 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Policy Evolution for Proactive LLM Agents
Jun 12, 2026LLM agents have rapidly evolved into autonomous systems, yet a persistent information gap remains between users and agents: communication is costly, while users' identical preferences further limit information exchange. To investigate how agents should communicate across modalities, this paper formalizes Communication Policy, establishes textual and UI-based policies, and then evaluates communication policies across diverse environments, personas, and model combinations. Building information asymmetry for proactive agents, we set up two complementary settings, User-Agent and Planner-Executor. Experimental results reveal complementary strengths between interaction channels: text-based interaction often facilitates task performance, while structured UI improves agents' response quality and persona compliance. Motivated by that, a hybrid method combines these advantages. We further propose Communication Policy Evolution (CPE), a self-evolution framework for refining communication policies through rollout and prompt-level evolving. Without model modification, CPE achieves the best task success across multiple settings using prompt refinement alone. Our findings identify communication behavior as a critical yet underexplored design dimension for LLM agents.
Retrospective Progress-Aware Self-Refinement for LLM Agent Training
Jun 12, 2026LLM-based agents trained with reinforcement learning optimize step-wise action prediction but lack metacognitive awareness of task progress, inducing a gap that hinders long-horizon scaling. A pilot study reveals that online progress prompting hurts performance while retrospective demonstrations help, yet this capability cannot emerge from outcome-reward training alone. We present RePro, Retrospective Progress-Aware Training, a framework that trains agents to self-generate progress signals via a forward-then-reflect rollout paradigm: the agent executes actions online, then retrospectively reassesses its step-wise progress given the completed trajectory and known outcome. RePro initializes with a Retrospection Warmup that teaches reflection format from minimal external demonstrations, then further trains through RePro-PO with a composite reward that produces self-generated signals without continuous external supervision. Experiments on WebShop, ALFWorld, and Sokoban show that RePro enhances the Qwen family's performance, with up to $12\%$ absolute success rate gains.
Plan-MCTS: Plan Exploration for Action Exploitation in Web Navigation
Feb 15, 2026Large Language Models (LLMs) have empowered autonomous agents to handle complex web navigation tasks. While recent studies integrate tree search to enhance long-horizon reasoning, applying these algorithms in web navigation faces two critical challenges: sparse valid paths that lead to inefficient exploration, and a noisy context that dilutes accurate state perception. To address this, we introduce Plan-MCTS, a framework that reformulates web navigation by shifting exploration to a semantic Plan Space. By decoupling strategic planning from execution grounding, it transforms sparse action space into a Dense Plan Tree for efficient exploration, and distills noisy contexts into an Abstracted Semantic History for precise state awareness. To ensure efficiency and robustness, Plan-MCTS incorporates a Dual-Gating Reward to strictly validate both physical executability and strategic alignment and Structural Refinement for on-policy repair of failed subplans. Extensive experiments on WebArena demonstrate that Plan-MCTS achieves state-of-the-art performance, surpassing current approaches with higher task effectiveness and search efficiency.
Adaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
Agent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning
Jan 08, 2026Large Language Model (LLM)-based agents significantly extend the utility of LLMs by interacting with dynamic environments. However, enabling agents to continually learn new tasks without catastrophic forgetting remains a critical challenge, known as the stability-plasticity dilemma. In this work, we argue that this dilemma fundamentally arises from the failure to explicitly distinguish between common knowledge shared across tasks and conflicting knowledge introduced by task-specific interference. To address this, we propose Agent-Dice, a parameter fusion framework based on directional consensus evaluation. Concretely, Agent-Dice disentangles knowledge updates through a two-stage process: geometric consensus filtering to prune conflicting gradients, and curvature-based importance weighting to amplify shared semantics. We provide a rigorous theoretical analysis that establishes the validity of the proposed fusion scheme and offers insight into the origins of the stability-plasticity dilemma. Extensive experiments on GUI agents and tool-use agent domains demonstrate that Agent-Dice exhibits outstanding continual learning performance with minimal computational overhead and parameter updates. The codes are available at https://github.com/Wuzheng02/Agent-Dice.
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Quick on the Uptake: Eliciting Implicit Intents from Human Demonstrations for Personalized Mobile-Use Agents
Aug 12, 2025


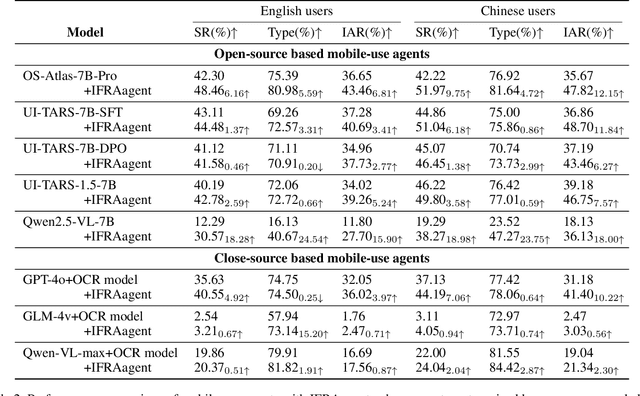
As multimodal large language models advance rapidly, the automation of mobile tasks has become increasingly feasible through the use of mobile-use agents that mimic human interactions from graphical user interface. To further enhance mobile-use agents, previous studies employ demonstration learning to improve mobile-use agents from human demonstrations. However, these methods focus solely on the explicit intention flows of humans (e.g., step sequences) while neglecting implicit intention flows (e.g., personal preferences), which makes it difficult to construct personalized mobile-use agents. In this work, to evaluate the \textbf{I}ntention \textbf{A}lignment \textbf{R}ate between mobile-use agents and humans, we first collect \textbf{MobileIAR}, a dataset containing human-intent-aligned actions and ground-truth actions. This enables a comprehensive assessment of the agents' understanding of human intent. Then we propose \textbf{IFRAgent}, a framework built upon \textbf{I}ntention \textbf{F}low \textbf{R}ecognition from human demonstrations. IFRAgent analyzes explicit intention flows from human demonstrations to construct a query-level vector library of standard operating procedures (SOP), and analyzes implicit intention flows to build a user-level habit repository. IFRAgent then leverages a SOP extractor combined with retrieval-augmented generation and a query rewriter to generate personalized query and SOP from a raw ambiguous query, enhancing the alignment between mobile-use agents and human intent. Experimental results demonstrate that IFRAgent outperforms baselines by an average of 6.79\% (32.06\% relative improvement) in human intention alignment rate and improves step completion rates by an average of 5.30\% (26.34\% relative improvement). The codes are available at https://github.com/MadeAgents/Quick-on-the-Uptake.
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025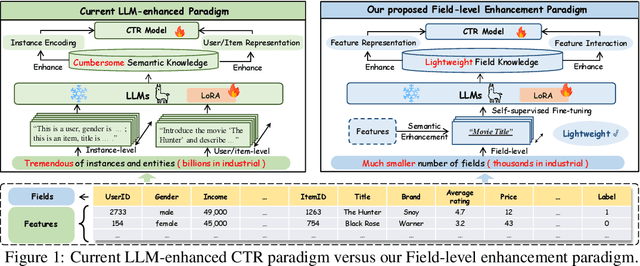
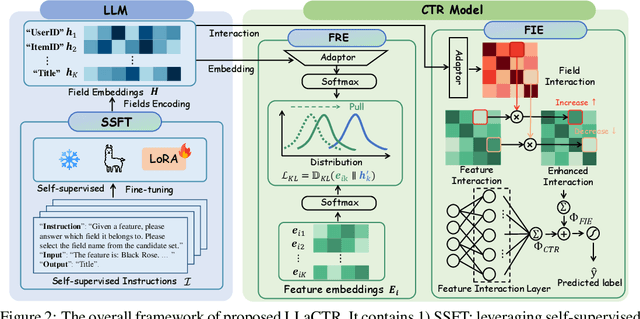
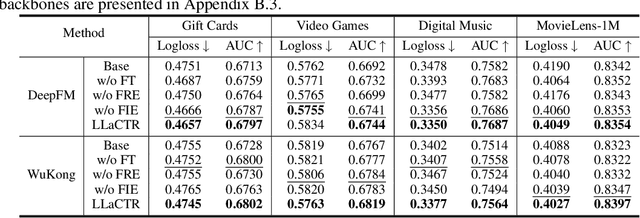

Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
MSL: Not All Tokens Are What You Need for Tuning LLM as a Recommender
Apr 05, 2025Large language models (LLMs), known for their comprehension capabilities and extensive knowledge, have been increasingly applied to recommendation systems (RS). Given the fundamental gap between the mechanism of LLMs and the requirement of RS, researchers have focused on fine-tuning LLMs with recommendation-specific data to enhance their performance. Language Modeling Loss (LML), originally designed for language generation tasks, is commonly adopted. However, we identify two critical limitations of LML: 1) it exhibits significant divergence from the recommendation objective; 2) it erroneously treats all fictitious item descriptions as negative samples, introducing misleading training signals. To address these limitations, we propose a novel Masked Softmax Loss (MSL) tailored for fine-tuning LLMs on recommendation. MSL improves LML by identifying and masking invalid tokens that could lead to fictitious item descriptions during loss computation. This strategy can effectively avoid the interference from erroneous negative signals and ensure well alignment with the recommendation objective supported by theoretical guarantees. During implementation, we identify a potential challenge related to gradient vanishing of MSL. To overcome this, we further introduce the temperature coefficient and propose an Adaptive Temperature Strategy (ATS) that adaptively adjusts the temperature without requiring extensive hyperparameter tuning. Extensive experiments conducted on four public datasets further validate the effectiveness of MSL, achieving an average improvement of 42.24% in NDCG@10. The code is available at https://github.com/WANGBohaO-jpg/MSL.