videos that have quality deficiencies in resolution and dynamic range. This problem arises when using 4K high dynamic range (HDR) TVs to watch a low-resolution standard dynamic range (LR SDR) video. Previous methods that rely on learning local information typically cannot do well in preserving color conformity and long-range structural similarity, resulting in unnatural color transition and texture artifacts. In order to tackle these challenges, we propose a global priors guided modulation network (GPGMNet) for joint SR-ITM. In particular, we design a global priors extraction module (GPEM) to extract color conformity prior and structural similarity prior that are beneficial for ITM and SR tasks, respectively. To further exploit the global priors and preserve spatial information, we devise multiple global priors guided spatial-wise modulation blocks (GSMBs) with a few parameters for intermediate feature modulation, in which the modulation parameters are generated by the shared global priors and the spatial features map from the spatial pyramid convolution block (SPCB). With these elaborate designs, the GPGMNet can achieve higher visual quality with lower computational complexity. Extensive experiments demonstrate that our proposed GPGMNet is superior to the state-of-the-art methods. Specifically, our proposed model exceeds the state-of-the-art by 0.64 dB in PSNR, with 69$\%$ fewer parameters and 3.1$\times$ speedup. The code will be released soon.
Luminance-Guided Chrominance Image Enhancement for HEVC Intra Coding
Jun 11, 2022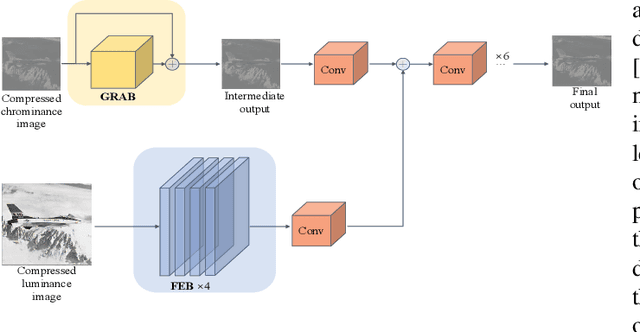

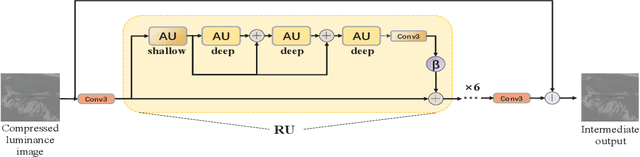
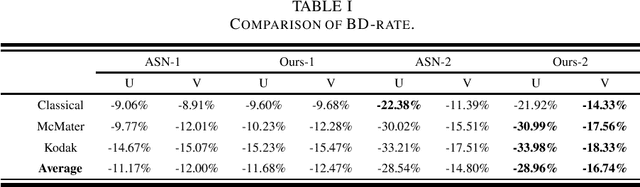
In this paper, we propose a luminance-guided chrominance image enhancement convolutional neural network for HEVC intra coding. Specifically, we firstly develop a gated recursive asymmetric-convolution block to restore each degraded chrominance image, which generates an intermediate output. Then, guided by the luminance image, the quality of this intermediate output is further improved, which finally produces the high-quality chrominance image. When our proposed method is adopted in the compression of color images with HEVC intra coding, it achieves 28.96% and 16.74% BD-rate gains over HEVC for the U and V images, respectively, which accordingly demonstrate its superiority.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022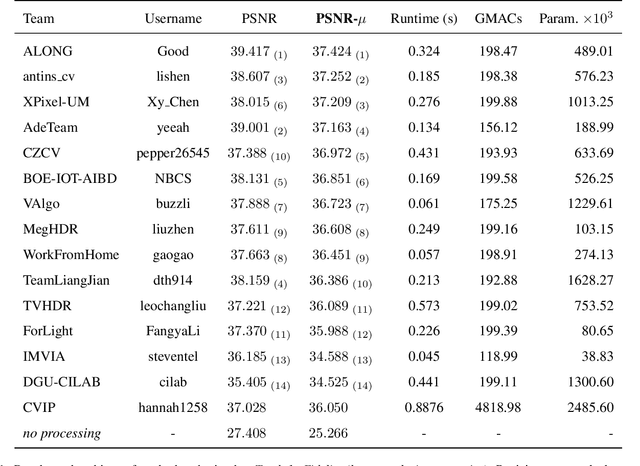
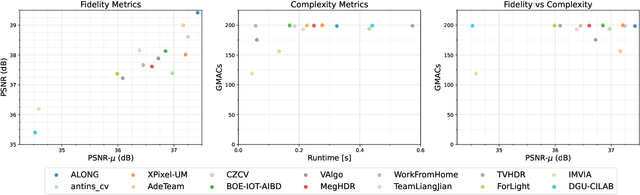
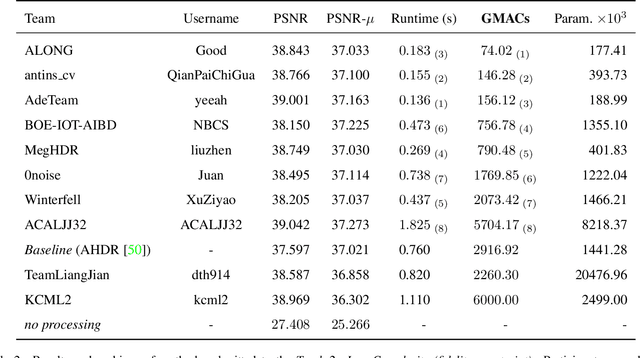
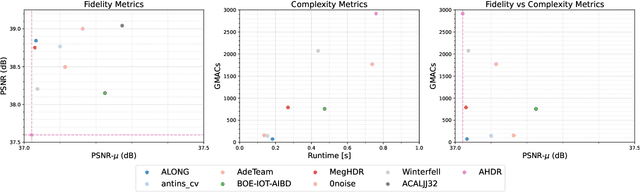
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables