 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerful Teachers Matter: Text-Guided Multi-view Knowledge Distillation with Visual Prior Enhancement
Mar 25, 2026Knowledge distillation transfers knowledge from large teacher models to smaller students for efficient inference. While existing methods primarily focus on distillation strategies, they often overlook the importance of enhancing teacher knowledge quality. In this paper, we propose Text-guided Multi-view Knowledge Distillation (TMKD), which leverages dual-modality teachers, a visual teacher and a text teacher (CLIP), to provide richer supervisory signals. Specifically, we enhance the visual teacher with multi-view inputs incorporating visual priors (edge and high-frequency features), while the text teacher generates semantic weights through prior-aware prompts to guide adaptive feature fusion. Additionally, we introduce vision-language contrastive regularization to strengthen semantic knowledge in the student model. Extensive experiments on five benchmarks demonstrate that TMKD consistently improves knowledge distillation performance by up to 4.49\%, validating the effectiveness of our dual-teacher multi-view enhancement strategy. Code is available at https://anonymous.4open.science/r/TMKD-main-44D1.
Structured Personality Control and Adaptation for LLM Agents
Jan 15, 2026Large Language Models (LLMs) are increasingly shaping human-computer interaction (HCI), from personalized assistants to social simulations. Beyond language competence, researchers are exploring whether LLMs can exhibit human-like characteristics that influence engagement, decision-making, and perceived realism. Personality, in particular, is critical, yet existing approaches often struggle to achieve both nuanced and adaptable expression. We present a framework that models LLM personality via Jungian psychological types, integrating three mechanisms: a dominant-auxiliary coordination mechanism for coherent core expression, a reinforcement-compensation mechanism for temporary adaptation to context, and a reflection mechanism that drives long-term personality evolution. This design allows the agent to maintain nuanced traits while dynamically adjusting to interaction demands and gradually updating its underlying structure. Personality alignment is evaluated using Myers-Briggs Type Indicator questionnaires and tested under diverse challenge scenarios as a preliminary structured assessment. Findings suggest that evolving, personality-aware LLMs can support coherent, context-sensitive interactions, enabling naturalistic agent design in HCI.
NoisyAG-News: A Benchmark for Addressing Instance-Dependent Noise in Text Classification
Jul 09, 2024



Existing research on learning with noisy labels predominantly focuses on synthetic label noise. Although synthetic noise possesses well-defined structural properties, it often fails to accurately replicate real-world noise patterns. In recent years, there has been a concerted effort to construct generalizable and controllable instance-dependent noise datasets for image classification, significantly advancing the development of noise-robust learning in this area. However, studies on noisy label learning for text classification remain scarce. To better understand label noise in real-world text classification settings, we constructed the benchmark dataset NoisyAG-News through manual annotation. Initially, we analyzed the annotated data to gather observations about real-world noise. We qualitatively and quantitatively demonstrated that real-world noisy labels adhere to instance-dependent patterns. Subsequently, we conducted comprehensive learning experiments on NoisyAG-News and its corresponding synthetic noise datasets using pre-trained language models and noise-handling techniques. Our findings reveal that while pre-trained models are resilient to synthetic noise, they struggle against instance-dependent noise, with samples of varying confusion levels showing inconsistent performance during training and testing. These real-world noise patterns pose new, significant challenges, prompting a reevaluation of noisy label handling methods. We hope that NoisyAG-News will facilitate the development and evaluation of future solutions for learning with noisy labels.
PILL: Plug Into LLM with Adapter Expert and Attention Gate
Nov 03, 2023Due to the remarkable capabilities of powerful Large Language Models (LLMs) in effectively following instructions, there has been a growing number of assistants in the community to assist humans. Recently, significant progress has been made in the development of Vision Language Models (VLMs), expanding the capabilities of LLMs and enabling them to execute more diverse instructions. However, it is foreseeable that models will likely need to handle tasks involving additional modalities such as speech, video, and others. This poses a particularly prominent challenge of dealing with the complexity of mixed modalities. To address this, we introduce a novel architecture called PILL: Plug Into LLM with adapter expert and attention gate to better decouple these complex modalities and leverage efficient fine-tuning. We introduce two modules: Firstly, utilizing Mixture-of-Modality-Adapter-Expert to independently handle different modalities, enabling better adaptation to downstream tasks while preserving the expressive capability of the original model. Secondly, by introducing Modality-Attention-Gating, which enables adaptive control of the contribution of modality tokens to the overall representation. In addition, we have made improvements to the Adapter to enhance its learning and expressive capabilities. Experimental results demonstrate that our approach exhibits competitive performance compared to other mainstream methods for modality fusion. For researchers interested in our work, we provide free access to the code and models at https://github.com/DsaltYfish/PILL.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
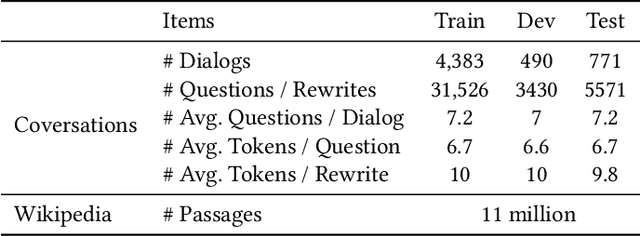
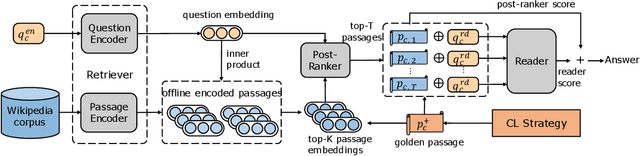
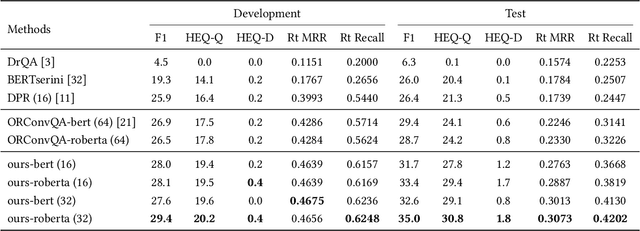
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
Learning Human Motion Prediction via Stochastic Differential Equations
Dec 21, 2021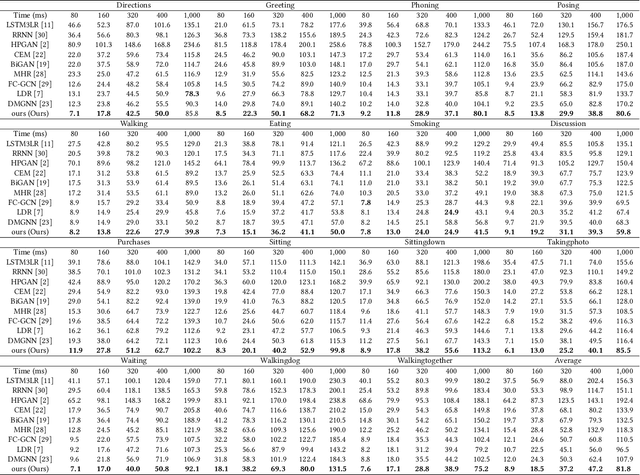
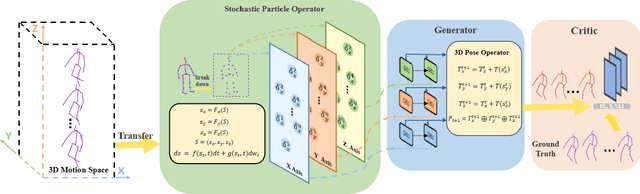
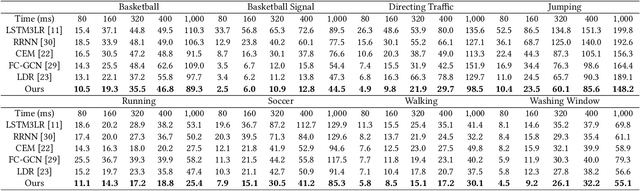
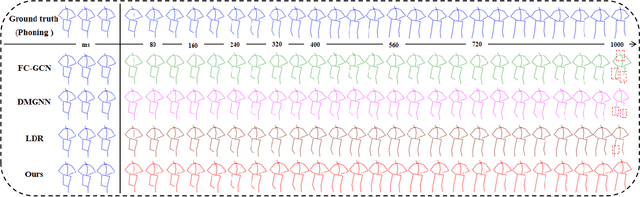
Human motion understanding and prediction is an integral aspect in our pursuit of machine intelligence and human-machine interaction systems. Current methods typically pursue a kinematics modeling approach, relying heavily upon prior anatomical knowledge and constraints. However, such an approach is hard to generalize to different skeletal model representations, and also tends to be inadequate in accounting for the dynamic range and complexity of motion, thus hindering predictive accuracy. In this work, we propose a novel approach in modeling the motion prediction problem based on stochastic differential equations and path integrals. The motion profile of each skeletal joint is formulated as a basic stochastic variable and modeled with the Langevin equation. We develop a strategy of employing GANs to simulate path integrals that amounts to optimizing over possible future paths. We conduct experiments in two large benchmark datasets, Human 3.6M and CMU MoCap. It is highlighted that our approach achieves a 12.48% accuracy improvement over current state-of-the-art methods in average.
Spatial-Temporal Deep Intention Destination Networks for Online Travel Planning
Aug 09, 2021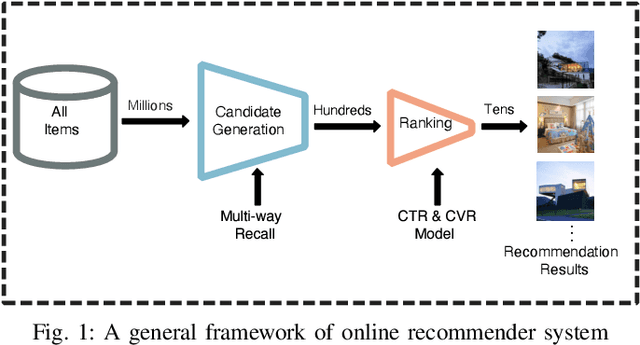
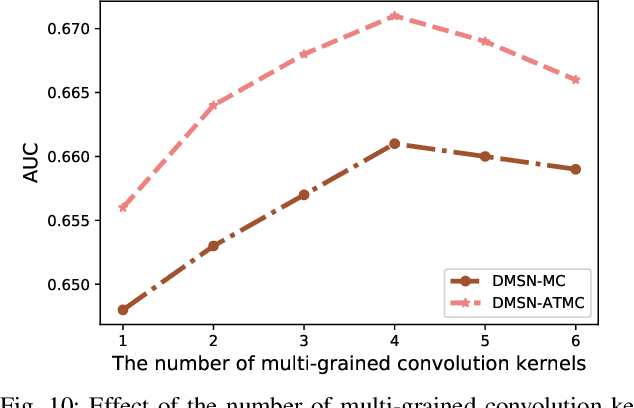
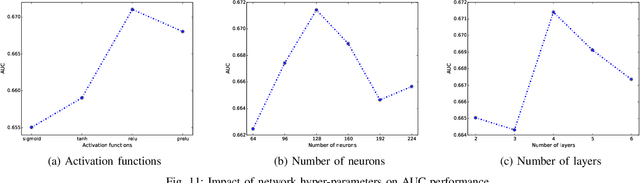
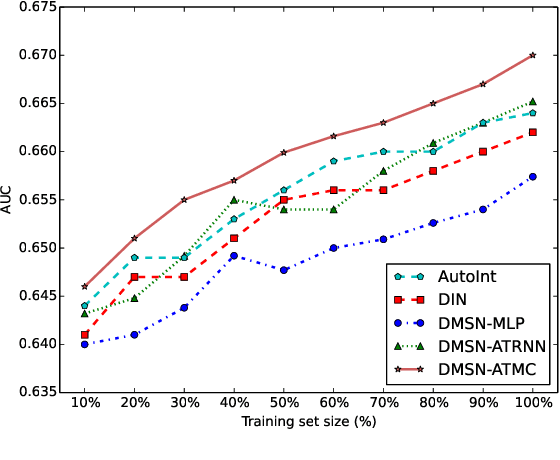
Nowadays, artificial neural networks are widely used for users' online travel planning. Personalized travel planning has many real applications and is affected by various factors, such as transportation type, intention destination estimation, budget limit and crowdness prediction. Among those factors, users' intention destination prediction is an essential task in online travel platforms. The reason is that, the user may be interested in the travel plan only when the plan matches his real intention destination. Therefore, in this paper, we focus on predicting users' intention destinations in online travel platforms. In detail, we act as online travel platforms (such as Fliggy and Airbnb) to recommend travel plans for users, and the plan consists of various vacation items including hotel package, scenic packages and so on. Predicting the actual intention destination in travel planning is challenging. Firstly, users' intention destination is highly related to their travel status (e.g., planning for a trip or finishing a trip). Secondly, users' actions (e.g. clicking, searching) over different product types (e.g. train tickets, visa application) have different indications in destination prediction. Thirdly, users may mostly visit the travel platforms just before public holidays, and thus user behaviors in online travel platforms are more sparse, low-frequency and long-period. Therefore, we propose a Deep Multi-Sequences fused neural Networks (DMSN) to predict intention destinations from fused multi-behavior sequences. Real datasets are used to evaluate the performance of our proposed DMSN models. Experimental results indicate that the proposed DMSN models can achieve high intention destination prediction accuracy.
Joint Training Capsule Network for Cold Start Recommendation
May 23, 2020


This paper proposes a novel neural network, joint training capsule network (JTCN), for the cold start recommendation task. We propose to mimic the high-level user preference other than the raw interaction history based on the side information for the fresh users. Specifically, an attentive capsule layer is proposed to aggregate high-level user preference from the low-level interaction history via a dynamic routing-by-agreement mechanism. Moreover, JTCN jointly trains the loss for mimicking the user preference and the softmax loss for the recommendation together in an end-to-end manner. Experiments on two publicly available datasets demonstrate the effectiveness of the proposed model. JTCN improves other state-of-the-art methods at least 7.07% for CiteULike and 16.85% for Amazon in terms of Recall@100 in cold start recommendation.