 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory in the LLM Era: Modular Architectures and Strategies in a Unified Framework
Apr 02, 2026Memory emerges as the core module in the large language model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. A number of memory methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework that incorporates all the existing agent memory methods from a high-level perspective. We then extensively compare representative agent memory methods on two well-known benchmarks and examine the effectiveness of all methods, providing a thorough analysis of those methods. As a byproduct of our experimental analysis, we also design a new memory method by exploiting modules in the existing methods, which outperforms the state-of-the-art methods. Finally, based on these findings, we offer promising future research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide valuable new insights for future research.
LLM-Based Test Case Generation in DBMS through Monte Carlo Tree Search
Mar 23, 2026Database Management Systems (DBMSs) are fundamental infrastructure for modern data-driven applications, where thorough testing with high-quality SQL test cases is essential for ensuring system reliability. Traditional approaches such as fuzzing can be effective for specific DBMSs, but adapting them to different proprietary dialects requires substantial manual effort. Large Language Models (LLMs) present promising opportunities for automated SQL test generation, but face critical challenges in industrial environments. First, lightweight models are widely used in organizations due to security and privacy constraints, but they struggle to generate syntactically valid queries for proprietary SQL dialects. Second, LLM-generated queries are often semantically similar and exercise only shallow execution paths, thereby quickly reaching a coverage plateau. To address these challenges, we propose MIST, an LLM-based test case generatIon framework for DBMS through Monte Carlo Tree search. MIST consists of two stages: Feature-Guided Error-Driven Test Case Synthetization, which constructs a hierarchical feature tree and uses error feedback to guide LLM generation, aiming to produce syntactically valid and semantically diverse queries for different DBMS dialects, and Monte Carlo Tree Search-Based Test Case Mutation, which jointly optimizes seed query selection and mutation rule application guided by coverage feedback, aiming at boosting code coverage by exploring deeper execution paths. Experiments on three widely-used DBMSs with four lightweight LLMs show that MIST achieves average improvements of 43.3% in line coverage, 32.3% in function coverage, and 46.4% in branch coverage compared to the baseline approach with the highest line coverage of 69.3% in the Optimizer module.
Breaking the Static Graph: Context-Aware Traversal for Robust Retrieval-Augmented Generation
Feb 02, 2026Recent advances in Retrieval-Augmented Generation (RAG) have shifted from simple vector similarity to structure-aware approaches like HippoRAG, which leverage Knowledge Graphs (KGs) and Personalized PageRank (PPR) to capture multi-hop dependencies. However, these methods suffer from a "Static Graph Fallacy": they rely on fixed transition probabilities determined during indexing. This rigidity ignores the query-dependent nature of edge relevance, causing semantic drift where random walks are diverted into high-degree "hub" nodes before reaching critical downstream evidence. Consequently, models often achieve high partial recall but fail to retrieve the complete evidence chain required for multi-hop queries. To address this, we propose CatRAG, Context-Aware Traversal for robust RAG, a framework that builds on the HippoRAG 2 architecture and transforms the static KG into a query-adaptive navigation structure. We introduce a multi-faceted framework to steer the random walk: (1) Symbolic Anchoring, which injects weak entity constraints to regularize the random walk; (2) Query-Aware Dynamic Edge Weighting, which dynamically modulates graph structure, to prune irrelevant paths while amplifying those aligned with the query's intent; and (3) Key-Fact Passage Weight Enhancement, a cost-efficient bias that structurally anchors the random walk to likely evidence. Experiments across four multi-hop benchmarks demonstrate that CatRAG consistently outperforms state of the art baselines. Our analysis reveals that while standard Recall metrics show modest gains, CatRAG achieves substantial improvements in reasoning completeness, the capacity to recover the entire evidence path without gaps. These results reveal that our approach effectively bridges the gap between retrieving partial context and enabling fully grounded reasoning. Resources are available at https://github.com/kwunhang/CatRAG.
EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora
Jun 26, 2025Graph-based Retrieval-Augmented Generation (Graph-RAG) enhances large language models (LLMs) by structuring retrieval over an external corpus. However, existing approaches typically assume a static corpus, requiring expensive full-graph reconstruction whenever new documents arrive, limiting their scalability in dynamic, evolving environments. To address these limitations, we introduce EraRAG, a novel multi-layered Graph-RAG framework that supports efficient and scalable dynamic updates. Our method leverages hyperplane-based Locality-Sensitive Hashing (LSH) to partition and organize the original corpus into hierarchical graph structures, enabling efficient and localized insertions of new data without disrupting the existing topology. The design eliminates the need for retraining or costly recomputation while preserving high retrieval accuracy and low latency. Experiments on large-scale benchmarks demonstrate that EraRag achieves up to an order of magnitude reduction in update time and token consumption compared to existing Graph-RAG systems, while providing superior accuracy performance. This work offers a practical path forward for RAG systems that must operate over continually growing corpora, bridging the gap between retrieval efficiency and adaptability. Our code and data are available at https://github.com/EverM0re/EraRAG-Official.
Semantic Hierarchical Prompt Tuning for Parameter-Efficient Fine-Tuning
Dec 24, 2024



As the scale of vision models continues to grow, Visual Prompt Tuning (VPT) has emerged as a parameter-efficient transfer learning technique, noted for its superior performance compared to full fine-tuning. However, indiscriminately applying prompts to every layer without considering their inherent correlations, can cause significant disturbances, leading to suboptimal transferability. Additionally, VPT disrupts the original self-attention structure, affecting the aggregation of visual features, and lacks a mechanism for explicitly mining discriminative visual features, which are crucial for classification. To address these issues, we propose a Semantic Hierarchical Prompt (SHIP) fine-tuning strategy. We adaptively construct semantic hierarchies and use semantic-independent and semantic-shared prompts to learn hierarchical representations. We also integrate attribute prompts and a prompt matching loss to enhance feature discrimination and employ decoupled attention for robustness and reduced inference costs. SHIP significantly improves performance, achieving a 4.9% gain in accuracy over VPT with a ViT-B/16 backbone on VTAB-1k tasks. Our code is available at https://github.com/haoweiz23/SHIP.
MPAT: Building Robust Deep Neural Networks against Textual Adversarial Attacks
Feb 29, 2024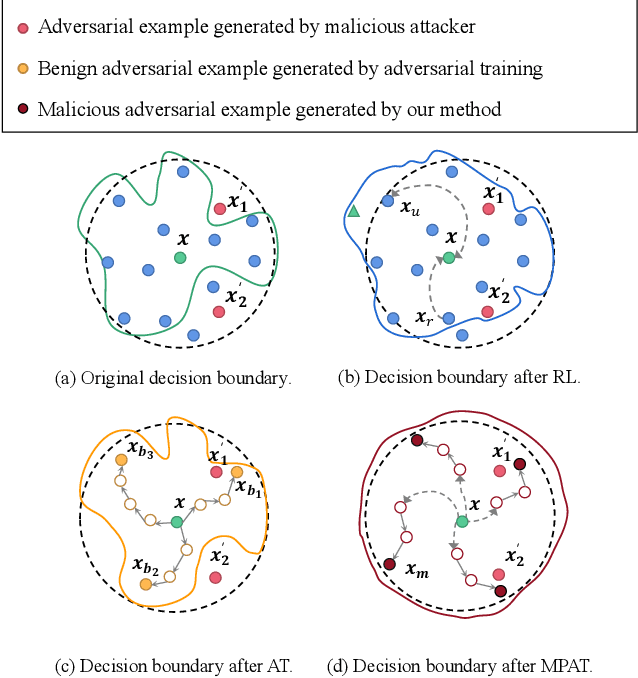
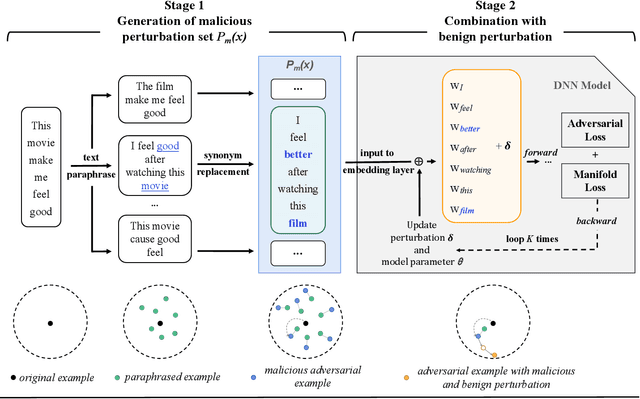
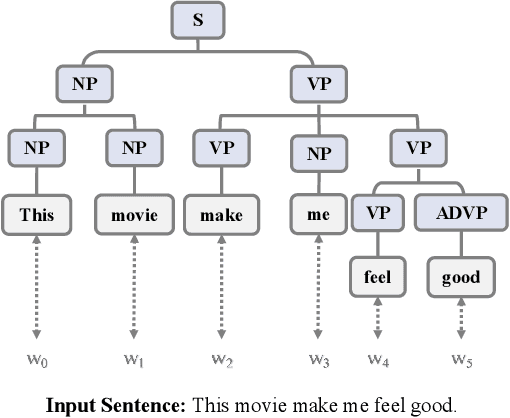
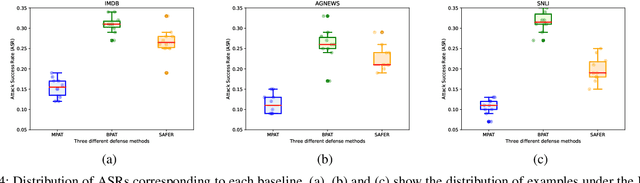
Deep neural networks have been proven to be vulnerable to adversarial examples and various methods have been proposed to defend against adversarial attacks for natural language processing tasks. However, previous defense methods have limitations in maintaining effective defense while ensuring the performance of the original task. In this paper, we propose a malicious perturbation based adversarial training method (MPAT) for building robust deep neural networks against textual adversarial attacks. Specifically, we construct a multi-level malicious example generation strategy to generate adversarial examples with malicious perturbations, which are used instead of original inputs for model training. Additionally, we employ a novel training objective function to ensure achieving the defense goal without compromising the performance on the original task. We conduct comprehensive experiments to evaluate our defense method by attacking five victim models on three benchmark datasets. The result demonstrates that our method is more effective against malicious adversarial attacks compared with previous defense methods while maintaining or further improving the performance on the original task.
PILL: Plug Into LLM with Adapter Expert and Attention Gate
Nov 03, 2023Due to the remarkable capabilities of powerful Large Language Models (LLMs) in effectively following instructions, there has been a growing number of assistants in the community to assist humans. Recently, significant progress has been made in the development of Vision Language Models (VLMs), expanding the capabilities of LLMs and enabling them to execute more diverse instructions. However, it is foreseeable that models will likely need to handle tasks involving additional modalities such as speech, video, and others. This poses a particularly prominent challenge of dealing with the complexity of mixed modalities. To address this, we introduce a novel architecture called PILL: Plug Into LLM with adapter expert and attention gate to better decouple these complex modalities and leverage efficient fine-tuning. We introduce two modules: Firstly, utilizing Mixture-of-Modality-Adapter-Expert to independently handle different modalities, enabling better adaptation to downstream tasks while preserving the expressive capability of the original model. Secondly, by introducing Modality-Attention-Gating, which enables adaptive control of the contribution of modality tokens to the overall representation. In addition, we have made improvements to the Adapter to enhance its learning and expressive capabilities. Experimental results demonstrate that our approach exhibits competitive performance compared to other mainstream methods for modality fusion. For researchers interested in our work, we provide free access to the code and models at https://github.com/DsaltYfish/PILL.
Blind Image Super-resolution with Rich Texture-Aware Codebooks
Oct 26, 2023Blind super-resolution (BSR) methods based on high-resolution (HR) reconstruction codebooks have achieved promising results in recent years. However, we find that a codebook based on HR reconstruction may not effectively capture the complex correlations between low-resolution (LR) and HR images. In detail, multiple HR images may produce similar LR versions due to complex blind degradations, causing the HR-dependent only codebooks having limited texture diversity when faced with confusing LR inputs. To alleviate this problem, we propose the Rich Texture-aware Codebook-based Network (RTCNet), which consists of the Degradation-robust Texture Prior Module (DTPM) and the Patch-aware Texture Prior Module (PTPM). DTPM effectively mines the cross-resolution correlation of textures between LR and HR images by exploiting the cross-resolution correspondence of textures. PTPM uses patch-wise semantic pre-training to correct the misperception of texture similarity in the high-level semantic regularization. By taking advantage of this, RTCNet effectively gets rid of the misalignment of confusing textures between HR and LR in the BSR scenarios. Experiments show that RTCNet outperforms state-of-the-art methods on various benchmarks by up to 0.16 ~ 0.46dB.
Low-Confidence Samples Mining for Semi-supervised Object Detection
Jun 28, 2023Reliable pseudo-labels from unlabeled data play a key role in semi-supervised object detection (SSOD). However, the state-of-the-art SSOD methods all rely on pseudo-labels with high confidence, which ignore valuable pseudo-labels with lower confidence. Additionally, the insufficient excavation for unlabeled data results in an excessively low recall rate thus hurting the network training. In this paper, we propose a novel Low-confidence Samples Mining (LSM) method to utilize low-confidence pseudo-labels efficiently. Specifically, we develop an additional pseudo information mining (PIM) branch on account of low-resolution feature maps to extract reliable large-area instances, the IoUs of which are higher than small-area ones. Owing to the complementary predictions between PIM and the main branch, we further design self-distillation (SD) to compensate for both in a mutually-learning manner. Meanwhile, the extensibility of the above approaches enables our LSM to apply to Faster-RCNN and Deformable-DETR respectively. On the MS-COCO benchmark, our method achieves 3.54% mAP improvement over state-of-the-art methods under 5% labeling ratios.
Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training
Jul 11, 2021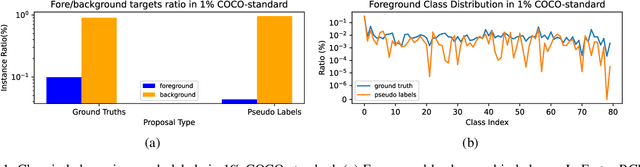
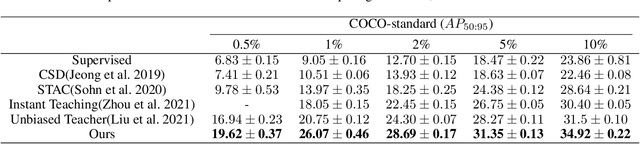
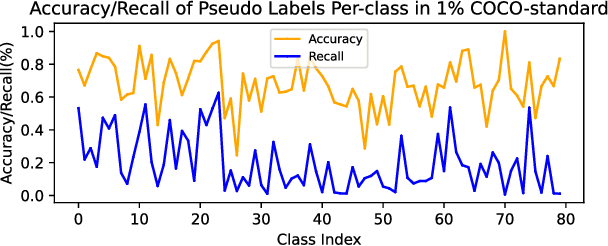
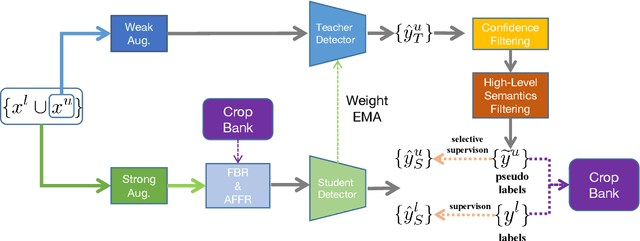
This study delves into semi-supervised object detection (SSOD) to improve detector performance with additional unlabeled data. State-of-the-art SSOD performance has been achieved recently by self-training, in which training supervision consists of ground truths and pseudo-labels. In current studies, we observe that class imbalance in SSOD severely impedes the effectiveness of self-training. To address the class imbalance, we propose adaptive class-rebalancing self-training (ACRST) with a novel memory module called CropBank. ACRST adaptively rebalances the training data with foreground instances extracted from the CropBank, thereby alleviating the class imbalance. Owing to the high complexity of detection tasks, we observe that both self-training and data-rebalancing suffer from noisy pseudo-labels in SSOD. Therefore, we propose a novel two-stage filtering algorithm to generate accurate pseudo-labels. Our method achieves satisfactory improvements on MS-COCO and VOC benchmarks. When using only 1\% labeled data in MS-COCO, our method achieves 17.02 mAP improvement over supervised baselines, and 5.32 mAP improvement compared with state-of-the-art methods.