 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-level Randomization: Toward More Stable LLM Evaluations
Sep 16, 2025



Evaluations of large language models (LLMs) suffer from instability, where small changes of random factors such as few-shot examples can lead to drastic fluctuations of scores and even model rankings. Moreover, different LLMs can have different preferences for a certain setting of random factors. As a result, using a fixed setting of random factors, which is often adopted as the paradigm of current evaluations, can lead to potential unfair comparisons between LLMs. To mitigate the volatility of evaluations, we first theoretically analyze the sources of variance induced by changes in random factors. Targeting these specific sources, we then propose the instance-level randomization (ILR) method to reduce variance and enhance fairness in model comparisons. Instead of using a fixed setting across the whole benchmark in a single experiment, we randomize all factors that affect evaluation scores for every single instance, run multiple experiments and report the averaged score. Theoretical analyses and empirical results demonstrate that ILR can reduce the variance and unfair comparisons caused by random factors, as well as achieve similar robustness level with less than half computational cost compared with previous methods.
NeuSym-RAG: Hybrid Neural Symbolic Retrieval with Multiview Structuring for PDF Question Answering
May 26, 2025The increasing number of academic papers poses significant challenges for researchers to efficiently acquire key details. While retrieval augmented generation (RAG) shows great promise in large language model (LLM) based automated question answering, previous works often isolate neural and symbolic retrieval despite their complementary strengths. Moreover, conventional single-view chunking neglects the rich structure and layout of PDFs, e.g., sections and tables. In this work, we propose NeuSym-RAG, a hybrid neural symbolic retrieval framework which combines both paradigms in an interactive process. By leveraging multi-view chunking and schema-based parsing, NeuSym-RAG organizes semi-structured PDF content into both the relational database and vectorstore, enabling LLM agents to iteratively gather context until sufficient to generate answers. Experiments on three full PDF-based QA datasets, including a self-annotated one AIRQA-REAL, show that NeuSym-RAG stably defeats both the vector-based RAG and various structured baselines, highlighting its capacity to unify both retrieval schemes and utilize multiple views. Code and data are publicly available at https://github.com/X-LANCE/NeuSym-RAG.
MobA: A Two-Level Agent System for Efficient Mobile Task Automation
Oct 17, 2024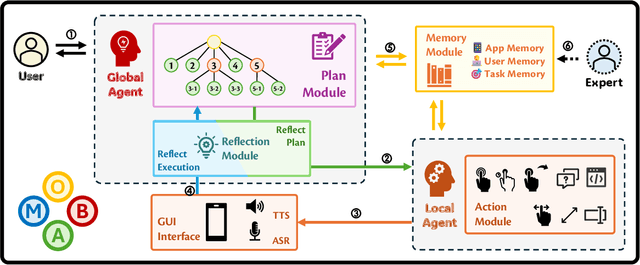
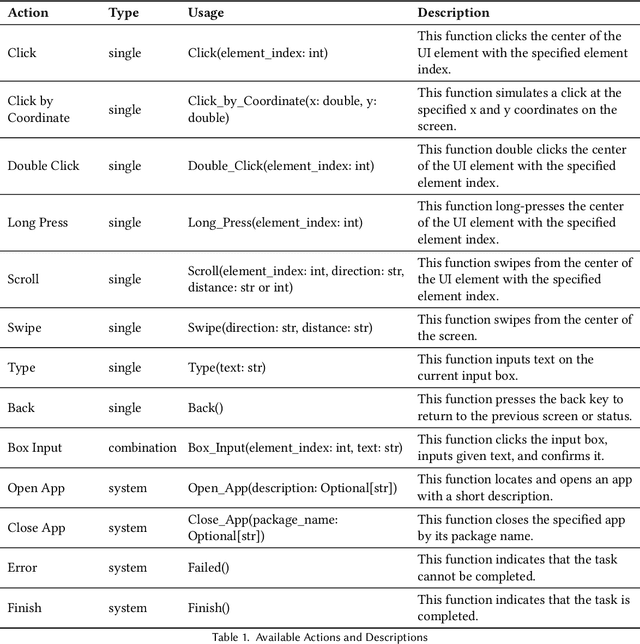
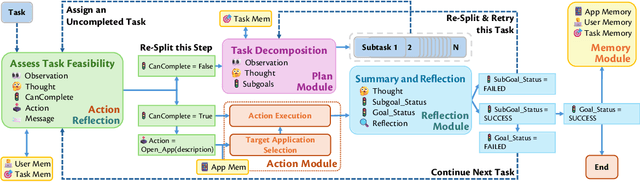
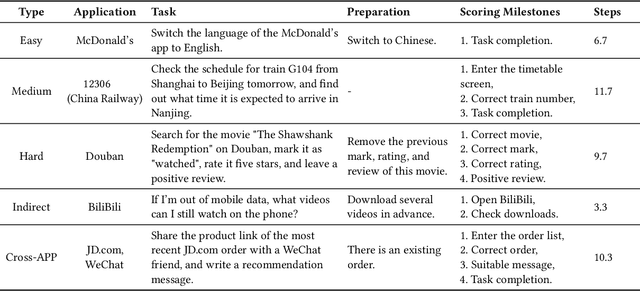
Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities. To address these challenges, we propose MobA, a novel Mobile phone Agent powered by multimodal large language models that enhances comprehension and planning capabilities through a sophisticated two-level agent architecture. The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA. Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.
SciDFM: A Large Language Model with Mixture-of-Experts for Science
Sep 27, 2024



Recently, there has been a significant upsurge of interest in leveraging large language models (LLMs) to assist scientific discovery. However, most LLMs only focus on general science, while they lack domain-specific knowledge, such as chemical molecules and amino acid sequences. To bridge these gaps, we introduce SciDFM, a mixture-of-experts LLM, which is trained from scratch and is able to conduct college-level scientific reasoning and understand molecules and amino acid sequences. We collect a large-scale training corpus containing numerous scientific papers and books from different disciplines as well as data from domain-specific databases. We further fine-tune the pre-trained model on lots of instruction data to improve performances on downstream benchmarks. From experiment results, we show that SciDFM achieves strong performance on general scientific benchmarks such as SciEval and SciQ, and it reaches a SOTA performance on domain-specific benchmarks among models of similar size. We further analyze the expert layers and show that the results of expert selection vary with data from different disciplines. To benefit the broader research community, we open-source SciDFM at https://huggingface.co/OpenDFM/SciDFM-MoE-A5.6B-v1.0.
Sparsity-Accelerated Training for Large Language Models
Jun 03, 2024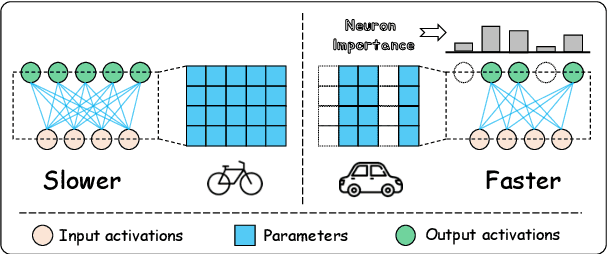
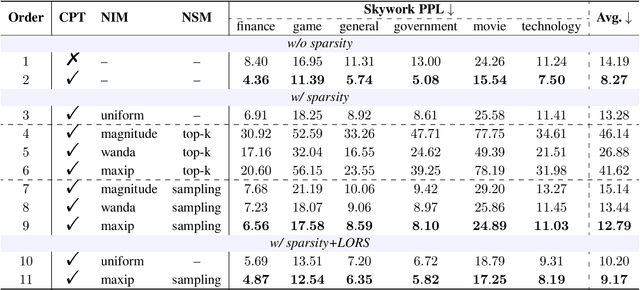
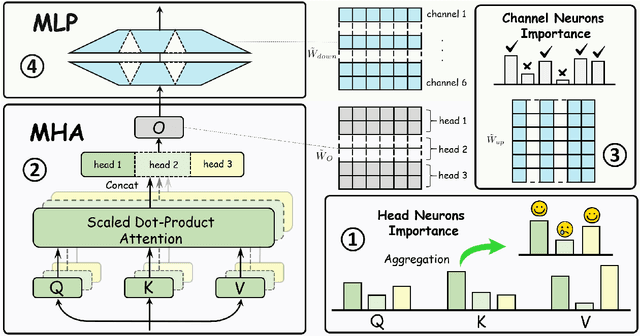
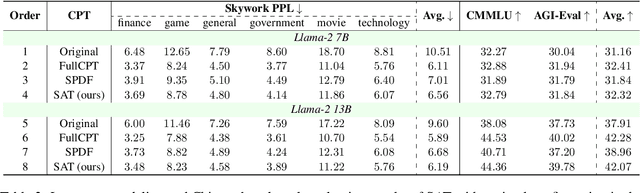
Large language models (LLMs) have demonstrated proficiency across various natural language processing (NLP) tasks but often require additional training, such as continual pre-training and supervised fine-tuning. However, the costs associated with this, primarily due to their large parameter count, remain high. This paper proposes leveraging \emph{sparsity} in pre-trained LLMs to expedite this training process. By observing sparsity in activated neurons during forward iterations, we identify the potential for computational speed-ups by excluding inactive neurons. We address associated challenges by extending existing neuron importance evaluation metrics and introducing a ladder omission rate scheduler. Our experiments on Llama-2 demonstrate that Sparsity-Accelerated Training (SAT) achieves comparable or superior performance to standard training while significantly accelerating the process. Specifically, SAT achieves a $45\%$ throughput improvement in continual pre-training and saves $38\%$ training time in supervised fine-tuning in practice. It offers a simple, hardware-agnostic, and easily deployable framework for additional LLM training. Our code is available at https://github.com/OpenDFM/SAT.
Multi: Multimodal Understanding Leaderboard with Text and Images
Feb 05, 2024
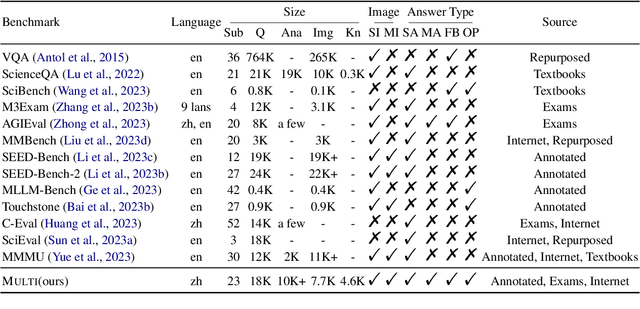

Rapid progress in multimodal large language models (MLLMs) highlights the need to introduce challenging yet realistic benchmarks to the academic community. Existing benchmarks primarily focus on simple natural image understanding, but Multi emerges as a cutting-edge benchmark for MLLMs, offering a comprehensive dataset for evaluating MLLMs against understanding complex figures and tables, and scientific questions. This benchmark, reflecting current realistic examination styles, provides multimodal inputs and requires responses that are either precise or open-ended, similar to real-life school tests. It challenges MLLMs with a variety of tasks, ranging from formula derivation to image detail analysis, and cross-modality reasoning. Multi includes over 18,000 questions, with a focus on science-based QA in diverse formats. We also introduce Multi-Elite, a 500-question subset for testing the extremities of MLLMs, and Multi-Extend, which enhances In-Context Learning research with more than 4,500 knowledge pieces. Our evaluation indicates significant potential for MLLM advancement, with GPT-4V achieving a 63.7% accuracy rate on Multi, in contrast to other MLLMs scoring between 31.3% and 53.7%. Multi serves not only as a robust evaluation platform but also paves the way for the development of expert-level AI.
ChemDFM: Dialogue Foundation Model for Chemistry
Jan 26, 2024



Large language models (LLMs) have established great success in the general domain of natural language processing. Their emerging task generalization and free-form dialogue capabilities can greatly help to design Chemical General Intelligence (CGI) to assist real-world research in chemistry. However, the existence of specialized language and knowledge in the field of chemistry, such as the highly informative SMILES notation, hinders the performance of general-domain LLMs in chemistry. To this end, we develop ChemDFM, the first LLM towards CGI. ChemDFM-13B is trained on 34B tokens from chemical literature, textbooks, and instructions as well as various data from the general domain. Therefore, it can store, understand, and reason over chemical knowledge and languages while still possessing advanced free-form language comprehension capabilities. Extensive quantitative evaluation shows that ChemDFM can significantly outperform the representative open-sourced LLMs. Moreover, ChemDFM can also surpass GPT-4 on a great portion of chemical tasks, despite the significant size difference. Further qualitative evaluations demonstrate the efficiency and effectiveness of ChemDFM in real-world research scenarios. We will open-source the ChemDFM model soon.
SciEval: A Multi-Level Large Language Model Evaluation Benchmark for Scientific Research
Aug 25, 2023Recently, there has been growing interest in using Large Language Models (LLMs) for scientific research. Numerous benchmarks have been proposed to evaluate the ability of LLMs for scientific research. However, current benchmarks are mostly based on pre-collected objective questions. This design suffers from data leakage problem and lacks the evaluation of subjective Q/A ability. In this paper, we propose SciEval, a comprehensive and multi-disciplinary evaluation benchmark to address these issues. Based on Bloom's taxonomy, SciEval covers four dimensions to systematically evaluate scientific research ability. In particular, we design a "dynamic" subset based on scientific principles to prevent evaluation from potential data leakage. Both objective and subjective questions are included in SciEval. These characteristics make SciEval a more effective benchmark for scientific research ability evaluation of LLMs. Comprehensive experiments on most advanced LLMs show that, although GPT-4 achieves SOTA performance compared to other LLMs, there is still substantial room for improvement, especially for dynamic questions. The data and codes are now publicly available.
META-GUI: Towards Multi-modal Conversational Agents on Mobile GUI
May 23, 2022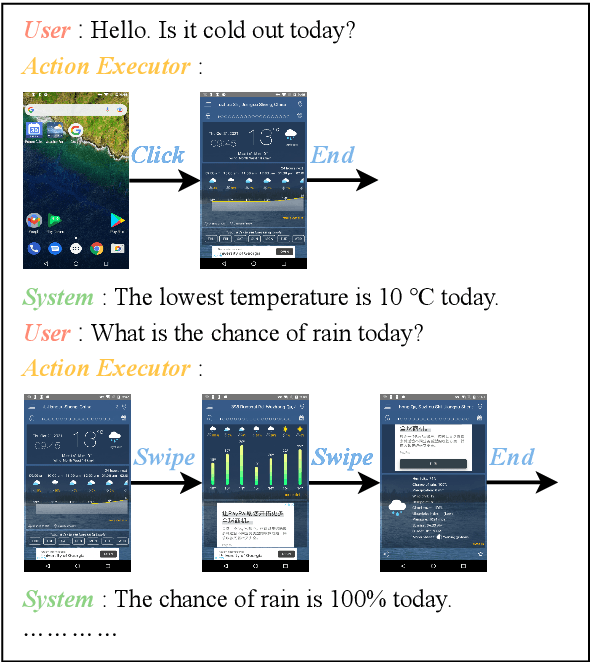

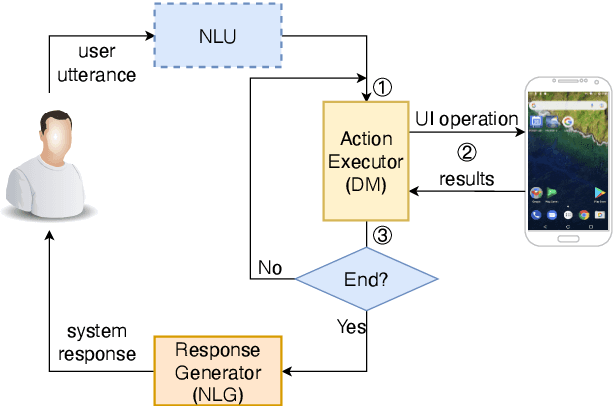
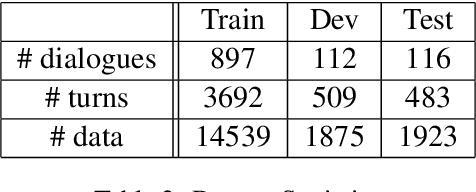
Task-oriented dialogue (TOD) systems have been widely used by mobile phone intelligent assistants to accomplish tasks such as calendar scheduling or hotel booking. Current TOD systems usually focus on multi-turn text/speech interaction and reply on calling back-end APIs to search database information or execute the task on mobile phone. However, this architecture greatly limits the information searching capability of intelligent assistants and may even lead to task failure if APIs are not available or the task is too complicated to be executed by the provided APIs. In this paper, we propose a new TOD architecture: GUI-based task-oriented dialogue system (GUI-TOD). A GUI-TOD system can directly perform GUI operations on real APPs and execute tasks without invoking backend APIs. Furthermore, we release META-GUI, a dataset for training a Multi-modal conversational agent on mobile GUI. We also propose a multi-model action prediction and response model. It showed promising results on META-GUI, but there is still room for further improvement. The dataset and models will be publicly available.