 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealDexUMI: A Wearable Universal Manipulation Interface for Dexterous Robot Learning
Jun 04, 2026Learning dexterous manipulation requires demonstrations that preserve fine hand-object interactions while remaining executable at deployment. Existing pipelines either lose deployable dexterity through retargeting or embodiment conversion, or rely on robot-specific teleoperation that is costly to scale and often lacks intuitive, contact-aware control for dexterous data collection. We present RealDexUMI, a wearable universal manipulation interface built around a shared dexterous end-effector module that integrates a lightweight dexterous hand, in-hand vision, and fingertip tactile sensing. A palm-side isomorphic teleoperation glove maps human finger inputs to robot-hand joint commands, enabling real-time, retargeting-free, intuitive, and precise hand control. The shared hand and sensing modules yield zero-gap end-effector data, with matched in-hand observations, tactile signals, contacts, and hand actions between collection and deployment. Across eight real-robot tasks spanning fine-grained, contact-rich, long-horizon, and bimanual manipulation, policies trained on RealDexUMI data achieve an average success rate of 88.75%, generalize to unseen initial poses, and transfer across three embodiments. Website: https://research.beingbeyond.com/realdexumi
AgentVLN: Towards Agentic Vision-and-Language Navigation
Mar 18, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to ground complex natural-language instructions into long-horizon navigation in unseen environments. While Vision-Language Models (VLMs) offer strong 2D semantic understanding, current VLN systems remain constrained by limited spatial perception, 2D-3D representation mismatch, and monocular scale ambiguity. In this paper, we propose AgentVLN, a novel and efficient embodied navigation framework that can be deployed on edge computing platforms. We formulate VLN as a Partially Observable Semi-Markov Decision Process (POSMDP) and introduce a VLM-as-Brain paradigm that decouples high-level semantic reasoning from perception and planning via a plug-and-play skill library. To resolve multi-level representation inconsistency, we design a cross-space representation mapping that projects perception-layer 3D topological waypoints into the image plane, yielding pixel-aligned visual prompts for the VLM. Building on this bridge, we integrate a context-aware self-correction and active exploration strategy to recover from occlusions and suppress error accumulation over long trajectories. To further address the spatial ambiguity of instructions in unstructured environments, we propose a Query-Driven Perceptual Chain-of-Thought (QD-PCoT) scheme, enabling the agent with the metacognitive ability to actively seek geometric depth information. Finally, we construct AgentVLN-Instruct, a large-scale instruction-tuning dataset with dynamic stage routing conditioned on target visibility. Extensive experiments show that AgentVLN consistently outperforms prior state-of-the-art methods (SOTA) on long-horizon VLN benchmarks, offering a practical paradigm for lightweight deployment of next-generation embodied navigation models. Code: https://github.com/Allenxinn/AgentVLN.
DecoVLN: Decoupling Observation, Reasoning, and Correction for Vision-and-Language Navigation
Mar 13, 2026Vision-and-Language Navigation (VLN) requires agents to follow long-horizon instructions and navigate complex 3D environments. However, existing approaches face two major challenges: constructing an effective long-term memory bank and overcoming the compounding errors problem. To address these issues, we propose DecoVLN, an effective framework designed for robust streaming perception and closed-loop control in long-horizon navigation. First, we formulate long-term memory construction as an optimization problem and introduce adaptive refinement mechanism that selects frames from a historical candidate pool by iteratively optimizing a unified scoring function. This function jointly balances three key criteria: semantic relevance to the instruction, visual diversity from the selected memory, and temporal coverage of the historical trajectory. Second, to alleviate compounding errors, we introduce a state-action pair-level corrective finetuning strategy. By leveraging geodesic distance between states to precisely quantify deviation from the expert trajectory, the agent collects high-quality state-action pairs in the trusted region while filtering out the polluted data with low relevance. This improves both the efficiency and stability of error correction. Extensive experiments demonstrate the effectiveness of DecoVLN, and we have deployed it in real-world environments.
Social Catalysts, Not Moral Agents: The Illusion of Alignment in LLM Societies
Feb 01, 2026The rapid evolution of Large Language Models (LLMs) has led to the emergence of Multi-Agent Systems where collective cooperation is often threatened by the "Tragedy of the Commons." This study investigates the effectiveness of Anchoring Agents--pre-programmed altruistic entities--in fostering cooperation within a Public Goods Game (PGG). Using a full factorial design across three state-of-the-art LLMs, we analyzed both behavioral outcomes and internal reasoning chains. While Anchoring Agents successfully boosted local cooperation rates, cognitive decomposition and transfer tests revealed that this effect was driven by strategic compliance and cognitive offloading rather than genuine norm internalization. Notably, most agents reverted to self-interest in new environments, and advanced models like GPT-4.1 exhibited a "Chameleon Effect," masking strategic defection under public scrutiny. These findings highlight a critical gap between behavioral modification and authentic value alignment in artificial societies.
Adaptive Spatial Transcriptomics Interpolation via Cross-modal Cross-slice Modeling
May 15, 2025Spatial transcriptomics (ST) is a promising technique that characterizes the spatial gene profiling patterns within the tissue context. Comprehensive ST analysis depends on consecutive slices for 3D spatial insights, whereas the missing intermediate tissue sections and high costs limit the practical feasibility of generating multi-slice ST. In this paper, we propose C2-STi, the first attempt for interpolating missing ST slices at arbitrary intermediate positions between adjacent ST slices. Despite intuitive, effective ST interpolation presents significant challenges, including 1) limited continuity across heterogeneous tissue sections, 2) complex intrinsic correlation across genes, and 3) intricate cellular structures and biological semantics within each tissue section. To mitigate these challenges, in C2-STi, we design 1) a distance-aware local structural modulation module to adaptively capture cross-slice deformations and enhance positional correlations between ST slices, 2) a pyramid gene co-expression correlation module to capture multi-scale biological associations among genes, and 3) a cross-modal alignment module that integrates the ST-paired hematoxylin and eosin (H&E)-stained images to filter and align the essential cellular features across ST and H\&E images. Extensive experiments on the public dataset demonstrate our superiority over state-of-the-art approaches on both single-slice and multi-slice ST interpolation. Codes are available at https://github.com/XiaofeiWang2018/C2-STi.
Redundant feature screening method for human activity recognition based on attention purification mechanism
Mar 30, 2025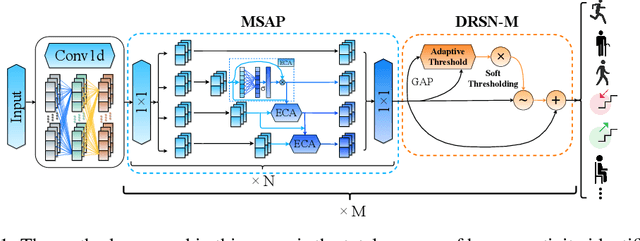
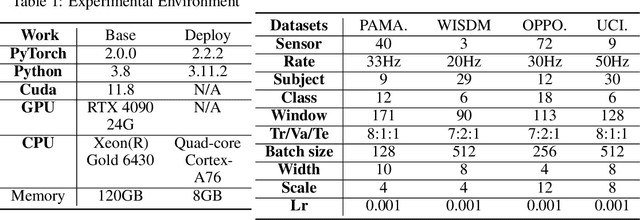
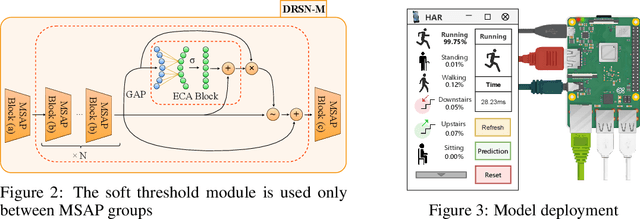
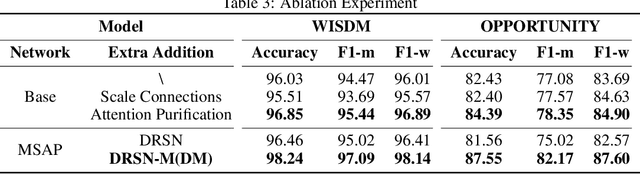
In the field of sensor-based Human Activity Recognition (HAR), deep neural networks provide advanced technical support. Many studies have proven that recognition accuracy can be improved by increasing the depth or width of the network. However, for wearable devices, the balance between network performance and resource consumption is crucial. With minimum resource consumption as the basic principle, we propose a universal attention feature purification mechanism, called MSAP, which is suitable for multi-scale networks. The mechanism effectively solves the feature redundancy caused by the superposition of multi-scale features by means of inter-scale attention screening and connection method. In addition, we have designed a network correction module that integrates seamlessly between layers of individual network modules to mitigate inherent problems in deep networks. We also built an embedded deployment system that is in line with the current level of wearable technology to test the practical feasibility of the HAR model, and further prove the efficiency of the method. Extensive experiments on four public datasets show that the proposed method model effectively reduces redundant features in filtered data and provides excellent performance with little resource consumption.
CMD-HAR: Cross-Modal Disentanglement for Wearable Human Activity Recognition
Mar 27, 2025Human Activity Recognition (HAR) is a fundamental technology for numerous human - centered intelligent applications. Although deep learning methods have been utilized to accelerate feature extraction, issues such as multimodal data mixing, activity heterogeneity, and complex model deployment remain largely unresolved. The aim of this paper is to address issues such as multimodal data mixing, activity heterogeneity, and complex model deployment in sensor-based human activity recognition. We propose a spatiotemporal attention modal decomposition alignment fusion strategy to tackle the problem of the mixed distribution of sensor data. Key discriminative features of activities are captured through cross-modal spatio-temporal disentangled representation, and gradient modulation is combined to alleviate data heterogeneity. In addition, a wearable deployment simulation system is constructed. We conducted experiments on a large number of public datasets, demonstrating the effectiveness of the model.
MobA: A Two-Level Agent System for Efficient Mobile Task Automation
Oct 17, 2024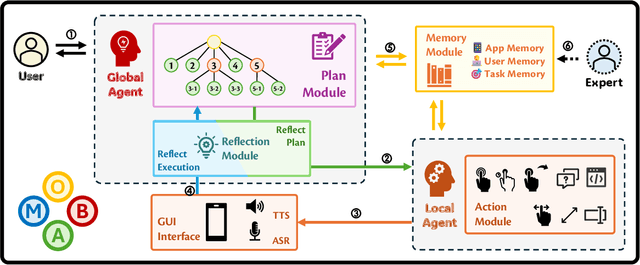
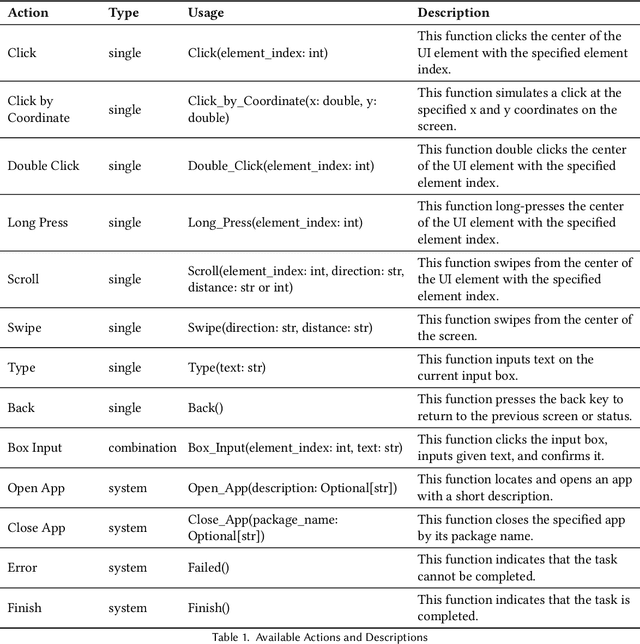
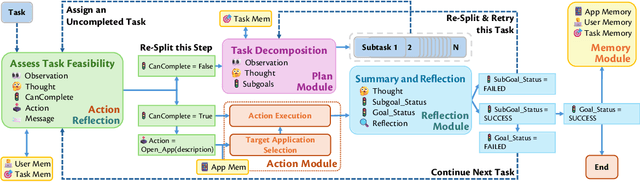
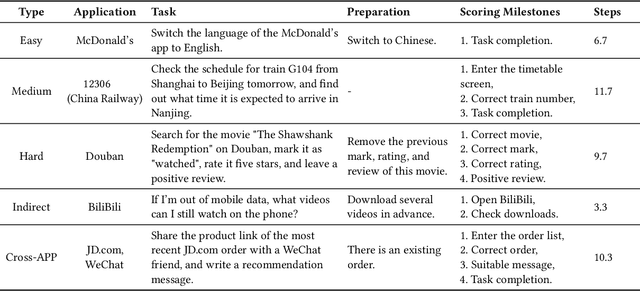
Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities. To address these challenges, we propose MobA, a novel Mobile phone Agent powered by multimodal large language models that enhances comprehension and planning capabilities through a sophisticated two-level agent architecture. The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA. Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
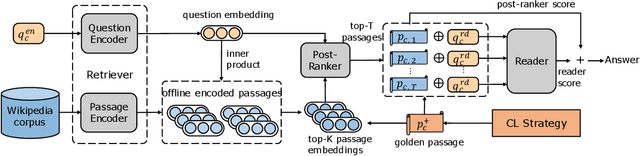
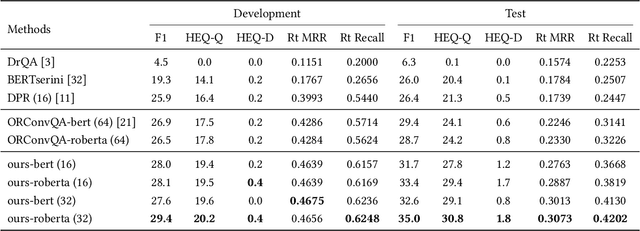
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
Adaptive Learning Rate and Momentum for Training Deep Neural Networks
Jun 22, 2021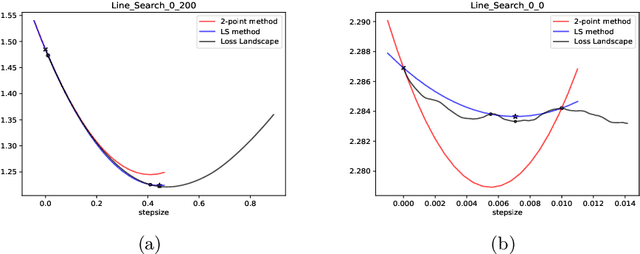
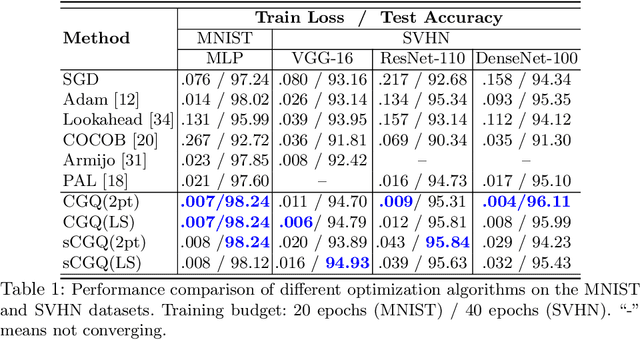
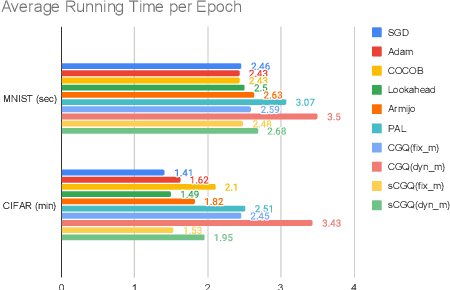
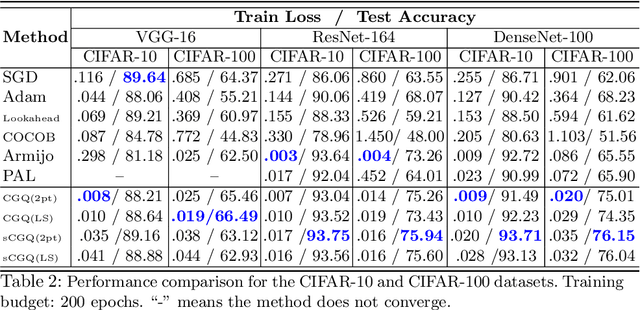
Recent progress on deep learning relies heavily on the quality and efficiency of training algorithms. In this paper, we develop a fast training method motivated by the nonlinear Conjugate Gradient (CG) framework. We propose the Conjugate Gradient with Quadratic line-search (CGQ) method. On the one hand, a quadratic line-search determines the step size according to current loss landscape. On the other hand, the momentum factor is dynamically updated in computing the conjugate gradient parameter (like Polak-Ribiere). Theoretical results to ensure the convergence of our method in strong convex settings is developed. And experiments in image classification datasets show that our method yields faster convergence than other local solvers and has better generalization capability (test set accuracy). One major advantage of the paper method is that tedious hand tuning of hyperparameters like the learning rate and momentum is avoided.