 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning
Jan 08, 2026Large Language Model (LLM)-based agents significantly extend the utility of LLMs by interacting with dynamic environments. However, enabling agents to continually learn new tasks without catastrophic forgetting remains a critical challenge, known as the stability-plasticity dilemma. In this work, we argue that this dilemma fundamentally arises from the failure to explicitly distinguish between common knowledge shared across tasks and conflicting knowledge introduced by task-specific interference. To address this, we propose Agent-Dice, a parameter fusion framework based on directional consensus evaluation. Concretely, Agent-Dice disentangles knowledge updates through a two-stage process: geometric consensus filtering to prune conflicting gradients, and curvature-based importance weighting to amplify shared semantics. We provide a rigorous theoretical analysis that establishes the validity of the proposed fusion scheme and offers insight into the origins of the stability-plasticity dilemma. Extensive experiments on GUI agents and tool-use agent domains demonstrate that Agent-Dice exhibits outstanding continual learning performance with minimal computational overhead and parameter updates. The codes are available at https://github.com/Wuzheng02/Agent-Dice.
DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
May 29, 2025


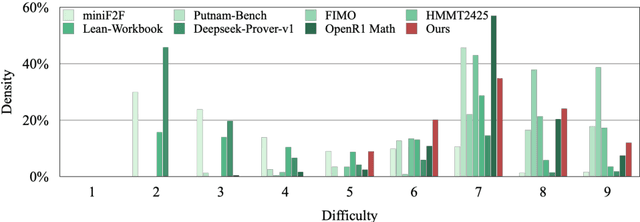
Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs' strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem's potential to fundamentally advance automated informal theorem proving and mathematical exploration.
Dancing with Critiques: Enhancing LLM Reasoning with Stepwise Natural Language Self-Critique
Mar 21, 2025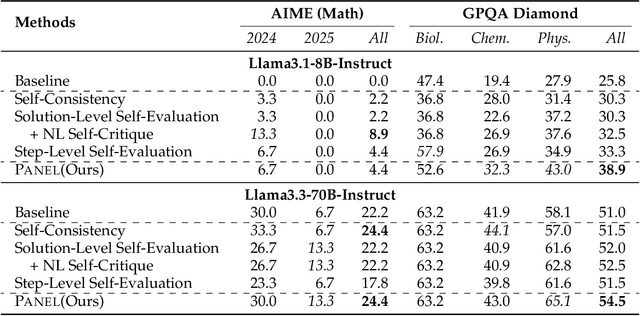

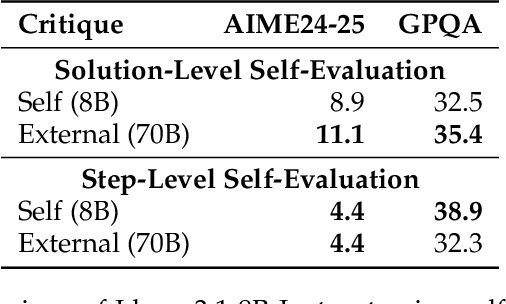

Enhancing the reasoning capabilities of large language models (LLMs), particularly for complex tasks requiring multi-step logical deductions, remains a significant challenge. Traditional inference time scaling methods utilize scalar reward signals from process reward models to evaluate candidate reasoning steps, but these scalar rewards lack the nuanced qualitative information essential for understanding and justifying each step. In this paper, we propose a novel inference-time scaling approach -- stepwise natural language self-critique (PANEL), which employs self-generated natural language critiques as feedback to guide the step-level search process. By generating rich, human-readable critiques for each candidate reasoning step, PANEL retains essential qualitative information, facilitating better-informed decision-making during inference. This approach bypasses the need for task-specific verifiers and the associated training overhead, making it broadly applicable across diverse tasks. Experimental results on challenging reasoning benchmarks, including AIME and GPQA, demonstrate that PANEL significantly enhances reasoning performance, outperforming traditional scalar reward-based methods. Our code is available at https://github.com/puddingyeah/PANEL to support and encourage future research in this promising field.
MobA: A Two-Level Agent System for Efficient Mobile Task Automation
Oct 17, 2024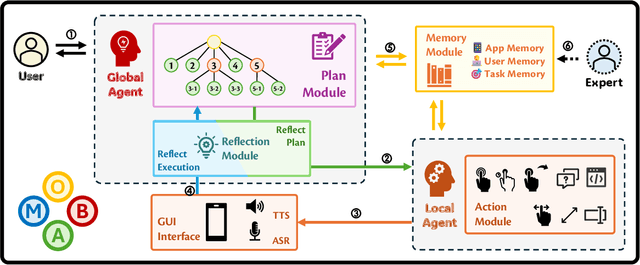
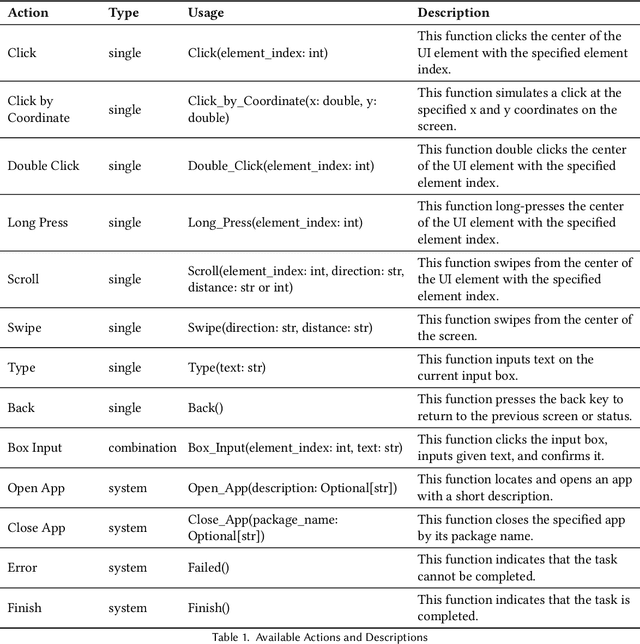
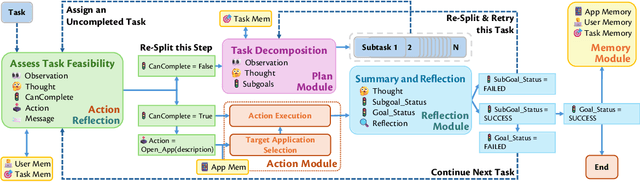
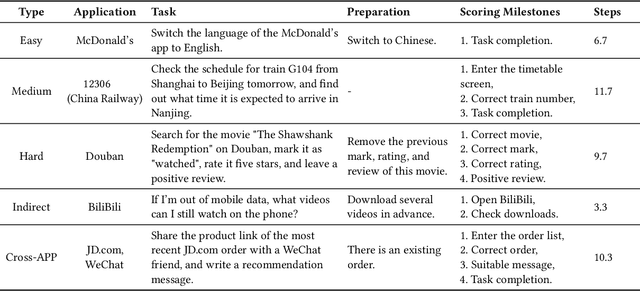
Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities. To address these challenges, we propose MobA, a novel Mobile phone Agent powered by multimodal large language models that enhances comprehension and planning capabilities through a sophisticated two-level agent architecture. The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA. Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.